
Blur2Sharp: A GAN-Based Model for Document Image Deblurring
 , Mohamed Ben Halima2, Tarek M. Hamdani2, Javier Nogueras-Iso3, , Adel M. Alimi2, 4
, Mohamed Ben Halima2, Tarek M. Hamdani2, Javier Nogueras-Iso3, , Adel M. Alimi2, 4- DOI
- 10.2991/ijcis.d.210407.001How to use a DOI?
- Keywords
- Generative adversarial network (GAN); Cycle-consistent generative adversarial network (CycleGAN); Document deblurring; Blind deconvolution; Motion blur; Out-of-focus blur
- Abstract
The advances in mobile technology and portable cameras have facilitated enormously the acquisition of text images. However, the blur caused by camera shake or out-of-focus problems may affect the quality of acquired images and their use as input for optical character recognition (OCR) or other types of document processing. This work proposes an end-to-end model for document deblurring using cycle-consistent adversarial networks. The main novelty of this work is to achieve blind document deblurring, i.e., deblurring without knowledge of the blur kernel. Our method, named “Blur2Sharp CycleGAN,” generates a sharp image from a blurry one and shows how cycle-consistent generative adversarial networks (CycleGAN) can be used in document deblurring. Using only a blurred image as input, we try to generate the sharp image. Thus, no information about the blur kernel is required. In the evaluation part, we use peak signal to noise ratio (PSNR) and structural similarity index (SSIM) to compare the deblurring images. The experiments demonstrate a clear improvement in visual quality with respect to the state-of-the-art using a dataset of text images.
- Copyright
- © 2021 The Authors. Published by Atlantis Press B.V.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
Thanks to mobile technology we are able to capture documents in a simple way and at any moment. Text documents such as bank documents, advertisements, courier receipts, hand-written notes, digitized receipts, public information signboards, and information panels captured by portable cameras are very common in our daily lives. Portable cameras offer great conveniences for acquiring and memorizing information as they provide a new alternative for document acquisition in less constrained imaging environments than personal scanners. However, due to the variations in the imaging conditions as well as the target document type, there are many factors that can degrade the images such as image blurring, sharing distortions, geometrical warping, or noise pollution. Frequently, the motion blur caused by camera shake and the out-of-focus blur can affect the quality of the images obtained by mobile devices. Although blur may be not very relevant at first sight, it may be the cause of problems in ulterior processing tasks such as text segmentation or optical character recognition (OCR). Thus, traditional scanner-based OCR systems cannot be directly applied on camera-captured images and a new level of processing needs to be addressed.
The objective of this work is to study a new model for removing different types of blur from real blurry document images and generate the correspondent sharp images. Figure 1 illustrates the difference between source blur images (right) and sharp images (right).
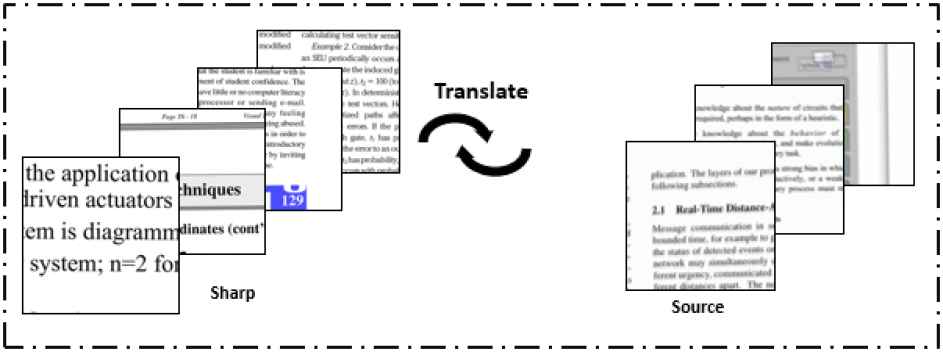
Examples of real source images with blur (right) and sharp images (left).
Various deblurring techniques have been proposed so far based on blur kernel estimation: blind deconvolution methods and nonblind deconvolution methods. In nonblind deconvolution methods, we have some knowledge about the blur kernel. In contrast, in blind deconvolution methods no information about the blur kernel is known. Blind deblurring estimates a latent sharp image and a kernel blur, namely point spread function (PSF), from a blurred image. This problem has been deeply studied (see Section 2). However, generic methods have not been effective with real world blurred images.
The proposal of this work is to eliminate blur and restore blurred images that are captured by low-cost camera devices without the best conditions. For this purpose, we propose to extend a cycle-consistent generative adversarial network (CycleGAN) for translating a blurred input text image into a sharp one. Recent methods based on generative adversarial networks (GAN) for tasks such as image-to-image translation [1] depend on the availability of training examples where the same data is available in both domains. However, CycleGAN [2] is able to learn such pair information without one-to-one mapping between training data in source and target domains. The challenge of this work is to propose a new architecture based on CycleGAN, which we call “Blur2Sharp CycleGAN,” for the task of text document deblurring. Blur2Sharp CycleGAN adjusts the parameters of CycleGAN that best fit the purpose of document deblurring.
The rest of this work is organized as follows. Section 2 reviews the state-of-the-art in blind deconvolution methods. Section 3 describes our suggested system. The evaluation and experimental results are provided in section 4. Finally, section 5 provides some concluding remarks.
2. STATE-OF-THE-ART
Given its wide range of applications, document image deblurring has attracted considerable attention in recent years, and various approaches have been proposed, overall in the field of blind deconvolution methods.
In blind deconvolution methods, the first task is to estimate the blur kernel. After this, the second part of the method is to restore the final latent image thanks to a nonblind deblurring algorithm. With the assumption that the blur is uniform and spatially invariant, the mathematical formulation of the blurry image can be modeled as
Chen et al. [3] suggested an effective document image deblurring algorithm based on a Bayesian method that analyzes the local structure of a document image and uses an intensity probability density function as prior for deblurring. However, it is not generally applicable to blurred text images because it depends on text segmentation. Cho et al. [4] proposed another Bayesian method that takes into account more specific properties of text documents. Pan et al. [5] proposed another approach for text de-blurring that makes profit of L0 regularized intensity and gradient priors. Nayef et al. [6] suggested a method for document image deblurring that uses sparse representations improved by nonlocal means. Zhang et al. [7] used a gradient histogram preservation strategy for document image deblurring.
More recently, Ljubenovic et al. [8] proposed the use of a dictionary-based prior for class-adapted blind deblurring of document images. Using a large set of motion blurred images with the associated ground-truth blur kernels, Pan et al. [9] proposed a method to learn data fitting functions. Last, Jiang et al. [10] proposed a method based on the two-tone prior for text image deblurring.
Convolutional neural networks (CNNs) have been also applied to various image enhancement tasks [11,12]. Focusing on text image deblurring, Hradiš et al. [13] proposed an end-to-end method to generate sharp images from blurred ones using CNN. Their network, consisting of 15 convolutional layers, is trained on 3 classes (blur, sharp image and kernel blur), but there are some disadvantages: on the one hand, pairwise images are required to train the networks; on the other hand, the result of deblur-ring is not appropriate for natural images which have a color background. Pan et al. [14] presented a genetic approach with two main ideas: modify the prior to assume that the dark channel of natural images is sparse instead of zero, and impose the sparsity for kernel estimation. They used CNN to predict the blur kernel.
In the past few years, generative adversarial networks (GANs) have been used in different image-related applications [15] such as generating synthetic data, style transfer, super-resolution, denoising, deblurring or text-to-image generation. For instance, Lee et al. [16] used GAN for progressive semantic face deblurring to reduce the motion blur on input face images. Guo et al. [17] proposed a GAN-based method for video deblurring with the objective to improve visual object tracking. More related to document deblurring, Xu et al. [18] proposed a method for jointly deblurring and super-resolving face and text images that are typically degraded by out-of-focus blur. Nimisha et al. [19] also used GAN for end-to-end deblurring network: using adversarial loss, the network learns a strong prior on the clean image domain and it maps the blurred image to its clean equivalent one. Inspired also on GAN architectures, Lu et al. [20] presented an unsupervised method for domain-specific single-image deblurring that tries to disentangle the content features and the blur features in blurred images.
In summary, the previous approaches cannot be generalized to deal with different scenarios in text document deblurring. Therefore, it is a challenging task to count on a method based on deep learning for building a general image prior that is able to handle different scenarios.
3. PROPOSED METHOD
Image deblurring aims to restore a clean image from a blurred one. As mentioned in the introduction, this work explores the feasibility of applying CycleGAN [2] with a new architecture for the challenging task of cleaning blurred text images. We want to demonstrate that CycleGAN approach is suitable for the simpler task of text image deblurring where the results are good. Our idea is that if we can treat blur and sharpness as a kind of image style, successful image deblurring may be achieved with unpaired image dataset based on CycleGAN.
The main advantage of CycleGAN is that it does not require a pairwise image dataset. To solve the issue of not having a ground-truth document of every input, CycleGAN proposes a reverse mapping function Gy. If a generator function Gx translates a document from domain X to domain Y just changing the appearance, it should be possible to map the image back to domain X with another generator function Gy and reconstruct the initial image: X
Figure 3 shows the training process of our proposed Blur2Sharp CycleGAN. It consists of two generators and two discriminators. The main goal of generators is to learn the mapping between two image domains. In addition, the two adversarial discriminators aim to distinguish between images and translated images in the same way as they aim to discriminate between the sharp images and the generated images. The following subsections explain the details of the generative and discriminator networks.
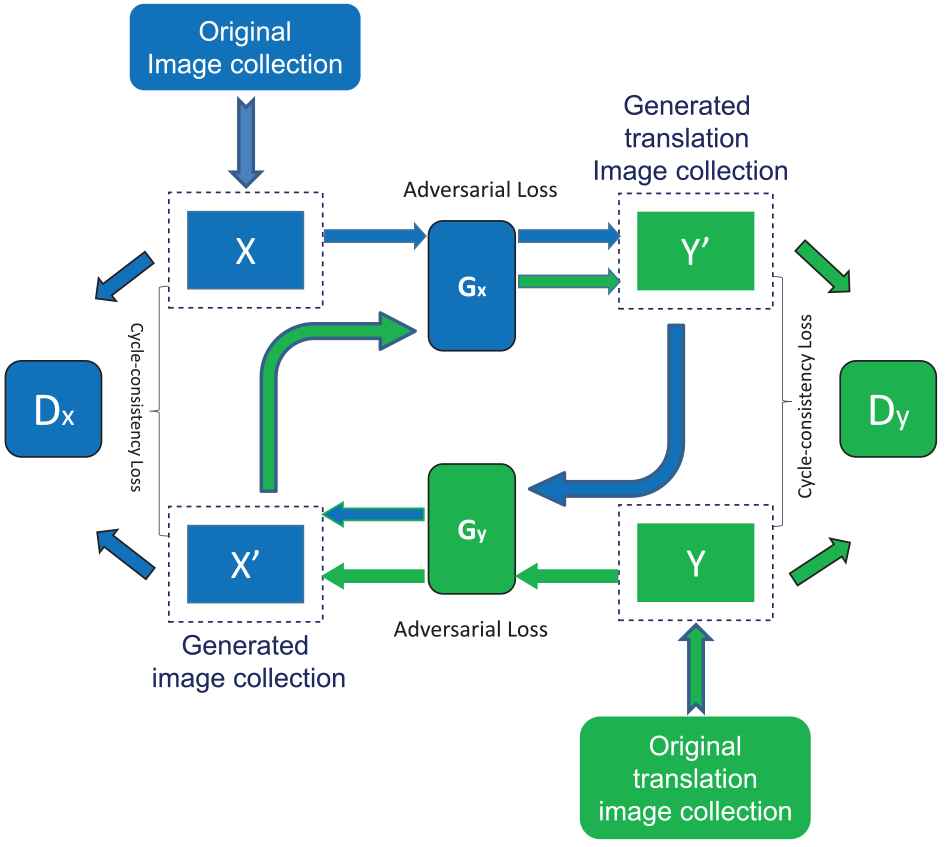
Cycle-consistent generative adversarial network (CycleGAN) approach.
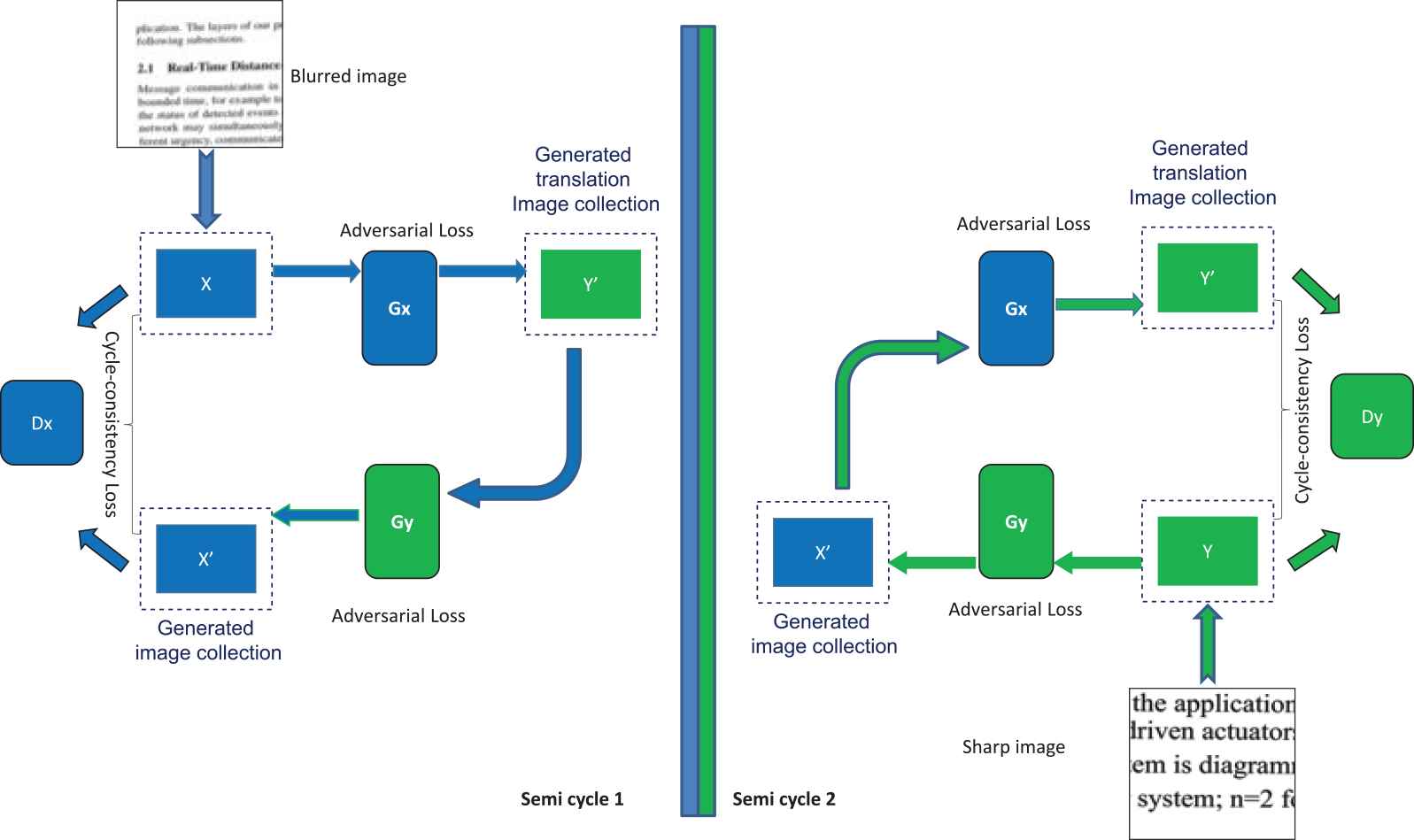
Training process for document image deblurring.
3.1. Generative Network
As shown in Figure 4, both generators consist of three parts: an encoder, a transformer and a decoder. This figure summarizes the architecture of these three parts, which has shown good performance for image deblurring.
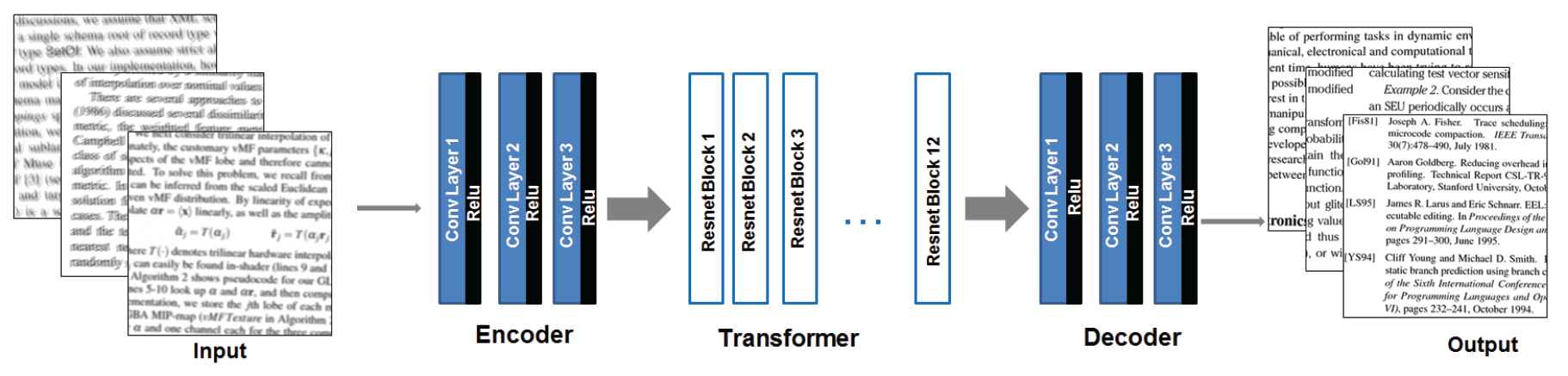
Our architecture for the two generator networks.
Encoder The input of the network is [256, 256, 3]. There are 3 layers to extract the features from an image by one stride each time. In the first layer each filter is 7 × 7 and the stride is 1 × 1. The activation function is ReLU. The shape of the output is [256, 256, 64] (by padding). Then, the output of the first layer is passed to the following layers. The hyper-parameters of the second layer are: 128 filters where each filter is 3 × 3 with stride 2; the activation function is ReLU; and the output is [128, 128, 128]. The hyperparameters of the third layer are: 256 filters where each filter is 3 × 3 with stride 2; the activation function is ReLU; and the output is [64, 64, 256].
Transformer The transformer aims to transform feature vectors of an image from one domain to another domain. The input is [64, 64, 256]. We started building our model from scratch. We started with 9 layers of ResNet blocks. However, as we did not obtain good results, we tried to change the model structure to improve the result. After testing different possibilities, we chose the hyperparameters and structures that best suited for the deblurring task. We have used 12 layers of ResNet blocks. All filters have 3 × 3 size, and the stride is 1. Therefore, the output of our model transformer is [64, 64, 256].
Decoder The decoding works in the opposite way to the encoder. We reconstruct the image from the feature vectors by applying three deconvolution layers which use the reversed parameters of the encoding step. Therefore, the output of our model decoder is [256, 256, 3].
3.2. Discriminative Network
The main goal of the discriminator is to extract features. It contains 5 convolutional layers. The hyperparameters of all the layers are the following: the total filters are [64, 128, 256, 5, 1]; the stride is [2, 2, 2, 2, 1]; and the activation function is LeakyReLU (slope = 0.2) for all the layers except for the last layer with LeastSquareGAN. All the filters have 4 × 4 size. The principal role of discriminator is to decide whether these features belong to one particular category or not by the last layer, which is a convolutional layer with output 1 × 1.
3.3. Loss Function
There are two components of the CycleGAN objective function: an adversarial loss and a cycle consistency loss. Both are essential to obtaining good results. We train the models using Least Square GAN loss. To achieve our goal, the loss function must satisfy that the discriminator X should be trained for images as close as possible to domain X, and fake images close to 0. Thus, discriminator X would minimize (DiscriminatorX(x) − 1)2. In the same way, it should be able to distinguish original and generated images. The discriminator must return 0 for images generated by the generator X. Discriminator X would minimize (DiscriminatorX(GeneratorY
On the other hand, generator X should be able to deceive discriminator Y about the authenticity of its generated images. This can be done if the recommendation by discriminator Y for the generated images is as close to 1 as possible. Therefore, generator X would like to minimize (DiscriminatorY(GeneratorX
4. EXPERIMENTS
The following subsections describe the experiments that have been performed using the proposed “Blur2Sharp CycleGAN” method: the corpus of documents for training and testing together with the implementation details (see Section 4.1), and the results that have been obtained (see Section 4.2).
4.1. Datasets and Implementation
With respect to the unpaired dataset used for the experiments, we are using the dataset proposed by Hradiš et al. [13]. It consists of images with both defocus blur (using an uniform anti-aliased disc) and motion blur (generated by a random walk). We randomly cropped 2000 blurred image patches with 256 × 256 size and 2001 cleaned image patches with 256 × 256 size from the dataset for training.
For the testing phase, depicted in Figure 5, we used the test dataset proposed by Hradiš et al. [13], which includes 100 pairs of images (blurred images and their corresponding sharp versions) to evaluate the quality of image restoration.
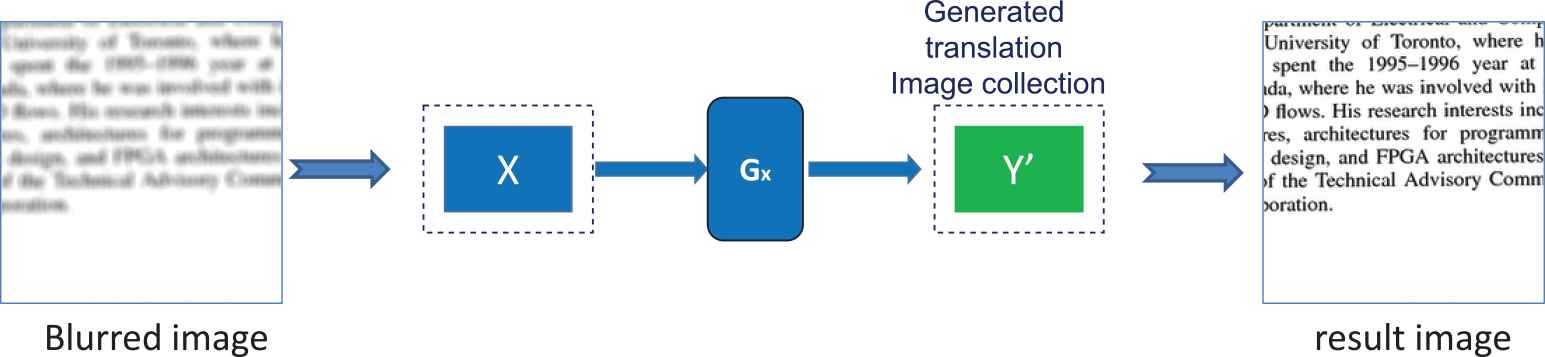
Testing process.
We have implemented our Blur2Sharp Cycle-GAN on document deblurring in Python with the help of Keras and running the code on top of Google Tensorflow framework. In addition, it must be noted that all the computation works were run on an Ubuntu server with NVIDIA Quadro P6000 GPUs.
4.2. Results
Figure 6 shows two examples of the application of our “Blur2Sharp CycleGAN” method on the test dataset. Although the visual result of sharp images seems satisfactory, it is difficult to distinguish visually a real image from a synthetic one when the differences between them are small. Therefore, we have compared quantitatively our method using two metrics: structural similarity index (SSIM) and peak signal to noise ratio (PSNR).

Blur2Sharp cycle-consistent generative adversarial network (CycleGAN). From left to right: image blurred photo, result of Blur2Sharp CycleGAN.
The computation of SSIM is shown in Eq. (1) including the following symbols: I is the structural similarity index; (x, y) are coordinates indicating a nearby NxN window; σx, σy, are the variances of intensities in x, y directions; σxy is the covariance; and μx, μy are the average intensities in x, y directions.
Eq. (2) shows the formula for computing PSNR, where MSE stands for the Mean Square Error, Iori is the original image, and Ideblur is the deblurred image. MSE is computed according to Eq. (3), where m, n is the size of the image.
Based on the two metrics defined above, we have compared the results obtained with our proposed Blur2Sharp CycleGAN architecture and the state-of-the-art methods using the test dataset previously described in Section 4.1: the 100 images extracted from the dataset proposed by Hradiš et al. [13]. The results are shown in Table 1. Our PSNR is equal to 32.52db and according to SSIM, we achieve 0.7689 on average using CycleGAN. Therefore, we can conclude that our “Blur2Sharp CycleGAN” has achieved a comparable SSIM and PSNR with the advantage of not having to use pairwise images for the training phase.
| PSNR | SSIM | |
|---|---|---|
| Pan et al. [5] | 32.24 | 0.6627 |
| Hradiš et al. [13] | 33.40 | 0.9076 |
| Pan et al. [14] | 32.59 | 0.6708 |
| Xu et al. [18] | 20.12 | 0.8970 |
| Blur2Sharp CycleGAN | 32.52 | 0.7689 |
Quantitative comparison with state-of-the-art methods on the proposed image deblurring dataset.
In addition, the results are good in terms of visual comparison with respect to the state-of-the-art. For instance, Figure 7 compares the results obtained with different methods on an input image that belongs to the text image deblurring dataset proposed by Hradiš et al. [13]. It can be observed that our Blur2Sharp CycleGAN method generates a sharp image with much clearer characters.

Example of the outputs obtained after applying different deblurring methods.
Finally, we have also compared the quality of the text obtained after applying an OCR algorithm on the output images generated by the different deblur-ring methods. After applying Tesseract software [21] to obtain OCR from the sharp images in the test dataset (used as reference text) and the images returned by the methods, we have computed the average cosine similarity between the character frequency vectors derived from each pair of corresponding OCR output files. We have considered only the detection of letters and digits within the range of printable characters in ASCII encoding. In this comparison we have also included the OCR obtained directly from blurred images to verify that deblurring is beneficial for OCR. As shown in Table 2, our method performs better than the methods of Pan et al. [5,14] and a bit worse than the method of Hradiš et al. [13]. It is logical that the method of Hradiš et al. performs better because it is a nonblind deconvolution method. It must also be noticed that the obtained OCR is not perfect, even for the sharp images in the testing dataset, because we are using cropped images with incomplete words and lines.
5. CONCLUSIONS
We presented a novel model that uses cycle-consistent adversarial networks for document deblurring. Our proposed “Blur2Sharp CycleGAN” architecture adjusts CycleGAN to the task of text image deblurring. We can both deblur images and blur sharp images because CycleGan has the property of cycle-consistency. It is worth noting that since we use unpaired images as training dataset, we do not need the ground-truth sharp images. Based on our prior knowledge, successful image deblurring can be achieved with an unpaired image dataset using Cy-cleGAN.
In addition, it must be noted that our model for image document deblurring obtains comparable results with respect to the current state-of-the-art. Moreover, the obtained PSNR values are at the same level as the best methods found in the research literature. This demonstrates that the idea of treating blur and sharpness as a kind of image style actually works. In addition, a by-product of generating fake blurring images using CycleGAN is also provided. Last, it must be noted that our model significantly improved the speed of the deblurring process thanks to GPU acceleration.
As future work we want to test the feasibility of “Blur2Sharp CycleGAN” as part of a more general task of historical document enhancement. Historical documents (and their digitized versions) suffer from several types of degradation that affect their readability and the application of OCR or text analysis processes. Apart from the noise originated by the bad conditions of original documents (e.g., stains or bad condition of paper), during the scanning (digitization) of pages from a bound book, the curving of the part of the page close to the “spine” introduces not only gutter shadows, but also out-of-focus blur in the shade area. Our aim is to verify whether “Blur2Sharp CycleGAN” can help to remove this kind of blur in this domain context.
CONFLICTS OF INTEREST
The authors declare of no conflicts of interest.
AUTHORS' CONTRIBUTIONS
All authors have contributed to the design of the proposal for document image deblurring. Hala Neji has had the leading role in the implementation and execution of experiments. All authors have contributed to the edition of the manuscript.
ACKNOWLEDGMENTS
The research leading to these results has been partially supported by the Ministry of Higher Education and Scientific Research of Tunisia under the grant agreement number LR11ES48 and the Regional Government of Aragon (Spain, project T59 20R). In addition, we gratefully acknowledge the support of NVIDIA Corporation with the donation of the Quadro P6000 GPU used for this research.
REFERENCES
Cite this article
TY - JOUR AU - Hala Neji AU - Mohamed Ben Halima AU - Tarek M. Hamdani AU - Javier Nogueras-Iso AU - Adel M. Alimi PY - 2021 DA - 2021/04/13 TI - Blur2Sharp: A GAN-Based Model for Document Image Deblurring JO - International Journal of Computational Intelligence Systems SP - 1315 EP - 1321 VL - 14 IS - 1 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.210407.001 DO - 10.2991/ijcis.d.210407.001 ID - Neji2021 ER -