
An Extension of Social Network Group Decision-Making Based on TrustRank and Personas
- DOI
- 10.2991/ijcis.d.200310.001How to use a DOI?
- Keywords
- Social network; PageRank; TrustRank; Persona; Social network group decision-making (SN-GDM)
- Abstract
With the development of social networking big data, social network group decision-making (SN-GDM) has been widely applied in many fields. This paper focuses on three main components: (1) the determination of the decision makers' (DMs) weights based on different social influence; (2) the anti-deception mechanism; and (3) the persona method. We introduce the TrustRank algorithm and the persona method into SN-GDM. Based on the TrustRank algorithm, both trusted and deceptive DMs in a seed set are artificially identified and given initial static scores to derive the influence of each DM. Additionally, the persona method is introduced to cluster DMs and achieve personalized decision-making. Further, we present a numerical example and comparison to demonstrate the efficiency of the framework in coping with non-socially shared preferences in SN-GDM. As expected, our findings indicate that our framework reduces the influence of deceptive DMs on the decision results.
- Copyright
- © 2020 The Authors. Published by Atlantis Press SARL.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
Social network group decision-making (SN-GDM) is a useful tool for dealing with complex problems involving multiple decision makers (DMs), in which a group of DMs interact with each other and express their preferences regarding a set of alternatives. Because even DMs in the same social network can have different influences [1], it is important to derive the weight of each DM in SN-GDM.
Over the past two decades, ubiquitous search engines have ranked web pages based on the importance of links, clicks, and content [2]. It should be noted that there is trust propagation in SN-GDM [3–5], which is similar to link-based algorithms for ranking web pages such as PageRank. Page et al. [6] of Stanford University invented the PageRank algorithm based on the link relationship between web pages in 1998. This algorithm can not only compute the importance of web pages, but also be applied in the systems analysis of bibliometrics [7–9] and road networks [10–12] as well as social network analysis [13–15]. To identify the influence of microblogs users and solve the recommendation problem, some researchers have extended the notion of PageRank. Weng et al. proposed a TwitterRank algorithm that considers topic similarity and link structure between users to measure the social influence of Twitter users [16]. Similarly, Chen and Feng [17] used both the link structure between user pages and the user interaction to measure the user influence. In SN-GDM, we can also derive the weight of DMs by analyzing the trust relationships (similar to the links between web pages) among DMs.
According to the interpersonal deception theory in group decision-making (GDM) [18,19], deceivers may resort to a variety of strategies to manipulate the decision results, such as negative reviews or low scoring. Moreover, similar problems such as web spam pages can hinder web information retrieval. Fortunately, these problems can be solved by an extension of PageRank—TrustRank. Researchers at Stanford University and Yahoo! have created a new link analysis technique, TrustRank, in a joint study [20]. The algorithm uses artificial identification of high-quality pages (called “seed set”), which links a page with a high TrustRank value, with the farther away from the page from the “seed” page, the lower the TrustRank value. This algorithm overcomes the difficulty of interfering ranking in a short time and improves the quality of recommendation. Shen and Liu [21] proposed a novel ranking algorithm for Twitter, anti-TrustRank with relationship strength (ATRS), which propagates anti-trust scores to penalize users for linking to spammers. By utilizing both the good and bad seeds, Zhang et al. [22] created the trust–distrust rank algorithm by propagating differential trust/distrust to combat spam. Nevertheless, both user and item-based algorithms are unable to effectively solve the cold-start problems. Zou et al. [23] applied user–user similarity to TrustRank recommendation, which is more suitable for systems with a large number of users. SN-GDM is not only about social network analysis, but also about the psychological behavior of experts [24,25]. Liu et al. proposed a dynamic weight punishment mechanism for overconfident DMs, thus effectively improving consensus [26]. By using TrustRank, we can reduce the impact of deception in SN-GDM.
The consensus reaching process (CRP) is a key part of GDM, which aims to reach a mutual agreement in the group before making a decision [27,28]. In decision problems involving a large number of DMs, CRP is becoming harder and more challenging [29]. However, CRP is not suitable for all situations. For example, some people prefer to watch action movies, while others like to watch romance and comedy. Thus, a result based on global preference may not satisfy everyone, which makes the conventional CPR ineffective. Fortunately, with the development of big data technologies, the consumers' behavioral data on the Internet can be easily collected and stored. Then, by analyzing the users' demographics, behaviors, social networks, psychological characteristics, hobbies, and other attributes, the persona method has become the basis for the companies to develop marketing strategies. As for the problem of “ignoring the individual differences between users regarding recommendations,” the persona method is applied to personalized recommendations [30,31]. Therefore, the persona method can incorporate the new concept of personalized recommendations into SN-GDM.
This paper proposes a novel framework to simulate the interactive process of GDM with social relationships in the social network. Based on PageRank and TrustRank algorithms, we calculate the weights of DMs in different personas groups to derive personalized decision-making results. Also, the TrustRank algorithm is beneficial to weaken the adverse effects of deceptive DMs. The remainder of this paper is organized as follows. Section 2 introduces the preliminaries of social networks, PageRank, TrustRank, and the persona method. In Section 3, we present a novel framework of SN-GDM, which determines the DMs' weight by using TrustRank and the clustering process based on the DMs' personas. In Section 4, a numerical example will help us to illustrate the feasibility of the proposed method. In Section 5, we present our conclusions.
2. PRELIMINARIES
Before introducing the SN-GDM framework constructed in this study, it is necessary to introduce social networks, PageRank and TrustRank algorithm, and the persona method.
2.1. Social Networks
The British anthropologist R. Brown was the first to propose the concept of a social network. His research focused on the influence of culture on the behavior of members of bounded groups [32]. According to Wellman [33], a social network is a sum of the social relations among individuals, and is regarded as a relatively stable system. Individuals or groups such as families, departments, and organizations can be part of the social network. With the development of web technology, the social network concept has been applied beyond the scope of interpersonal relationships. Social relationships in social network media such as Facebook and Twitter are a reflection of social networks in real life. In general, social network media can be divided into the following three types:
Friends-based social networks: In such social networks, the establishment of a friend relationship needs to be confirmed by both parties. Therefore, the relationship in these social networks is bidirectional and stable. The common examples are QQ, WeChat, Facebook, and so on, which can be represented by an undirected graph.
Following-based social networks: Users in such social networks can follow other users without their permission. Therefore, its user relationship is unidirectional and weak. The common examples are Weibo, Twitter, and so on, which can be represented by a directed graph. Unless otherwise stated, the social networks discussed in this paper fall into this category.
Community-based social networks: Different from the former two types, users in such social networks do not have an explicit social relationship, which may be established due to temporary needs. Typical examples include the QQ group, WeChat group, Douban group, and so on.
The first type of social media represents the majority. In such social networks, although the relationship between users is relatively stable, it limits the scope of the users' social contact, making them unable to receive information from a broader range. With the development of web technology and the ever-increasing need for social networking, the other two types of social networks emerged, with the weak relationship between users enabling them to both obtain more valuable information and protect their privacy. This study aims at exploring following-based social networks. In general, the reason people follow others in social media is to get information from them, which is often based on trust. Therefore, we set the hypothesis that people trust others before they follow them in the social network.
2.2. PageRank and TrustRank
Social networks, PageRank, and TrustRank have in common that they can all be explained by graph theory. According to graph theory, a graph consists of a set
The web graph can be represented by the transition matrix T [20]:
PageRank algorithm was initially proposed for sorting the importance of web pages in the Google search engine [6]. The algorithm expresses the link relationship between web pages as a directed graph, in which the nodes denote web pages, the directed edges indicate the link relationships between web pages.
The link relationship of a page will affect its PageRank value. A page will equally distribute its PageRank value to all the pages linked to it. The more times the page is linked, the higher the PageRank value.
Page
The following matrix equation is equivalent to Equation (2) [20]:
In general, the PageRank value of some page
Note that the initial static values of all pages in PageRank are equal. However, biased PageRank assigns a different static score to each page. The matrix equation of biased PageRank is as follows [20]:
In recent years, TrustRank has attracted much attention as a link-based ranking algorithm. It's a counter-measure of Google's interference ranking, which can improve the performance of the search engine. Based on PageRank, TrustRank uses a semi-automated approach to distinguish between spam and high-quality pages, relying on experts' evaluation of the TrustRank value of the seed set. Once the “Seed” page is identified, we give these pages the highest initial TrustRank value. The TrustRank values for pages linked to these “seeds” are decremented. For some reason, a good page will inevitably link to some spam pages. However, the closer the distance from the first page, the higher the TrustRank value passed. The further the link distance from the first page is, the lower the TrustRank value is, and the more likely it is to become a spam. With TrustRank, we can compute the TrustRank values for all pages. This algorithm greatly increases the difficulty of ranking short-term operations and quickly improves the quality of search results. More details about TrustRank will be discussed in Section 3.1.
2.3. The Persona Method
The persona method is a uniquely powerful tool for interaction design, which first proposed by Alan Cooper [34]. According to Cooper's definition, personas are not actual users, but hypothetical prototypes of users to represent them throughout the design process [34]. Lene Nielsen [35] points out that instead of looking at the entire person, the persona method uses the focus area as a lens that reflects the relevant attitude and the specific context associated with it. The persona method has been applied in many fields, such as medical treatment [36], education [37], social media [38], and so on.
In general, the persona method extracts the label variable of user based on the user's social attributes, habits, and consumption behavior to process the user information structurally. The building process of the persona method is as follows:
Data collection:
The first step is to collect the user's static and dynamic data. The basic attributes such as the user's name, gender, age, region, and mobile phone number are relatively stable and can be classified as static data. Moreover, the searching, browsing, clicking, and other operations recorded in the visit logs of websites belong to the user's dynamic data. With the rapid development of big data technologies, we can also use web crawling technology to obtain the user's behavior information such as comments, interests, and the number of fans, as well as specific social relationships, which can make the construction of persona more accurate.
Extract label variable:
To build a persona, we must train the collected data to extract label variables. This step should focus on the high probability events, estimating the user's behavior and preferences, and excluding his/her accidental behavior as much as possible through the mathematical algorithm model. Typical methods include machine learning, text mining, natural language processing, clustering algorithms, prediction algorithms, and so on.
Build personas:
The key to building personas is to obtain information about the users through labels such as the basic attributes, behavioral characteristics, purchasing power, hobbies, social network relationships, and so on. Combining all these label variables, we can then construct the persona. The label variables facilitate the computer processing of human-related information, with both semantic and short text features.
Building personas aim to understand the users and predict their needs, which will help to fully understand the user's different features in e-commerce, advertising, and other industries. However, even a well-designed persona cannot adequately describe a user exactly, but only infinitely closer to reality. Therefore, a persona is not an absolute technical method, as it must be modified based on the changes in the user's behavioral data while seeking new labels to make the persona more accurate.
3. SN-GDM BASED ON THE TRUSTRANK ALGORITHM AND THE PERSONA METHOD
This section is based on the link relationships among users in social networks. First, we propose an influence measurement method based on the TrustRank algorithm. Then, we establish a novel framework of SN-GDM that considers the DMs' social influence and personas.
3.1. Deriving the Influence of DMs Based on the TrustRank Algorithm
The interaction relation in SN-GDM is similar to the link-based analysis, with the PageRank algorithm being a free traversal of the graph and the final Rank value being obtained after multiple iterations. The following and follower relations in the social network is just like inlinks and outlinks in a web graph.
Step 1: Select a seed set
Trust can be propagated through predetermined trusted users. It is necessary to find out which users are following many other users. Therefore, we calculate the inverse PageRank value to select seed users. According to the TrustRank algorithm, the inverse transition matrix U is defined as follows [20]:
Note that the inverse transition matrix
We can determine the seed set by the inverse PageRank algorithm [20]:
Different from conventional PageRank algorithms, the inverse PageRank value is determined by the outlinks of web pages instead of their inlinks [20].
Step 2: Identity good users from the seed set
After identifying the seed set with high inverse PageRank value by Equation (6), we should find good users in the seed set and give them the highest static Rank value (namely 1). After normalization, the static score distribution vector
Step 3: Compute the TrustRank value for the DMs based on the identification of trusted DMs
In this step, we employ a biased PageRank algorithm to compute the TrustRank values
3.2. Clustering Based on the DMs' Personas
Step 1: Understand users
Effective persona must be based on a good understanding of the target user. User data can be collected through market research or other means.
Step 2: Extract label variables
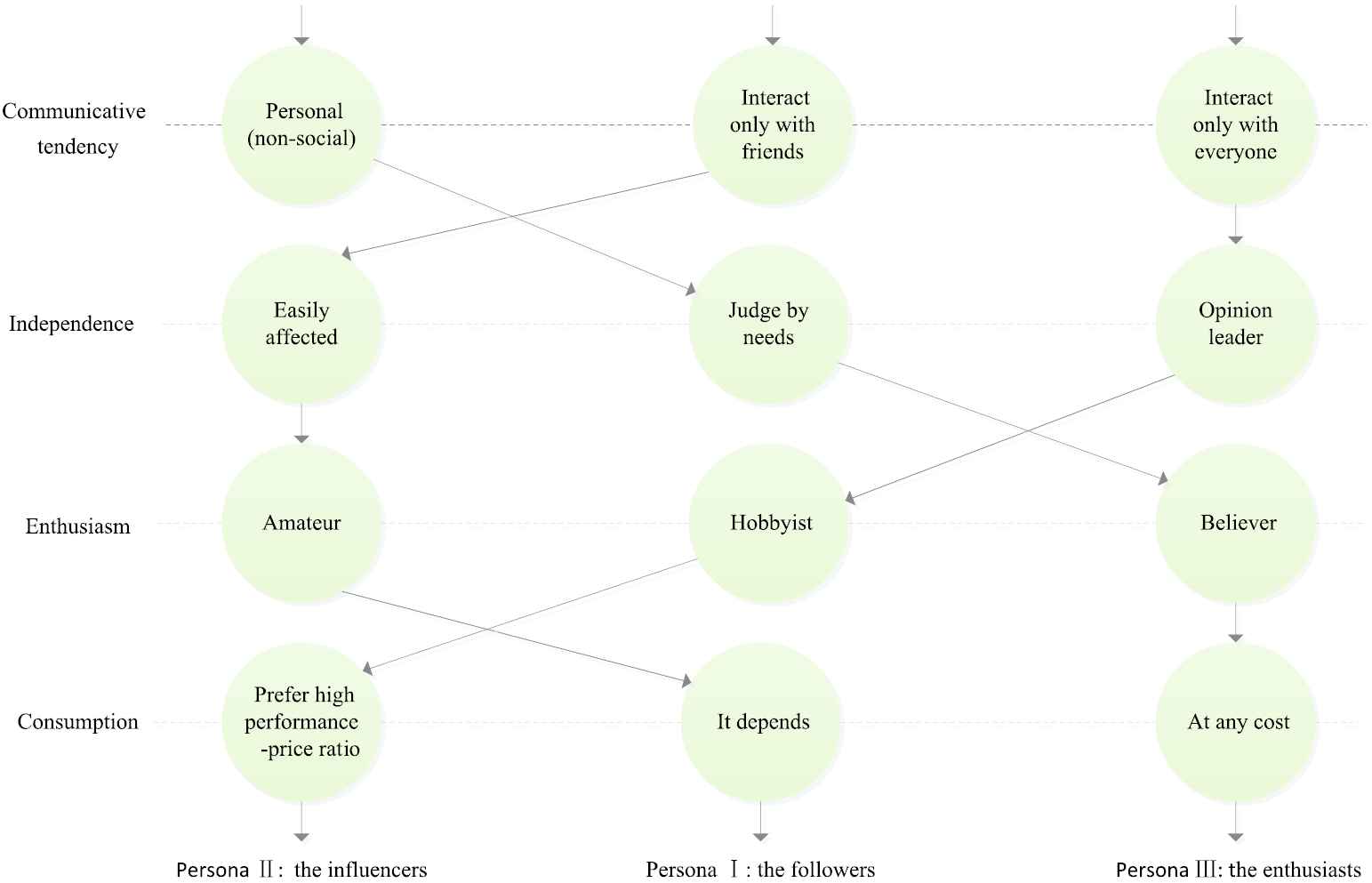
An effective persona must be multidimensional and believable [39]. The label variable is the core factor that causes the difference between users in their behavior regarding a target product or service. Each user has many label variables such as gender, age, preference, and so on. We need to identify what label variables can make a difference in the users' behavior, as shown in Figure 1.
Label variables.
Step 3: Clustering
The persona method encapsulates the information of the potential users of the designed product or service to integrate a virtual representation of the user with typical characteristics [39]. By concatenating the label variables on each dimension, we can derive different personas (see Figure 2), even if fictional. In this step, the most powerful tool is social intuitions and empathies.
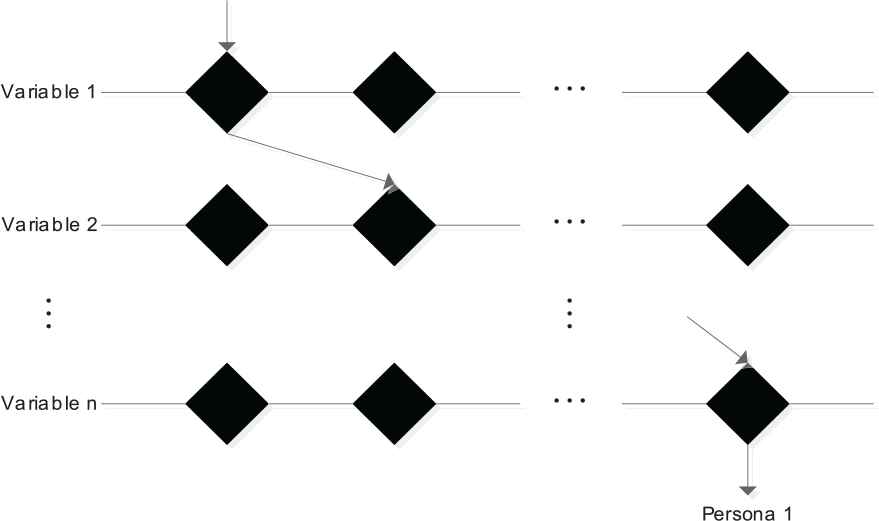
Clustering process.
3.3. SN-GDM Framework Based on the Persona Method and the TrustRank Algorithm
With artificial identification of the seed set, the TrustRank algorithm measures the DMs' influence in the social network. Then, the persona method considers the difference between users. The detailed steps and flow chart of the framework are given below (see Figure 3):
Collect the user's data, including the social relationship between users and behavioral data.
According to the data collected in the first step, the link relationships between the users are analyzed, and the label variables are extracted from the behavioral data.
The TrustRank values of the users are calculated according to the link relationship. Simultaneously, the label data is clustered to divide the users into groups with different personas.
Normalize the users' TrustRank values in different groups to derive their weights. Then, compute the alternatives' scores according to the scoring data by weighted arithmetic mean.
Rank the alternatives and obtain personalized decision-making results.
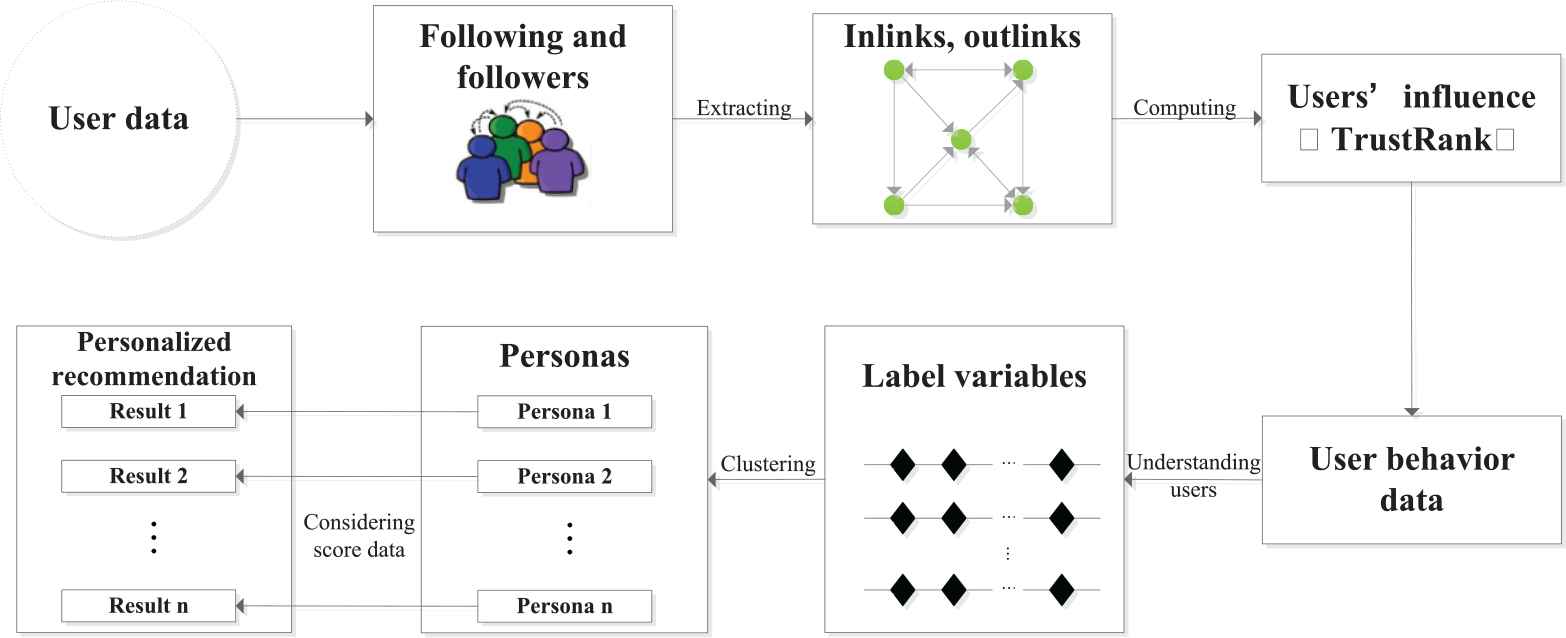
General framework of the persona-based SN-GDM.
4. NUMERICAL EXAMPLE
4.1. Background
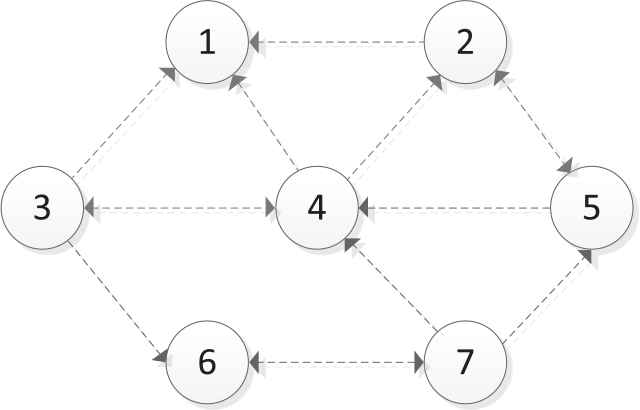
Assuming that there are seven DMs with the following relationship in a movie recommendation, we simulate the inlinks and outlinks with following-based relations among DMs, as shown in Figure 4.

Social network diagram.
This study selects communicative tendency, independence, enthusiasm, and consumption as label variables affecting the DMs' movie consumption behavior (see Table 1).
| CommunicativeTendency | Independence | Enthusiasm | Consumption |
|---|---|---|---|
| Personal (non-social) | Easily affected | Amateur | Prefer high performance–price ratio |
| Interact only with friends | Judge by needs | Hobbyist | It depends |
| Interact with everyone | Opinion leader | Believer | At any cost |
Label variables of the DMs' personas.
The communicative tendency label variables are divided into “personal (non-social),” “interact only with friends,” and “interact with everyone.” The independence label variables are divided into “easily affected,” “judge by needs,” and “opinion leader.” The enthusiasm label variables are divided into “amateur,” “hobbyist,” and “believer.” The consumption label variables are divided into “prefer high performance–price ration,” “it depends,” and “at any cost.” According to the survey, the DMs' label data of these seven DMs are shown in Table 2.
| Communicative Tendency | Independence | Enthusiasm | Consumption | |
|---|---|---|---|---|
| 1 | Interact only with friends | Easily affected | Amateur | It depends |
| 2 | Interact with everyone | Opinion leader | Hobbyist | Prefer high performance–price ratio |
| 3 | Personal (non-social) | Judge by needs | Believer | At any cost |
| 4 | Interact with everyone | Opinion leader | Hobbyist | Prefer high performance–price ratio |
| 5 | Interact only with friends | Easily affected | Amateur | It depends |
| 6 | Personal (non-social) | Judge by needs | Believer | At any cost |
| 7 | Interact only with friends | Easily affected | Amateur | It depends |
Label data of seven DMs.
The scoring of the seven DMs for the three movies are shown in Table 3.
| A | B | C | |
|---|---|---|---|
| 1 | 2.5 | 2.3 | 9 |
| 2 | 8.8 | 9 | 7 |
| 3 | 5.1 | 5.8 | 7.8 |
| 4 | 5.2 | 6.2 | 3.5 |
| 5 | 8 | 7.5 | 3.9 |
| 6 | 4.1 | 4.9 | 6.8 |
| 7 | 7.4 | 6 | 6.1 |
The movie scores.
4.2. Decision Process
4.2.1. Determining the DMs' TrustRank values
Step 1: Select the seed set
We use the inverse PageRank algorithm to find out DMs that may be cheating. The inverse links relationship diagram is shown in Figure 5. According to Equation (6), for
The inverse PageRank.
We select the three nodes with the highest inverse PageRank values to get the seed set
Step 2: Identify the trusted and deceptive DMs from the seed set
Through artificial identification, we determine that 2 and 4 are trusted DMs, whereas 1 is a deceptive DM, as shown in Figure 6. It should be noted that the seed set is identified artificially, and, to some extent, subjectively.
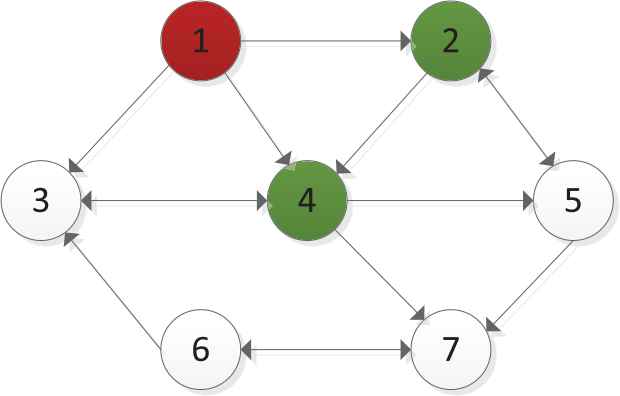
Identification of the seed set.
The normalized static score distribution vector
Step 3: Compute the TrustRank values based on the identification of trusted DMs
For
Then, they are normalized to obtain each DM's weight as
4.2.2. Clustering
By concatenating the label variables on each dimension (see Figure 7), we derive three different personas as follows:
DMs 1, 5, and 7 belong to the Persona type I, namely, the followers. Such DMs are greatly influenced by friends when they choose movies.
DMs 2 and 4 belong to the Persona type II, namely, the influencers. Such DMs feature great sociability and often play the role of opinion leaders in their respective social networks. Additionally, they are more passionate about movies, can identify good movies, and are good at writing various types of movie reviews. Moreover, they consider cost-effectiveness when consuming.
DMs 3 and 6 belong to the Persona type III, namely, the enthusiasts. These people don't need to socialize at all when watching a movie. They will watch the movies they like at any cost.
Personas' clustering process.
4.2.3. Normalizing according to the personas group
To obtain the weights, we normalize the DMs' PageRank and TrustRank values according to their personas classification (see Table 4)
| Persona I | 1 | 5 | 7 | Persona II | 2 | 4 | Persona III | 3 | 6 |
|---|---|---|---|---|---|---|---|---|---|
| PageRank | 0.061 | 0.322 | 0.617 | PageRank | 0.268 | 0.732 | PageRank | 0.460 | 0.540 |
| TrustRank | 0 | 0.393 | 0.607 | TrustRank | 0.340 | 0.660 | TrustRank | 0.461 | 0.539 |
Normalized weights by persona classification.
4.2.4. Calculating the scores
The scores based on the three persona types for the three movies (A, B, and C) are derived according to Tables 3 and 4 by computing the weighted average, as shown in Table 5. The global scores are also included.
| Global scores | A | B | C |
|---|---|---|---|
| PageRank | 5.954 | 6.098 | 5.885 |
| TrustRank | 6.242 | 6.413 | 5.645 |
| A | B | C | |
| PageRank | 7.295 | 6.257 | 5.569 |
| TrustRank | 7.636 | 6.590 | 5.235 |
| A | B | C | |
| PageRank | 6.164 | 6.950 | 4.438 |
| TrustRank | 6.422 | 7.151 | 4.688 |
| A | B | C | |
| PageRank | 4.560 | 5.314 | 7.260 |
| TrustRank | 4.561 | 5.314 | 7.261 |
The results of global scores and three groups of different personas.
4.3. Comparison and Analysis
The TrustRank algorithm can reduce the interference of deceptions. There is a deceptive DM 1 in the global group and the group of persona I. His TrustRank value and weight is reduced to zero. His low scoring for movies A, B and high scoring for C will not be taken into account in the decision process. Thus, the score of movies A and B increased, whereas that of C decreased in the TrustRank group (see Figure 8(a) and (b)). In Figure 8(c), there is no predetermined deceptive DM in persona type II. There are no predetermined trusted or deceptive DMs in the group of persona type III. The weight of DM 3 and DM 6 have not changed much, also the scores of three movies (see Figure 8(d)).
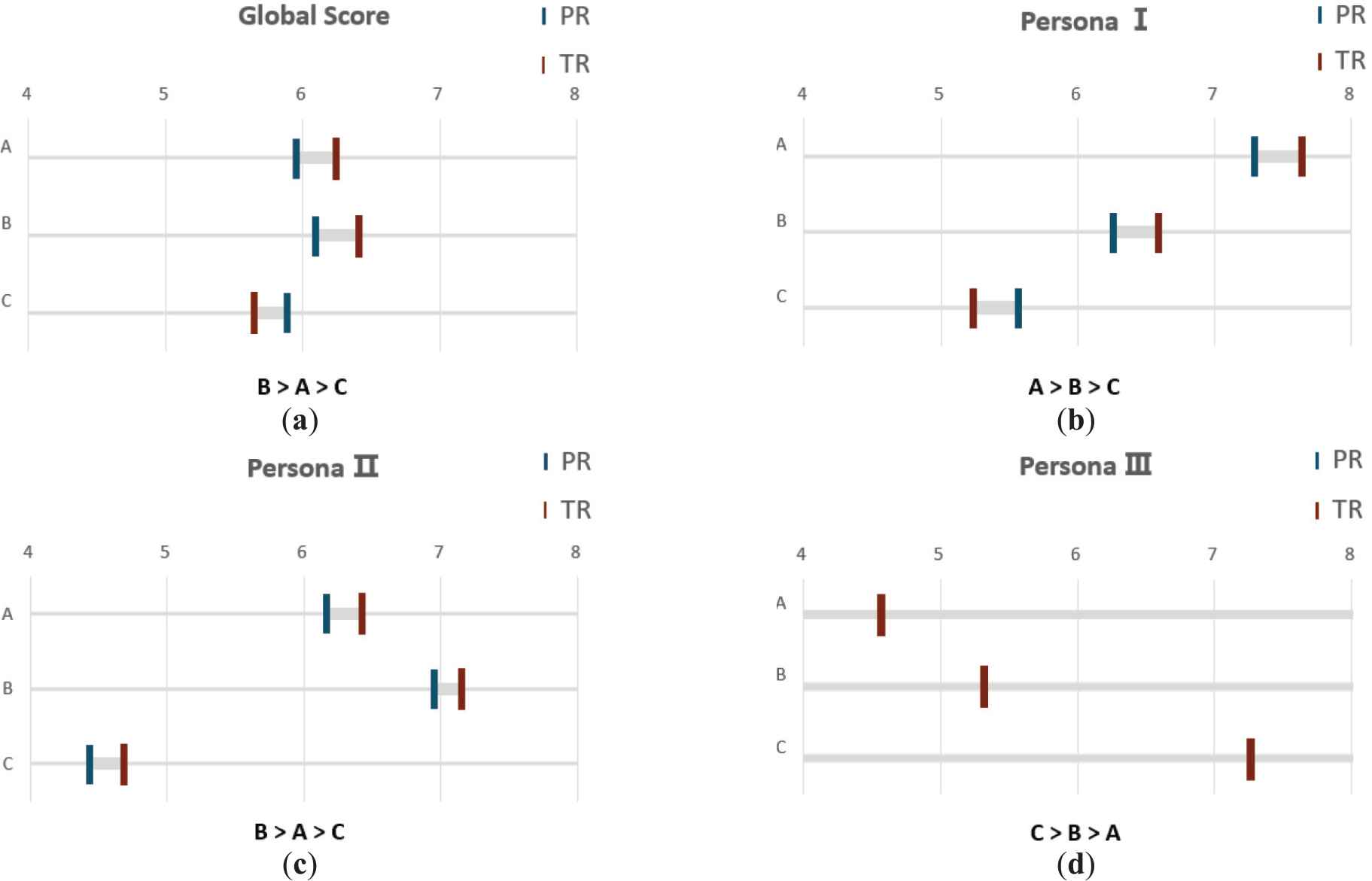
Score visualization of the four scenarios: (a) the score visualization of the global group; (b) the score visualization of persona I; (c) the score visualization of persona II; and (d) the score visualization of persona II (Note that the results of these two algorithms are the same in this scenario).
The application of the personas' method helps achieve personalized decision-making, as DMs are not all alike. For both the global group and persona type II, the preference order for the three movies is B>A>C. However, the preference order of persona type I is A>B>C, while that of persona type III is C>B>A.
5. CONCLUSION
The measurement of DMs' influence is a critical part of SN-GDM. Many researchers focus on deriving the single preference aggregation ranking, without considering the case of non-socially shared preference. In addition, many decision-making processes today are data-driven. To solve the above problems and achieve personalized decision-making, we present a persona-based framework of SN-GDM by collecting DMs' social relationships and label variables from social media. We identify the seed set by applying the inverse PageRank algorithm and then artificially select trusted and deceptive DMs in the seed set. Then, we calculate the TrustRank values of the DMs based on the identification of trusted DMs. Meanwhile, due to the different characteristics of DMs, we extract the label variables from behavioral data and then cluster them into different personas. Besides, we normalize the TrustRank values for the DMs' groups classified by personas to derive their weights, and aggregate the score of each alternative. Moreover, we divide seven DMs into three groups with different personas. Further, the numerical example verify the efficiency of our method. Our study adopts a new approach by applying the TrustRank algorithm and concludes that it can combat deceptive DMs in SN-GDM.
Nevertheless, our study has some limitations that should be addressed. Although our SN-GDM framework can derive the weight of each DM, it cannot reflect the social interactions, such as the synergy and redundancy effect, directly. Also, the scalability of our method has to be developed by incorporating the dynamic data to consider changes in the social relationships and preferences of DMs.
CONFLICT OF INTEREST
This section is to certify that we have no potential conflict of interest.
This article does not contain any studies with human participants or animals performed by any of the authors.
AUTHORS' CONTRIBUTIONS
Mei Cai is responsible for the Conceptualization, Methodology. Yiming Wang is responsible for the Calculation, Software, Validation, Visualization, and Writing of the original manuscript. Zaiwu Gong is responsible for the Review, Editing, and Supervision of the original manuscript.
ACKNOWLEDGMENTS
This research was funded by National Natural Science Foundation of China (NSFC) (71871121, 71401078), Top-notch Academic Programs Project of Jiangsu High Education Institutions.
Footnotes
By using Gephi and Python 3.6.
REFERENCES
Cite this article
TY - JOUR AU - Mei Cai AU - Yiming Wang AU - Zaiwu Gong PY - 2020 DA - 2020/03/17 TI - An Extension of Social Network Group Decision-Making Based on TrustRank and Personas JO - International Journal of Computational Intelligence Systems SP - 332 EP - 340 VL - 13 IS - 1 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.200310.001 DO - 10.2991/ijcis.d.200310.001 ID - Cai2020 ER -