
An Evaluation of the Dynamics of Diluted Neural Network
- DOI
- 10.1080/18756891.2016.1256578How to use a DOI?
- Keywords
- diluted neural network; annealed dilution; dynamics; spurious memory
- Abstract
The Monte Carlo adaptation rule has been proposed to design asymmetric neural network. By adjusting the degree of the symmetry of the networks designed by this rule, the spurious memories or unwanted attractors of the networks can be suppressed completely. We have extended this rule to design full-connected neural networks and diluted neural networks. Comparing the dynamics of these two neural networks, the simulation results indicated that the performance of diluted neural network was poorer than the performance of full-connected neural network. As to this point, further research is needed. In this paper, we use the annealed dilution method to design a diluted neural network with fixed degree of dilution. By analyzing the dynamics of the diluted neural network, it is verified that asymmetric full-connected neural network do have significant advantages over the asymmetric diluted neural network.
- Copyright
- © 2016. the authors. Co-published by Atlantis Press and Taylor & Francis
- Open Access
- This is an open access article under the CC BY-NC license (http://creativecommons.org/licences/by-nc/4.0/).
1. Introduction
Spurious memory is a classical problem in neural networks.1,2,3,4,5,6,7,8 A variety of algorithms have been proposed to suppress the spurious memories. These algorithms could decrease the number of spurious memories to some extent, but it is unknown whether the spurious memories would completely disappear by using one of these algorithms. With the development of biology knowledge, we become more and more acquainted with biological neural systems. It has been indicated that asymmetric neural networks can suppress spurious memories.9,10,11,12,13
One of the authors developed a strategy for designing asymmetric neural networks of associative memory with controllable degree of symmetry and controllable basins of attraction.14 The strategy is called Monte Carlo Adaptation (MCA) rule. It is shown that the performance of the networks designed by MCA rule depends on the degree of the symmetry. By adjusting the degree of the symmetry, the spurious memories or unwanted attractors can be suppressed completely. The values of the coupling matrix are set to be two states: the binary numbers ±1. By extending the original MCA rule to design feedback neural networks with discrete weights, the performance of feedback neural networks with single-layer full connection as well as diluted connection synapses have been studied.15 And their storage capacity and global dynamics behaviors were evaluated. The simulated results indicated that the full-connected neural network had better performance than the diluted one.15 This is different from the traditional views, which thought the diluted neural network had better performance than the full-connected neural network.16,17,18
The authors of Ref. 19 designed a new learning algorithm towards self-generating fuzzy neural work. The proposed algorithm was efficient and was able to generate a fuzzy neural network with high accuracy and compact structure. Ref. 20 presented a survey about the development of neural associative memories, and pointed out the importance of sparse coding of associative memory patterns. A series of pipelined decision feedback recurrent neural networks were proposed by Ref. 21–25. The simulations demonstrated these feedback recurrent neural networks with less computational complexity and better convergence rate. The author of Ref. 26 suggested the asymmetric neural network could store more patterns when the dilution and learning processes were performed together. The time order of the learning and dilution processes affects the storage capacity of diluted neural networks. There are three different types of diluted neural networks: dilution after learning, dilution before learning, and dilution during learning. The last one is different from the former two. In the last type of diluted neural network, the dilution process and the learning process are carried out at the same time. When the dilution process occurs, it will consider the stored patterns in the network and select the best broken bonds to have more patterns to be stored. This method is called annealed dilution and will be adopted in this paper.
In our previous work15, we had compared the dynamics of the full-connected neural network and the diluted neural network, but we did not fix the degree of dilution. In other words, the size of the full-connected neural network and the size of the diluted neural network were the same. In order to study the performance of the diluted neural network more deeply, this paper designs a diluted neural network with fixed degree of dilution and compares its dynamics with the full-connected neural network which has the same real links with the diluted one. Meanwhile, this paper analyzes the valid storage ratio, the training time, and the retrieval time of the two types of neural networks, as well as the three phases of diluted neural networks with different degrees of dilution. This paper also applies the two types of neural networks for solving the handwritten digital image problem.
The outline of this paper is the following. Section 2 describes the rule to design asymmetric neural network with binary weighted values, and the rule to design diluted neural network with fixed degree of dilution. Section 3 presents the dynamic behaviors of the designed diluted neural network and the full-connected neural network. Then section 4 introduces the application of the two types of neural networks for solving the handwritten digital image problem. Finally, section 5 concludes this paper.
2. The Design Rule
2.1. The rule to design asymmetric neural network with binary weighted values
The goal of MCA rule is to control attraction basins of the stored patterns, by means of distributing the local fields of the stored patterns. We employ the single-layer feedback neural network, which is given by (1), to introduce this idea.
Suppose εμ is a memory pattern and there are a set of mutations, which will take place on εμ, namely,
2.2. The rule to design diluted neural network with fixed degree of dilution
We extend the original MCA rule to design the diluted neural network with fixed degree of dilution. Note that
- (i)
The first step, for the ith row of J, we find the minimum value of
- (ii)
The second step, for every element in ith row of matrix J, namely, {Jij, j = 1, 2, ···, N, j ≠ i}, we compute
- (iii)
The third step, we randomly select one item j from the set {j1, j2, ···, jm}, if Jij < 0, then Jij = 0; if Jij > 0, then Jij = −1; otherwise Jij = 1. Before doing this, we have fixed the number of nil elements of the coupling matrix J, and make every row have the same number of nil elements. But the location of nil elements is adjusted to maximize the total number of patterns to be stored. Here we adopt the annealed dilution. We suppose every row has (1 − f) * N nil elements. The parameter f (0 ⩽ f ⩽ 1) represents the fraction of nonzero synapses afferent to a neuron. It is used to denote the degree of dilution: f = 1 represents the network is full-connected (no dilution) and f = 0 stands for the disconnected network (extreme dilution).
3. Dynamic Behaviors of the Two Neural Networks
The two neural networks in this paper refer to the full-connected neural network with binary weighted values and the diluted neural network with fixed degree of dilution, respectively. In this section, the results of numerical simulations are discussed and the performances of the two neural networks are illustrated.
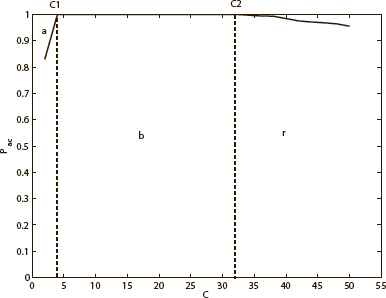
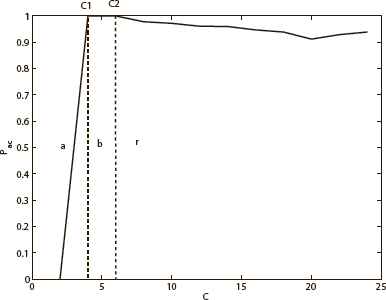
Generally, the MCA rule indicates that there are two transformation points (C1, C2) and three phases in the relational graph of absorptivity Pac and control parameter C in the full-connected neural network. C is a positive constant, being used to control the absolute value of local field. Meanwhile, C determines the size of attraction basin of the stored patterns. Larger values of C imply larger basins of attraction, thus this parameter is called the stability parameter.15 In the region C < C1, Pac = 0, namely, almost no initial state is attracted to the memory patterns. This region is referred as chaos phase. In the region C1 < C < C2, Pac = 1, namely, all the initial states are attracted to memory patterns. It is referred as pure memory phase. In other words, there are no spurious memories at all in this region. In the region C > C2, Pac decreases as C increases, which implies extra attractors besides the memory patterns coexist in this region.
Meanwhile, the storage capability is always the key point when designing neural network. For a neural network with N neurons and P stored patterns, suppose R denotes the storage capability, then R = P/N. The storage capability of Hopfield networks has been studied for a long time, and the maximum storage capability of Hopfield neural networks is 0.138N. Above this value the network will not learn and cannot store patterns, then the patterns will not be the stable points of the network.
There are two conditions when a stored pattern is considered as the attractor of the network. One is that the pattern is the fixed point of the network, and the other is that it must have the domain of attraction. Our proposed rules indicate that when the controlled parameter C > 0, the stored patterns satisfy the above two conditions.
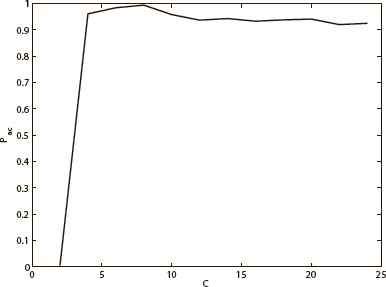
Fig. 1 shows the phase diagrams of the full-connected neural network, and Fig. 2 gives an example of the diluted neural network with f = 0.98. C1 and C2 are the two transformation points. The diluted neural network is set with 500 neurons, and the storage ratio is 0.02 (10 stored patterns). As mentioned earlier, the two neural networks are designed to have the same real neuron links in this paper. Therefore, the full-connected neural network has 495 neurons. The three phases a, b, r in Fig. 1 and Fig. 2 represent chaos phase, pure memory phase, and mixed phase. It is clear that the dynamics behaviors of the two neural networks are similar. However, the pure memory phase b and the first transformation point C1 of the diluted neural network are smaller than that of the full-connected one.
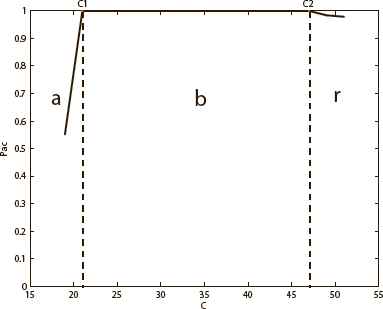
The transformation points and three phases of full-connected neural network

The transformation points and three phases of diluted neural network with f = 0.98
In the chaos phase and pure memory phase, there are no spurious memories and all the stored patterns are the fixed points of the networks. Thus, the first transformation point C1 can denote the maximum storage capability of the network without spurious memories. It is also called maximum effective storage capacity, denoted by αmax.
Fig. 3 and Fig. 4 on the next page show the storage capacity of the two neural networks. According to these two figures, αmax = 0.12 in full-connected neural network and αmax = 0.08 in the diluted neural network. The results indicates that the storage capability of the diluted neural network with fixed degree of dilution is lower than the full-connected one. Meanwhile, the first transformation point of the full-connected neural network does not change as the storage ratio changes. In other words, the first transformation point is independent of the storage ratio. However, in our designed diluted neural network, the first transformation point is stable at first but later increases when the storage ratio increases. The second turning point increases first and later decreases. Thus, in this diluted neural network, the first transformation point is not stable.

The value of αmax in full-connected neural network
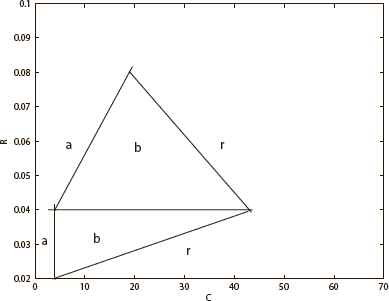
The value of αmax in diluted neural network
Fig. 5 and Fig. 6 show the storage capacity of the discrete multi-state neural network, which was designed in our previous work.15 According to Fig. 5 and Fig. 6, αmax = 0.11 in full-connected neural network and αmax = 0.04 in diluted neural network. Hence, this paper has similar conclusion, that the storage capability of the diluted neural network with fixed degree of dilution is lower than the full-connected one.

The value of αmax in full-connected neural network
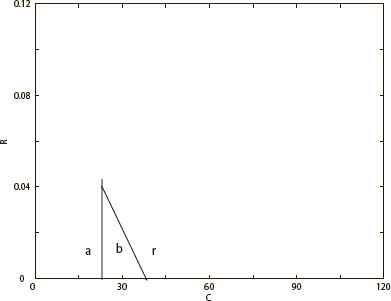
The value of αmax in diluted neural network
Fig. 7, Fig. 8 and Fig. 9 on the next page show the phase diagram of the diluted neural network with f = 0.96, f = 0.90 and f = 0.80, respectively. The diluted neural network is set with 500 neurons, and the number of stored patterns is 10. Compared with the phase diagram of Fig. 2, the pure memory phase becomes larger when f = 0.96, then it becomes smaller with the increasing of the degree of dilution. When f = 0.80, there is no pure memory phase in the diluted neural network, hence it is not necessary to continue exploring greater dilutions.
The transformation points and three phases of the diluted neural network with f = 0.96
The transformation points and three phases of the diluted neural network with f = 0.90
The transformation points and three phases of the diluted neural network with f = 0.80
Fig. 10 and Fig. 11 show the training time and retrieval time of the full-connected neural network and diluted neural network with 10 stored patterns. Fig. 12 and Fig. 13 show the training time and retrieval time of the full-connected neural network and diluted neural network with 20 stored patterns. The training time and retrieval time represent the training step length and retrieval step length, respectively. The size of the diluted neural network is 500 and f = 0.98. The full-connected neural network has 495 neurons. The results indicated that the diluted neural network needs more training time (study step) than that of the full-connected one but it needs less retrieval time. Due to space limit, herein we only show the results in the pure memory phase, the chaos phase and mixed phase have the similar results.
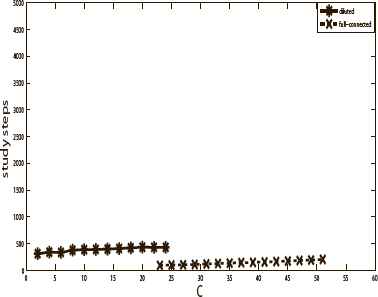
The training time of the two neural networks with 10 stored patterns
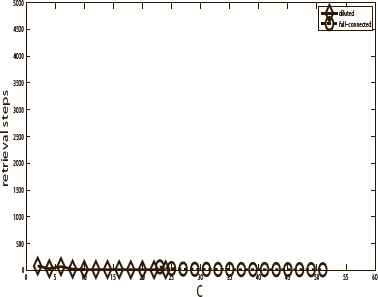
The retrieval time of the two neural networks with 10 stored patterns
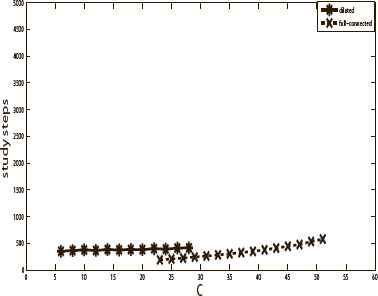
The training time of the two neural networks with 20 stored patterns
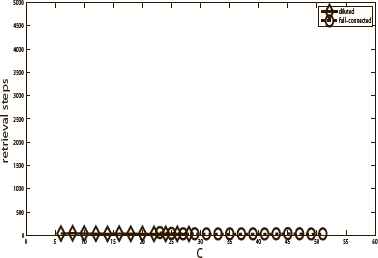
The retrieval time of the two neural networks with 20 stored patterns
4. A Case Study
After presenting the design rule and studying the dynamic behaviors of the full-connected neural network and the diluted neural network, the two neural networks will also be applied for solving the handwritten digital image problem.
In our evaluation, we experimented with the U.S. Postal (USPS) handwritten digits dataset.27 The dataset consists of a training set with 7291 images and a test set with 2007 images. The images are 16*16 eight-bit grayscale maps, with each pixel ranging in intensity from 0 to 255. The task is to predict, from the 16*16 matrix of pixel intensities, the identity of each image (0, 1, …, 9) quickly and accurately.27 In order to get binary data, we converted each pixel into two bits, and each image has 512 bits. Then we set the number of neurons in the diluted neural network to 512.
In the evaluation, we chose ns (ns ∈ {1, 2, …, 6}) samples for each image (0, 1, …, 9), and we got 10 * ns training cases. Then the storage capability is R = 10*ns/512. The size of the pure memory phase is denoted as Spm = C2 − C1. Fig. 14 shows the value of Spm of the full-connected neural network and the diluted neural network. The degree of dilution in the diluted neural network is set to f = 0.98. The results indicated that the value of Spm of the full-connected neural network is greater than that of the diluted neural network when they had the same storage capability.
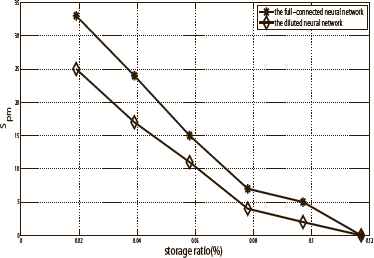
The size of the pure memory phase of the two neural networks
5. Conclusion and Future Work
This paper presented the designed diluted neural network with fixed degree of dilution. The dynamics behaviors of this network are consistent with the discrete multi-state diluted neural network in previous works. In our previous work, the degree of dilution was not fixed and the size of the full-connected neural network was same with that of diluted neural network. In this paper, the degree of dilution is fixed and only the real neuron links of the two neural networks are the same. Thus, the sizes of the two neural networks are different. The simulation results demonstrated that the maximum storage capability of the designed diluted neural network is smaller than that of the full-connected neural network designed by the MCA rule. Meanwhile, in our experiment, the pure memory phase of the diluted neural network exists when the degree of dilution f ∈ {0.8, 1}. And in the beginning, the pure memory phase of the diluted neural network becomes larger with the increasing of the degree of dilution (f ∈ {0.9, 1}), then it becomes smaller with the increasing of the degree of dilution (f ∈ {0.8, 0.9}). The results also indicated that the second transformation point of the diluted neural network does not decrease with the increase of the number of stored patterns, but fluctuates.
We will conduct further research on other unsolved issues. For example, the diluted elements in this paper are asymmetry, and every row of the coupling matrix has the same number of nil elements. The performance of the symmetry diluted elements is also worth to investigate for future work.
Acknowledgments
This work has been partly supported by National Natural Science Foundation of China under Grant No. 60973137, Gansu Sci. & Tech. Program under Grant No. 1104GKCA049 and No. 1204GKCA061, the Fundamental Research Funds for the Central Universities under Grant No. lzujbky-2012-44 and No. 8002/20103156225, and UOW’s UIC Project 2015. We would like to thank Dr. Tao Jin for suggestions and comments during this work.
References
Cite this article
TY - JOUR AU - Lijuan Wang AU - Jun Shen AU - Qingguo Zhou AU - Zhihao Shang AU - Huaming Chen AU - Hong Zhao PY - 2016 DA - 2016/12/01 TI - An Evaluation of the Dynamics of Diluted Neural Network JO - International Journal of Computational Intelligence Systems SP - 1191 EP - 1199 VL - 9 IS - 6 SN - 1875-6883 UR - https://doi.org/10.1080/18756891.2016.1256578 DO - 10.1080/18756891.2016.1256578 ID - Wang2016 ER -