
SAO Semantic Information Identification for Text Mining
- DOI
- 10.2991/ijcis.2017.10.1.40How to use a DOI?
- Keywords
- Semantic Analysis; Technology Intelligence; Computational Intelligence; Topic Model; Subject-Action-Object
- Abstract
A Subject-Action-Object (SAO) is a triple structure which can be used to both describe topics in detail and explore the relationship between them. SAO analysis has become popular in bibliometrics, however there are two challenges in the identification of SAO structures: low relevance of SAOs to domain topics; and synonyms in SAO. These problems make the identification of SAO greatly dependent upon domain experts, limiting the further usage of SAO and influencing further the mining of SAO characteristics. This paper proposes a parse tree-based SAO identification method that includes (1) a model to identify the core components (candidate terms for subject & object) of SAO structures, where term clumping processes and co-word analysis are involved; (2) a parse tree-based hierarchical SAO extraction model to divide entire SAO structures into a collection of simpler sub-tasks for separate subject, action, and object identification; and (3) an SAO weighting model to rank SAO structures for result selection. The proposed method is applied to publications in the Journal of Scientometrics (SCIM), to identify and rank significant SAO structures. Our experiment results demonstrate the validity and feasibility of the proposed method.
- Copyright
- © 2017, the Authors. Published by Atlantis Press.
- Open Access
- This is an open access article under the CC BY-NC license (http://creativecommons.org/licences/by-nc/4.0/).
1. Introduction
An SAO is a triple structure extracted from a text corpus. Subjects and objects are terms or phrases that are closely related to the topic. Actions are verbs that represent the operation by which, or the relationship between, those terms and phrases. The development of natural language processing techniques has allowed SAO structures to express rich semantic information and gained recognition as a powerful tool for identifying concepts in a corpus.1–3 SAO structure has the ability to transform words into concepts,4 express means-end relationships,5 and also express evolutionary trends of topic.6–8
Compared to co-word analysis, SAOs provide an express way to quickly understand massive textual content. Co-word analysis, also named as co-occurrence analysis, is widely introduced to explore potential relationships between textual elements.9–12 Undoubtedly, compared with simply counts of publications and citations, as described in the definition of modern bibliometrics,13 co-words analysis provide a tool to quickly understand textual content,14 and help indicate significant topics 15 and dynamic changes 16. However, limitations still exist: (1) homonyms and synonyms of words and terms result in ambiguous interpretations, especially in multidisciplinary and interdisciplinary research fields 17, 18; (2) High-frequency, or common, terms fail to discriminate between relevant and irrelevant topics and mislead to unexpected groups 15, 19; and (3) co-occurrence only means two terms that appear at the same time, yet directly identifying the specific and deterministic relationships between them. Undoubtedly, compared to co-word analysis, SAOs provide an express way to quickly understand massive textual content, and help indicate significant topics. SAO is helpful for (1) solving the problem of ambiguous interpretations resulted by homonyms and synonyms of words 17, 18; and (2) identifying the specific relationship between topic terms.20
SAO identification is the basis of SAO analysis. However, it is difficult to identify appropriate SAOs for bibliometric analysis. The problems of traditional SAO identification are: (1) it is difficult to directly extract the SAOs that have a close relationship with a topic of interest. Most of the SAOs identified with general Natural Language Processing are too common to express detailed meanings for “what to do” and “how to do it,” which is the emphasis of “SAO structure” playing an important role in topic analysis. The reason is that there are millions of SAOs and most of them are common words, (e.g., “we look at an example,” “paper consists of three parts.”). These common words are irrelative to topics, stop us from getting truly valuable SAOs, and cannot be filtered out by post-cleaning and consolidation. (2) It is difficult to obtain the SAOs that have perfect quantitative properties and we usually face the problem of “synonyms in SAO”. It is a serious problem for quantitative analysis, especially when we want to use some statistics-based methods (e.g., time series analyses,21 co-occurrence and association analysis). The reason for “synonyms in SAO” is that the SAO structure is complex, which means that there will be literally many different SAO structures that have the same meaning, and it is difficult to combine them together.
Aiming to overcome the problems described above, which is the value of this manuscript, this paper proposes a SAO identification method. Compared with traditional SAO identification methods, the main contributions of the proposed method are: (1) introduce term clumping and design a co-word algorithm (considering the co-occurrence with keywords) to identify SAO core components, which is helpful for improving the relevance of SAOs to topic. (2) Based on syntax-tree, constructed a hierarchical SAO extraction model, and perform the SAO cleaning and consolidation function. It is helpful for improving the “synonyms in SAO”. (3) Constructed an SAO weighting model using the idea of TFIDF (term frequency–inverse document frequency) to evaluate the importance of each SAO. We apply the proposed method to the publications in the Journal of Scientometrics. The results demonstrate the feasibility of our method and hold interest for related bibliometric studies.
The rest of this paper is organized as follows: related works are summarized in a Literature Review, the section 3 presents the SAO identification method followed by an empirical study on SCIM. Finally, we conclude our study and address future work.
2. Literature review
There are usually two kinds of SAO extraction approaches: the symbolic approach and the statistical approach.
2.1. Symbolic SAO extraction approach
A symbolic approach consists of a set of rules, often hand-written but sometimes automatically learned, that model different language phenomena. This approach focuses on the designing of rules and is popular and efficient. The KnowledgistTM2.5 (or GoldFire) is probably the most well-known rule-based SAO extraction tool and has been used in many SAO analyses.5, 6, 22, 23 However, KnowledgistTM2.5 (or Goldfire) is more of a retrieval tool for patent analysts or technical developers, and cannot be easily used in quantitative analysis. It does not support mass SAO extraction. People have to enter search terms, and only the specific SAOs that contain the search terms can be obtained. Some researchers try to design their own rules to extract specific SAOs or variations of SAO (including Resource Description Frameworks (RDF), semantic relation structure). X. Wang et al24 and J. Guo et al25 design a set of SAO extraction rules based on Stanford parse software. G. Cascini et al4 designed a syntactic parser to perform SAO extraction, and then identified the core components of patents based on SAO. T. Jiang et al26 and A. Ben et al27 designed a set of syntactic patterns to identify specific RDFs.
In summary, symbolic approach is unsupervised and does not require a great quantity of manual annotation. The extraction process is fairly intuitive and controllable. One can change a rule or create a new one if, after testing, he sees that something is wrong or missing. However, a symbolic approach is relatively expensive because you need to manually design a lot of rules. The precision may experience huge fluctuations dependent upon the rules.
2.2. Statistical SAO extraction approach
A statistical approach typically uses a mathematic statistical model and machine learning algorithms to learn the language phenomena.28, 29 M. Bundschus et al30 extended the framework of Conditional Random Fields to perform the annotation and extraction of semantic relations, which is the key to SAO identification. J. Punuru, J. H. Chen31 propose an unsupervised technique for extracting SAO from domain texts. A statistical method with log-likelihood ratios is used to estimate the significance of relationships between concepts and to select suitable relation labels. D. Gerber et al32 presented a statistical method in combination with an unsupervised, as well as a supervised, machine learning technique to extract RDF (a variation of SAO) triples from unstructured data streams.
In summary, statistical approach is becoming popular in SAO extraction. This approach can find the inherent law in syntax and filter out the incorrect syntax based on the statistical model. However, there are some limitations: (1) The dependence on Named Entity Recognition.33 It is difficult to identify all kinds of concepts (named entity) in corpora based on Named Entity Recognition, and that makes it impossible to extract all SAO. (2) The statistical approach is a black box; it is less direct and less intuitive when improving the quality of SAO extraction algorithms. (3) Supervised machine learning methods need a lot of manual annotation.
3. Methodology
This paper constructs an SAO identification method that aims to improve the quality (relationship with topic, and synonyms in SAO) of identification results. Figure 1 shows the process: (1) core components of SAO structures are identified from ST&I (Science, Technology & Innovation) records based on a co-word algorithm and term clumping; (2) SAO structures are extracted based on a syntax tree-based hierarchical model; and (3) an SAO weighting model evaluates and ranks the SAO structures for selection.
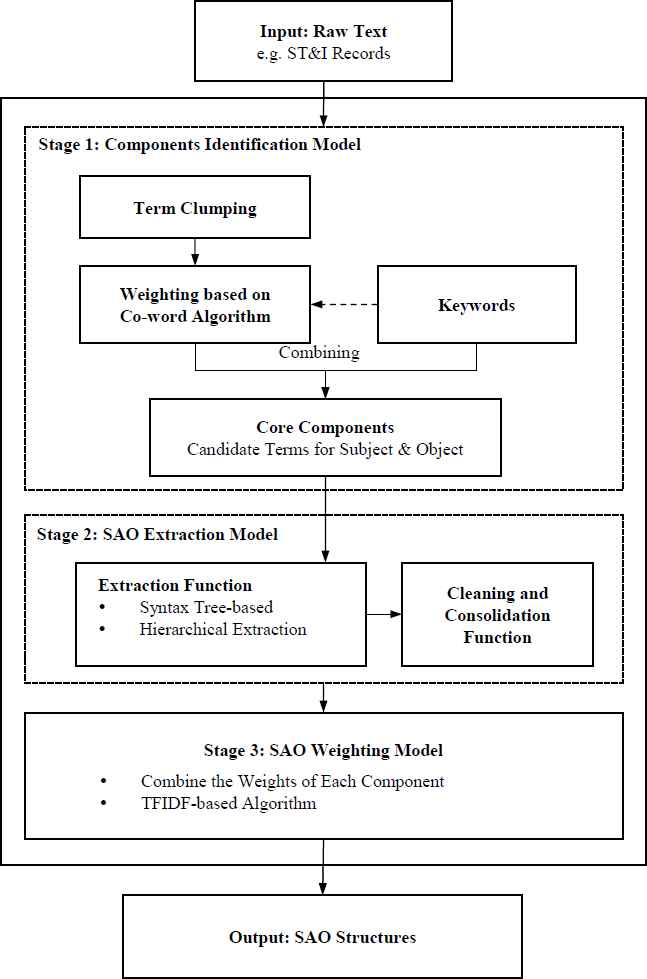
Framework of extracting and ranking SAO
3.1. Components identification model
We introduce term clumping and design a co-word algorithm to perform SAO components identification. SAO components are a set of topic terms that are used as the candidate terms for the subject and object of SAO. There are three steps to identify SAO components: (1) performing term clumping to obtain a set of words/phrases; (2) ranking the term clumping results based on the proposed co-word algorithm; and (3) combining the top N term clumping results with keywords to obtain the core components of SAO. The detailed procedure is shown below:
- (1)
Term clumping
To achieve these components, we introduce term clumping. Term clumping is the series of steps to clean and consolidate rich sets of topical phrases and terms in a collection of documents relating to a topic of interest15. We applied such term clumping steps to our data. The stepwise actions are noted in Table 2. Y. Zhang et al15 shows the detailed description of each step. Term clumping typically results in mostly terms, which are useful for identifying topic terms, but do contain a great deal of noise which doesn’t have a close relationship with topics.34
- (2)
Ranking the term clumping results based on co-word algorithms
To overcome the problem (noise in term clumping results) above, a co-word algorithm is proposed to evaluate and rank the results of term clumping. If a term co-occurs with keywords frequently in many papers, but does not occur so frequently itself in papers (not a common word), then we can conclude that this term is a relatively important word/phrase. This algorithm calculates the degree of importance of terms built on the co-occurrences with keywords and their own occurrence frequency. The detailed description of this algorithm is 1) the algorithm calculates the sum of co-occurrence frequency between term t and every keyword; 2) the algorithm divides the sum of co-occurrence frequency above by the number of instances of term t in papers to produce a weight. This weight is used to evaluate and rank the terms in term clumping results. The algorithm is implemented in Java and GATE, and described as below:
t: Term t derived from term clumping, t ≠ k, t ∈ St.
Wt: The weight of term used to evaluate the importance of term t.
It: Total number of instances of term t in the dataset.
k: Keyword k, k ∈ Sk.
Sk: The set of keywords.
freq(t, k) : Frequency of co-occurrence between term t and keyword k.
The benefit of ranking term clumping results based on the proposed co-word algorithms is that we consider the importance of the terms based on the relevance of terms to keywords. Keywords can show the topic of text35, 36 and is good at forming SAO structures. The terms co-occurring with keywords frequently (rank t in the dataset. highly) usually can be combined with keywords to form a SAO. Compared with TFIDF, the proposed method focus on the co-occurrence of terms and keywords instead of only the occurrence of terms/records, and is helpful for construct SAO structure based on keywords.
- (3)
Combining the top (higher weight) term clumping results with keywords
The keywords in papers are often accurate and clean. In order to cover all the SAOs, the proposed method combines the term clumping results with the keywords.
The terms in term clumping results St is ranked based on Wt, and then are combined with keywords to produce the SAO core components Sc:
St: the set of term clumping results.
Sc: the set of SAO core components.
| Field selection | Number of phrases and terms |
|---|---|
| Phrases with which we begin | 57,205 |
| Basic Term Cleaning—remove common terms | 53,888 |
| Basic Term Cleaning—remove general scientific terms | 52,302 |
| Term Consolidation—fuzzy matching | 44,542 |
| Association Rule-based Consolidation—combine low frequency terms with high frequency terms that frequently appear in the same record | 31,952 |
| Association Rule-based Consolidation—combine terms that share 3 or more words | 27,263 |
| Term Consolidation—fuzzy matching | 26,192 |
| Pruning—remove terms that appear only in one record | 7,569 |
Term clumping stepwise results
At last, we will check the results and remove the common terms manually.
3.2. SAO extraction model
An SAO extraction model is constructed, which is hierarchical and syntax-tree based (shown in Fig. 2 and Fig. 3). The SAO core components (obtained in section 3.1) are imported into this model to assure the subject/object of SAO has a close relationship with the topic. The model is hierarchical and equipped with specialized syntax rules (shown in Table 1) to meet the special extraction requirements which is some different with general SAO extraction (e.g., The desired SAO of “robotics technology holds a significant promise for improving industrial automation” is “robotics technology improves industrial automation” not “robotics technology holds a significant promise”). The proposed hierarchical model solves the extraction work by breaking it down into a collection of different levels of simpler sub works, like the identification of subject, action, and object. The SAO extraction model is implemented in GATE 37 and comprises six steps (shown in Figure 3, and corresponding to a different pseudo code in Figure 2):
- (1)
To reach the desired SAO, we first identify the objects in the sentence (including clauses) based on the syntax tree and the core components acquired in Stage 1. This step corresponds to 1–5 in Figure 2.
- (2)
The action is identified using the object from Step 1. Because actions and objects are built naturally upon each other, a set of rules filters actions and objects in a recursive manner. This step corresponds to 6–8 in Figure 2.
- (3)
Objects and actions are combined to produce a reasonable action-object structure. This step corresponds to 9–14 in Figure 2.
- (4)
Based on the action of the action-object structure (obtained above) and core components, we retrieve the subject of the various level of topic information. This step corresponds to 15 and 16 in Figure 2.
- (5)
The subject is combined with the action-object structure to produce a complete and accurate Subject-Action-Object. This step corresponds to 17–23 in Figure 2. We use the stem of verb and noun to form SAO structures to improve the “synonyms in SAO”.
- (6)
The SAO is cleaned and consolidated using thesaurus and fuzzy matching. First, a stop word list is used to remove common SAOs. Secondly, a thesaurus of synonyms (including verbs and nouns) is constructed to combine similar SAO components (Subjects, Actions and Objects). Finally, we use fuzzy matching to combine similar SAOs. This step is fulfilled with VantagePoint.38 It is useful to improve the “synonyms in SAO”.
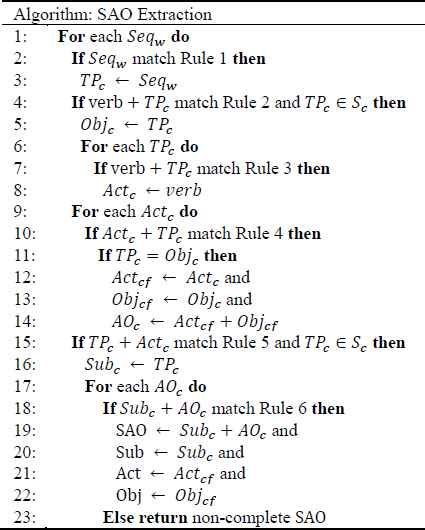
The pseudo code for SAO extraction Model
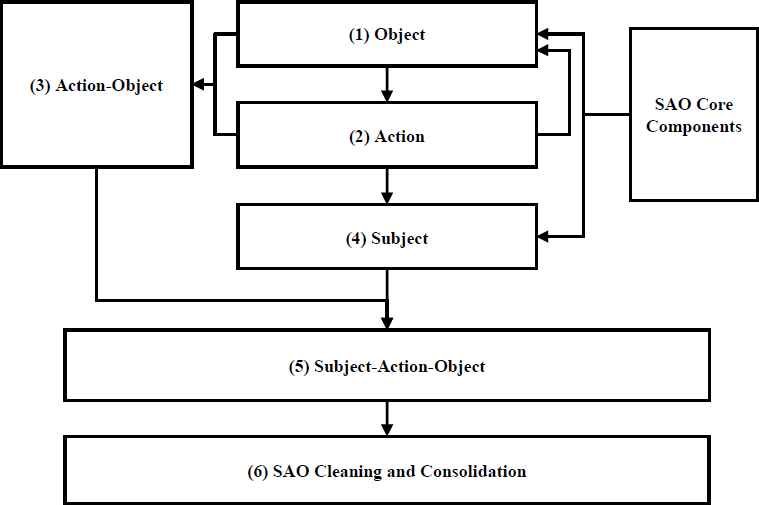
SAO extraction Model
| Rule | Description |
|---|---|
| Rule 1 | Identify TPc, e.g. (JJ|VBN)[0,3]+(N ∩ N. length > 1)[1,m] is an pattern to match TPc. |
| Rule 2 | Identify Objc, e.g. V + (token ∩ token ≠ N ∩ token ≠ punctuations) [0,5] + TPc, if this pattern is matched, TPc is identified as Objc. Rule 2 includes 32 patterns. |
| Rule 3 | Identify Actc, e.g. (VBZ|VBP|VB|VBD|VBG) ∩ (V ≠ “be”) + (token ∩ token ≠ V)[0,5] + TPc, if this pattern is matched, The verb (VBZ|VBP|VB|VBD|VBG) in this pattern is Actc. Rule 3 includes 7 patterns. |
| Rule 4 | Identify AOc, e.g. |
| Rule 5 | Identify Subc, e.g. TPc + (token = “as”)? +MD?+R?+V, if this pattern is matched, TPc is equivalent to Subc. Rule 5 include 22 patterns. |
| Rule 6 | Identify final SAO, e.g. |
Rules mentioned in pseudo code of SAO extraction Model
In Figure 2, COR denotes the corpus that contains all the records; Seqw denotes words sequence ∈ COR; TPc denotes candidate word/phrase; Objc denotes candidate Object; Objcf denotes further candidate Object got by filtering Objc; Actc denotes candidate Action; Actcf denotes further candidate Action that is produced by filtering Actc; AOc denotes candidate Action + Object; Subc denotes candidate Subject; SAO denotes Subject + Action + Object; Sub denotes the final Subject; Act denotes the final Action; Obj denotes the final Object.
The Rule 1–6 embedded in the pseudo code in Figure 2 are a series of judgment conditions (syntax rules) which are used to judge different levels of SAO structure, (e.g., if a string of words fit the pattern “(JJ|VBN)[0,3] + (N ∩ N. length > 1)[1, m]” in Rule 1, then it is identified as candidate word/phrase (TPc); if a TPc satisfy Rule 2, then it is identified as candidate object of SAO (Objc)). Rules 1–6 are syntax tree-based and written in Jape (shown in Table 1).
In Table 1, JJ indicates the adjective. VBN indicates the past participle. N indicates the noun. V indicates the verb. VBZ indicates the 3rd person singular present. VBP indicates the non-3rd person singular present. VB indicates the base form of the verb. VBD indicates the past tense of the verb. VBG indicates the gerund or present participle. MD indicates the modal. R indicates the adverb.
3.3. SAO weighting model
An SAO weighting model is constructed to evaluate the importance of each SAO obtained in section 3.2. This model ranks and identifies important SAOs for subsequent analysis (e.g., topic analysis).
The SAO weighting model is constructed based on the idea of TFIDF. TFIDF reflects the important a term to a document in a corpus based on the frequency of the term and records.39 SAO is a combination of terms and verbs, so we can combine the TFIDF of each component to calculate the weight of SAO. In other words, to calculate the SAO weight, the weighting model calculates the TFIDF of each part (subject, object, action, and SAO as a whole) and combines them together. Subject and Object are the core of SAO and in a similar position. Action can link Subject and Object together, and has great potential to affect the overall weight. Thus, we add the TFIDF of Subject and Object together, and use the weight of Action as a global parameter. Meanwhile, there is another global parameter. We call it the initial weight of SAO, where we treat SAO as a term and calculate the TFIDF of overall SAO (IWSAO). Finally, the weight of the SAO is calculated as follows:
In these formulas, IS denotes instances, or the total number of times the subject appears in the dataset; RS denotes the number of records that contain this subject; RO denotes the total number of instances the object appears in the dataset; RO denotes the number of records that contain that Object; ISAO denotes the total number of instances the SAO appears in the dataset; RSAO denotes the number of records that contain that SAO; N indicates the total number of documents in the dataset. The calculations of WS, WO and IWSAO are based on TFIDF. Take WS or example, log(1+IS) is the logarithmically scaled Subject frequency, and
For the weight of the Action, we find it is different with Subject and Object. The term frequency and document frequency of the Action cannot express its importance. Thus, we first identify important Actions based on the statistics of verbs. Then WA is set via expert knowledge.
4. A case study
We applied the proposed SAO identification method to the publications in the Journal of Scientometrics. Scientometrics is a leading journal in the field of Information Science & Library Science, and provides good balances between theoretical research & empirical studies, and information science & management needs. Such publications, which contain a rich variety of topics with strong features of coupling, would make great sense to be used for our SAO identification and explore insights to compare with the traditional bibliometric techniques (word-based). In light of this, we introduce our method to identify the SAO. In total, 4,215 Scientometrics papers authored between 1978 and 2015 were collected from Web of Science (Search query: SO=Scientometrics, Query Date: 13 08 2015).
4.1. Components identification
This section displays the process of how to obtain the core components of SAO. There are three steps, as described in section 3.1.
The results from the first step—term clumping—are listed in Table 2. These form the basis for core component identification.
In the second step, we applied co-word algorithm mentioned in section 3.1 to rank the results of term clumping. The top 10 is shown as sample in Table 3. The weight Wt of term clumping result terms in Table 3 has been normalized.
| Number | Term clumping result term | Weight |
|---|---|---|
| 1 | hub/authority scores | 0.916667 |
| 2 | high impact articles | 0.861111 |
| 3 | document co-citation network | 0.833333 |
| 4 | environmental engineering | 0.805556 |
| 5 | regional innovation system | 0.75 |
| 6 | international collaboration output | 0.666667 |
| 7 | co-word network | 0.638888889 |
| 8 | country publication share | 0.611111111 |
| 9 | food science | 0.611111111 |
| 10 | economic cooperation | 0.583333333 |
Weighting of term clumping results
Finally, by combing the top 80% of term clumping results (6,055 words/phrases) with keywords set (4,003 words/phrases), we achieved the core components (8,762 words/phrases). There is overlap between term clumping results and keywords, so the number of core components is not the sum of them. We chose the top 80% based on previous experience and experts’ knowledge. With this level, we will not lose the important words/phrases and still filter out the common ones that do not have a close relationship with the topic of interest.
4.2. SAO extraction and SAO weighting
From these core components we obtained 89,713 SAO structures based on the SAO extraction model. These SAOs were cleaned and consolidated via fuzzy matching to produce a final result of 84,241 SAOs. Based on the statistics of verbs and expert knowledge, we obtained 169 core Action words in graphene field, and then WA is set via expert knowledge. Every SAO was evaluated by the SAO weighting model and the top 10 results are shown in Table 4. Weights have been normalized.
| SAO | Subject | Action | Object | SAO weight |
|---|---|---|---|---|
| Factors affect research productivity | Factors | affect | research productivity | 1 |
| Author co-citation analysis discover intellectual structure | Author co-citation analysis | discover | intellectual structure | 0.996136316 |
| Citations contribute impact factor | Citations | contribute | impact factor | 0.975317836 |
| Thomson Reuters compute JIF | Thomson Reuters | compute | JIF | 0.939696411 |
| Methodology identify Frontier Areas | methodology | identify | Frontier Areas | 0.89139095 |
| Academic research focus China | academic research | focus | China | 0.881187012 |
| Factors explain collaboration | Factors | explain | collaboration | 0.84504439 |
| Patents result in international collaboration | Patents | result in | international collaboration | 0.828255483 |
| Aim map intellectual structure | Aim | map | intellectual structure | 0.789898655 |
| cluster analysis reveal scientists | cluster analysis | reveal | scientists | 0.782380707 |
Top 10 SAO (weighted)
Precision and recall is introduced to validate the results and test the reliability. Precision measures the number of correctly identified SAOs as a percentage of the number of SAOs identified. The higher the precision, the better the system is at ensuring that what is identified is correct. Recall measures the number of correctly identified SAOs as a percentage of the total number of correct SAOs. The higher the recall rate, the better the system is at not missing correct SAOs. A random 100 papers was selected to form the test dataset. We annotated the test dataset manually to identify the SAO structures and use it as ‘gold standard’ against which to compare the proposed SAO identification method. Based on the ‘gold standard’, the precision and recall of SAOs in each paper are calculated, and then we calculated the average of the precision and recall. The average of precision is 0.8058, the average of recall is 0.8446.
A network of the SAOs is constructed to show the SAO identification results. The nodes in the network represent Subjects or Objects, and the edges represent Actions between Subjects and Objects (shown as Fig. 4). The size of the node reflects the frequency of the term in the SAO set. The strength of the lines is related to the number of SAOs that contain two nodes together. Given the sheer quantity of data, Fig. 4 displays the SAOs that have a relation with the top 70 keywords.
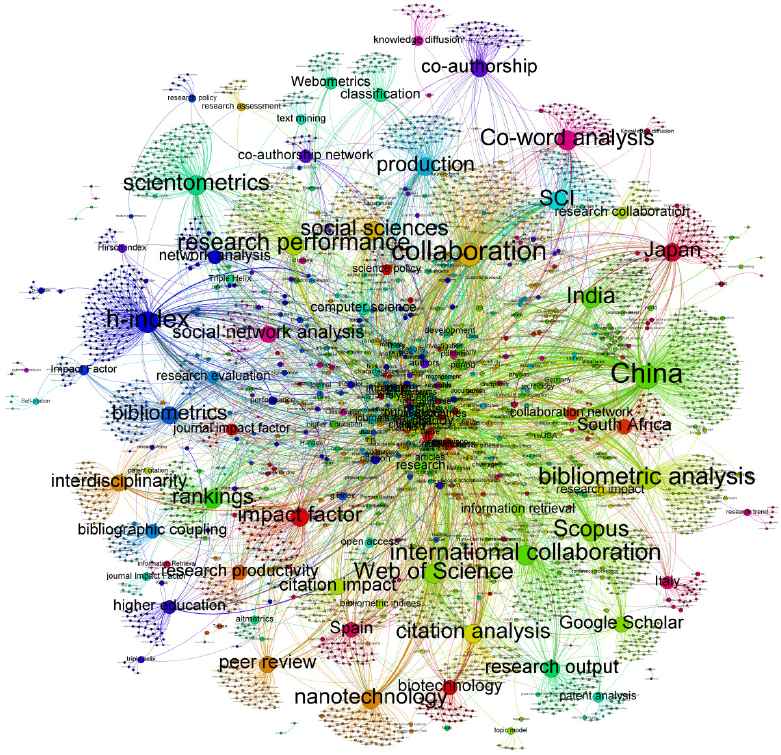
Result of SAO identification
Based on the in-degree and out-degree of nodes, we find that “collaboration” is the most popular topic in Journal of Scientometrics. Other hot topics include co-word analysis, co-authorship analysis, network analysis, h-index, citation analysis, and impact factor. The link between nodes indicates the real relationship between topics. For example, “Co-word analysis map collaboration” is an SAO and indicates that “Co-word analysis” method can be used to “map” the “collaboration” situation.
The proposed method has three advantages:
- (1)
The SAOs identified with the proposed method contains a wealth of semantic information and indicates a specific relationship between topic terms; therefore, each topic is described in detail by a set of weighted SAOs, which show its core content.
- (2)
The SAOs identified with the proposed method have a close relationship with the topics, which makes it very useful for topic analysis.
- (3)
The SAOs identified in the proposed method improve the “synonyms in SAO”, and can be used in quantitative analysis, including: 1) the statistics of the SAO frequency, Subject frequency, Action frequency, Object frequency; 2) building the SAO-SAO matrix, SAO-document matrix, SAO-author matrix, SAO-coutry matrix, SAO-year matrix and SAO-organization matrix, and then implementing co-occurrence analysis; and 3) building the Subject-Action-Object network and implementing SAOs’ network analysis.
5. Discussion and conclusions
Existing SAO research have predominantly focused on applications rather than the SAO extraction techniques. The limitation is that SAO structures cannot fit the application in bibliometric analysis. This paper proposes an SAO identification approach that combines a symbolic and statistical approach.
We find there are two challenges in SAO identification for bibliometrics: low relevance of SAOs to domain topics; and synonyms in SAO. Aiming to solve these two problems, the proposed method introduces a component identification model, a hierarchical SAO extraction model, and an SAO weighting model. With the help of three models, researchers can identify complete and accurate SAO structures. At the same time, The SAOs identified with the proposed method contain a wealth of semantic information and can indicate the relationship between topic terms.
Compared with existing SAO identification methods, the proposed method aims to provide basis for SAO-based bibliometric analysis, focus on the components (Subject, Action, Object) of SAO and the topic relevance. We emphasize on the quantitative SAO analysis.
There are many possible applications for our method: (1) identify topic terms and rank topics in order of popularity and influence; (2) classify topics based on the similarity of relationship; (3) provide in-depth functional descriptions of topics via corresponding SAOs; and (4) explore the relationships between topics based on the action between topic terms.
However, there are also some limitations to this paper. We use traditional fuzzy matching to combine similar SAOs, which is not good at processing long and complex SAO structures. It is better to introduce ontology for combining similar SAOs. We engaged experts for setting indictor thresholds, but a systematic setting process would be able to improve the efficiency of qualitative approaches.
In future research, we will further apply our approaches to various topics and texts to test its robustness. In addition, we will continue to improve the cleaning and consolidation function for combining similar SAOs without affecting their original semantic information. We also see potential in associating SAO-based network analysis with technology roadmapping to analyze topic development trends.
Acknowledgements
We acknowledge support from the General Program of National Natural Science Foundation of China (Grant No. 71373019). This paper was also funded by the International Graduate Exchange Program of Beijing Institute of Technology. The findings and observations contained in this paper are those of the authors and do not necessarily reflect the views of the supporters.
References
Cite this article
TY - JOUR AU - Chao Yang AU - Donghua Zhu AU - Xuefeng Wang PY - 2017 DA - 2017/01/01 TI - SAO Semantic Information Identification for Text Mining JO - International Journal of Computational Intelligence Systems SP - 593 EP - 604 VL - 10 IS - 1 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.2017.10.1.40 DO - 10.2991/ijcis.2017.10.1.40 ID - Yang2017 ER -