
IBA-based framework for modeling similarity
- DOI
- 10.2991/ijcis.11.1.16How to use a DOI?
- Keywords
- Multi-attribute object comparison; IBA similarity measure; Logical aggregation; Modeling similarity; Similarity-based classification
- Abstract
In this paper, we introduce a logic-driven framework for modeling similarity based on interpolative Boolean algebra (IBA). It consists of two main steps: data preprocessing and similarity measuring by means of IBA similarity measure and logical aggregation. The purpose of these steps is to detect dependencies and model interactions among attributes and/or similarities using an appropriate operator. The proposed framework is general, providing different approaches to multi-attribute object comparison: attribute-by-attribute comparison, object-level comparison and their combination. It is also a generic framework since various similarity measures can be easily derived. The proposed IBA-based similarity framework has a solid mathematical background, which ensures all necessary properties of similarity measure are satisfied. It is interpretable and close to human perception. The framework’s applicability is illustrated by two numerical examples that confirm the need for a different level of aggregations. Furthermore, the example of similarity-based classification demonstrates the descriptive power and transparency of the framework on real financial data.
- Copyright
- © 2018, the Authors. Published by Atlantis Press.
- Open Access
- This is an open access article under the CC BY-NC license (http://creativecommons.org/licences/by-nc/4.0/).
1. Introduction
Similarity plays a fundamental role in human experience and learning. It refers to some degree of closeness between two physical objects or ideas/concepts.1 When dealing with the problem of comparing multi-attributes objects, similarity is usually measured by distance functions in metric spaces (e.g. Euclidean distance), statistical measures based on correlation (e.g. cosine similarity) and logic-based measures (e.g. Refs. 2, 3), along with chosen aggregation function. Many logical formalizations have been developed in order to model vagueness, uncertainty and truthlikeness such as many-valued logics (including fuzzy logic), probabilistic logic, etc.
As the notion of similarity is graded in its nature, these logic-based approaches are natural formalizations for similarity-based reasoning.4 On the other hand, logic-based aggregators are not commonly used in similarity measuring, although they are able to model both linear and non-linear relations among attributes. Dealing with correlation and logical dependences among attributes prior to measuring similarities may be crucial for appropriate similarity modeling. Therefore, it is particularly important to consider the idea of the similarity framework that is entirely based on logic.
In Refs. 5–8, the extensive overview and comparison of similarity measures among fuzzy concepts have been provided. For measuring similarity, the authors3 recognized a group of distance measures specified for membership functions of fuzzy sets (e.g. Refs. 5, 9), set-theoretic approach (e.g. Refs. 10, 11), the approach based on logical concepts of fuzzy implication (e.g. Refs. 12, 13). In terms of logic, possible formalizations of similarity are both implication and equivalence relations: fuzzy equivalence (e.g. Refs. 14, 15), fuzzy implication (e.g. Ref. 16), IBA equivalence17, etc.
Along with the choice of similarity measure, an appropriate aggregation operator is crucial for the comparison of multi-attribute objects. The most common aggregation operators are related to the means (e.g. arithmetic mean, weighted means, order weighted aggregation (OWA) operators, etc.)18, integrals (e.g. discrete Choqeut19, generalized Choquet20, etc.), t-norms (e.g. min, product, etc.)21. In case not all similarities are equally important, weighting techniques are used, e.g. weighted Euclidean distance22. Combining various similarity measures (Jaccard index, cosine, proximity or correlation similarity measure) with the max-min composition or weighted sum as aggregation operators was proposed in Ref. 23 for content-based recommender systems. Enhancing generalized Lukasiewicz structure using weights was proposed and evaluated on several well-known medical classification problems.24 In Ref. 25, the authors introduced a similarity measure based on probabilistic equivalence relations and generalized mean. Other mean-related aggregation functions, such as Bonferreni mean26, are also used for defining similarities. Similarity measures obtained by OWA operators are improved in the sense that they can model particular types of interactions of similarities. OWA operators were used to aggregate similarities obtained by different measures into a resulting value.27 A family of order weighted distance operators (OWAD) was introduced by combining OWA operator and Hamming distance.28 OWAD operators were further extended using other distance functions such as Euclidean and Minkowski.29,30 Choquet integral is also considered to be a promising tool for modeling various interactions of attributes/similarities, while t-norms and t-conorms have the property of compensation in marginal cases when realized as min and max functions. In Ref. 31, the authors used the discrete Choquet integral as a basis for defining a metric which is applied in semi-supervised clustering. Furthermore, a similarity measure of intuitionistic fuzzy sets was built using Sugeno integral.32 In Ref. 33, the similarities are aggregated by combining a conjunction of chosen attributes with weighted sum. Generalization of geometrical approach to measuring similarity by including interaction of attributes was proposed in Ref. 34. Some of the most distinguished similarity measures and aggregation operators for ordinary fuzzy sets and their extensions (including intuitionistic, type-2, interval-valued, hesitant fuzzy sets, etc.) are given in Ref. 35.
In this paper, we present a novel logic-driven framework for modeling similarity between multi-attribute objects based on interpolative Boolean algebra (IBA). It is based on two main components: IBA similarity measure17 and logical aggregation (LA)36. IBA similarity measure is based on logic which makes it easily interpretable and close to human perception of similarity, which is a desirable property for clustering37, classification38, etc. Further, the proposed framework uses LA capable of modeling any logical (non-linear) interaction among attributes which is not the case with the previously mentioned approaches. Moreover, the proposed framework allows comparison of objects on both attribute-by-attribute and the object-level. The usual way to compare objects is attribute-by-attribute, when all attributes are compared separately and afterwards aggregated into a resulting value. However, there are occasions when it is necessary to consider object’s attributes jointly in order to capture the meaning of the object. On these occasions, one should use suggested similarities defined on the object-level, where aggregation of attributes using LA is realized prior to measuring similarities. The proposed framework is flexible, allowing the decision maker to account for different perspectives of modeling similarity. From the mathematical point of view, this approach is generic since LA is a generalization of simple mean, weighted sum, OWA, Choquet integral, etc. Further, we illustrate the applicability of the proposed approach with two simple numerical examples. In the first illustrative example, we demonstrate the importance and benefits of the object-level comparison. In the second example, the proposed framework is applied for similarity-based classification with k-Nearest Neighbors (k-NN) algorithm on a real financial dataset.
This paper is organized as follows. In Section 2, we outline basic definitions and provide a brief overview of IBA. The framework for modeling similarity based on IBA similarity measure and logical aggregation is introduced in Section 3. Further, the applicability of the proposed framework is illustrated in Section 4. In the final section, we summarize the main findings and give guidelines for future work.
2. Theoretical background
2.1. Mathematical prerequisites
The notion and some basic mathematical prerequisites concerning similarity measure and an aggregation operator are given in this section.
Definition 1.1
Let X be a set. A function S : X2 → R is called similarity on X if, for all x, y ∈ X there holds:
- -
S(x, y) ≥ 0 (non-negativity);
- -
S(x, y) = S(y, x) (symmetry);
- -
S(x, y)) ≤ S(x, x) with equality iff x = y (limited range).
Problems of modeling similarity and distance are dual concepts. From the standpoint of logic, similarities are the negation of distances. In other words, if the distance function D satisfies properties of non-negativity, symmetry and reflexivity on [0,1] interval, the similarity function may be derived as S = f (D), where f is some fuzzy negation.1
Definition 2.39
A function A : [0,1]2 → [0,1] is called aggregation operator if, for all xi, yi ∈ [0,1], i = 1,…,m, there holds:
- -
A(0,…,0) = 0 (lower boundary condition);
- -
A(1,…,1) = 1 (upper boundary condition);
- -
A(x1,…, xm) ≤ A(y1,…, ym) when xi ≤ yi, i = 1,…, m (monotonicity).
2.2. Interpolative Boolean algebra
Interpolative Boolean algebra (IBA) is a Boolean consistent real-valued realization of finite Boolean algebra (BA).40 It is a two-level logic that consists of symbolic and valued level.
On the symbolic level, any element of BA:
The transformation procedure of logical functions to corresponding GBPs is introduced in Ref. 36. Operators in GBP are standard +, standard – and generalized product ⊗ (GP), and its variables are observed attributes.
Definition 3.36
A function ⊗: [0,1]2 → [0,1] is called generalized product if, for all attributes x, y, z ∈ [0,1], there holds:
- -
x ⊗ y = y ⊗ x (commutativity);
- -
x ⊗ (y ⊗ z) = (x ⊗ y) ⊗ z (associativity);
- -
x ⊗ y ≤ x ⊗ z when y ≤ z (monotonicity);
- -
x ⊗ 1 = x (neutral element/boundary condition);
- -
The most important property of GP on the symbolic level is idempotency. In fact, it is one of IBA transformation rules36:
Once the structural transformations have been conducted, the valued level is introduced. On the valued level, GP is a subclass of t-norms since it should satisfy the additional non-negativity condition. According to the defined properties, GP may be realized as any t-norm that produces the result from the following interval36:
Although t-norms and realizations of generalized products are formally similar, their roles are crucially different: while a t-norm in conventional fuzzy approaches has the role of a logical (and/or algebraic) operator, GP is only an arithmetic operator on a value level without any influence on algebra.36 Algebra is wholly determined by the structural transformation procedure. Therefore, GP is idempotent on the symbolic level, regardless of its realization on the valued level.
2.2.1. IBA similarity measure
From the standpoint of logic, the similarity of two attributes is commonly perceived as logical relations of equivalence (bi-implication). Thus, the relation of equivalence in the IBA framework is defined as similarity measure.17 GBP of IBA similarity measure and its realization on the valued level are:
Theorem 1.
Let SIBA : [0,1]2 → [0,1] be the relation of equivalence in the sense of IBA. For any x, y ∈ [0,1], SIBA (x, y) is a similarity measure.
Proof.
The proof can be found in Ref. 17.
IBA similarity on the valued level is mathematically identical to Lukasiewicz bi-implication SLUK (x,y) = 1 − | x − y|. However, IBA equivalence is valuable from the aspect of interpretation and the possibility to be combined with other IBA-based tools such as logical aggregation.
IBA similarity measure is realized as the union of the intersection of attributes (“both having the trait”) and the intersection of their complements (“both not having the trait”).17 Therefore, this measure treats all values from the unit interval equally, which is very important for many applications. Also, IBA similarity has a clear-cut meaning and a comprehensible graphical interpretation. The proposed measure was applied for modeling consensus in group decision making41, formalizing the human categorization process38, logical clustering42, etc. In Ref. 17, it is shown that IBA similarity overcomes the drawbacks of classical logic-based similarity measures (min and product bi-implication) on the problem of modeling consensus.
2.2.2. Logical aggregation
For the purpose of aggregating information in IBA framework, Radojevic introduced logical aggregation (LA). LA is a transparent, a Boolean consistent procedure for aggregating attributes in a resulting value with significant meaning.36 It consists of two steps:
- (i)
Normalization of attributes' values to the unit interval;
- (ii)
Aggregation of normalized values into the resulting value by means of a logical/pseudo-logical function.
If the aggregation function is a logical expression, attributes are aggregated using corresponding GBP. In the general case, the aggregation function may be pseudo-logical, i.e. the linear convex combination of GBP.
Definition 4.36
A logical aggregate on operator LA: [0,1]m → [0,1] in general case is a pseudo-logical function, i.e. a linear convex combination of generalized Boolean polynomials
In this way, it is possible to aggregate partial demands expressed as logical expressions using weighted sum. Thus, arithmetic mean, weighted sum, min function, discrete and generalized Choquet integral can be obtained as special cases of LA.36
In the general case, logical aggregation is not monotone, e.g. IBA similarity measure. Although violation of monotonicity has its benefits, e.g. a possibility to model various interactions of attributes43,44, LA does not satisfy all properties to be an aggregation operator. On the other hand, some special cases of LA are monotone. For instance, GP as a subclass of t-norms satisfies all conditions for aggregation function.
3. Modeling similarity: IBA-based framework
The aim of this section is to introduce different approaches to modeling similarity using IBA. Relying on IBA similarity measure and logical aggregation, we present several relations for multi-attribute objects. Special attention will be devoted to the mathematical background/properties of the framework, its validity and applicability. Also, we formalize the IBA-based procedure for modeling similarity explained in several steps.
3.1. IBA-based similarity framework
There are two main steps to perform when modeling similarity using the IBA-based framework:
- (i)
Data preprocessing (data normalization, detection of attribute nature and their potential interaction);
- (ii)
IBA similarity modeling (attribute-by-attribute comparison, comparison on the level of the object and general (combined) approach).
3.1.1. Data preprocessing
Normalization of attribute data is a starting point for data analysis and preprocessing. Data normalization to [0,1] interval is a mathematical prerequisite for similarity modeling using IBA. Standard normalization functions used are min-max normalization, scaling with maximum value, etc. where the attribute data are scaled so as to fall within a unit interval. On the other hand, normalization functions may be adapted depending on data range and distribution, e.g. so as to be able to transform both positive and negative values to unit interval. Sometimes from the aspect of the decision maker it is appropriate to use a normalization function in the opposite direction, e.g. the lower price the better. In the next step, it is important to examine the nature of the attributes and their potential interaction. Generally, the existence of significant correlation in attribute data will overemphasize certain attributes and/or cause incoherent model results.45 In our framework we make use of correlation to detect similar nature between attribute data. Further, the min function is used as GP for these attributes. The idea is also to examine whether some attributes can compensate for others or to model other meaningful logical dependence discovered by the experts.
3.1.2. IBA similarity modeling
Two distinctive cases when modeling similarity of m-attribute objects using IBA are presented. The first one is based on a conventional attribute-by-attribute comparison, while in the second comparison is performed on the level of the object. Also, we introduce the general model that includes both approaches to comparison and even combines them. All proposed models are novel except the ABA comparison 1. This model is used in practice17 although it is not mathematically formalized and its properties are not investigated so far.
Attribute-by-attribute comparison (ABA). In this approach, the conventional ABA comparison using IBA similarity measure is followed by suitable logical aggregation.
ABA comparison 1. In the first one, the similarity between two objects is modeled as a conjunction of the attribute similarities. As it is explained in Ref. 17, there are situations in group decision making when it is necessary to detect the guaranteed (minimal) level of similarity between two objects. These situations may be modeled as LA of the attribute similarities, where LA operator is realized as the conjunction. In the sense of IBA, this model corresponds to a generalized product of the attribute similarities.
ABA comparison 2. The second one is the convex linear combination of GPs of similarities. There are situations when a conjunction of similarities should be observed as partial demands that are further aggregated using weighted sum. For instance, in determining similarity of two students, we may be interested in two aspects: 1) similarity of their math grades and 2) similarity of their social science grades modeled as a conjunction of similarities between history grades and similarities between geography grades. This may be modeled as weighted sum of GPs of similarities:
Comparison on the object-level (OL). This approach involves comparison on the level of the object. First of all, the object is uniquely represented by a single value obtained using a logical aggregation function. These values are compared afterwards using the IBA similarity measure.
General model. The general approach combines Eq. (8) and Eq. (9) in order to incorporate the benefits of both previously presented models. It should be used in occasions when it is necessary to model both interaction of attributes, e.g. to appropriately present the object, and interaction of similarities, e.g. to model partial demands and guaranteed level of similarity:
The models given in Eqs. (6), (8) and (9) may be seen as special cases of this relation.
3.2. Mathematical properties
ABA comparison. The conventional ABA comparison using IBA similarity measure followed by logical aggregation is not a similarity measure due to characteristics of LA.
Lemma 1.
Let
Proof.
We need to investigate if relation
- -
- -
Symmetry:
- -
Limited range is not fulfilled in the general case. For instance, we may compare two 2-attribute objects using the following LA function:
However, there are certain situations when this kind of aggregation is appropriate for similarity modeling. For instance, in consensus models, LA realized as a disjunction (max function) may be appropriate in the case when it is satisfactory for a high level of consensus that at least two experts have a high level of agreement.41 In Ref. 4 authors also refer to similar types of non-monotonic inferences, namely pessimistic and optimistic inferences.
The other proposed relations for comparison of multi-attribute objects satisfy all properties of similarity measure.
Theorem 2.
Let
Proof.
We need to investigate if relation
- -
Since GP is a special case of LA, non-negativity and symmetry are followed as a consequence of the proofs in Lemma 1.
- -
Limited range: Due to the limited range property of IBA similarity and 1 is the neutral element for GP
Theorem 3.
Let
Proof.
We need to investigate if relation
- -
Since the weighted sum of GPs is a special case of LA, non-negativity and symmetry are followed as a consequence of the proofs in Lemma 1.
- -
Limited range: Due to the limited range property of IBA similarity measure and the idempotency of GP
Comparison on OL. The proposed IBA-based relation for comparison on OL is a similarity measure in the general case.
Theorem 4.
Let
Proof.
We need to investigate if relation
- -
Non-negativity: Due to the definition of LA,
- -
Symmetry: Due to commutativity of GP
- -
Limited range: Due to the idempotency of GP (Eq. (2)),
General model. The general model is obtained by combining ABA similarity and the comparison on OL, and it is a similarity measure in the general case.
Theorem 5.
Let
Proof.
We need to show that relation
- -
Non-negativity: IBA similarity measure of logical aggregations SIBA (X, Y) ≥ 0 due to the non-negativity proof of Theorem 4. Since the non-negativity property of GP and weighted sum
- -
Symmetry: Due to commutativity of GP
- -
Limited range: Since
4. Numerical examples
In this section we aim to illustrate applicability of the proposed approach and its advantages comparing to traditional methods. In the first example, we highlight the benefits of the proposed IBA-based OL comparison in regard to traditional approaches. In the example concerning similarity-based classification, the classification accuracy is significantly improved as we model existing dependencies and interactions in the data by means of the proposed similarity framework.
Example 1 Car comparison on the level of the object.
The aim of this example is to illustrate, numerically and graphically, the motivation for the novel OL comparison. In this example, we compare cars described by two attributes: speed as and comfort ac, whose values are normalized to the unit interval (Table 1). In order to measure similarity between cars X and Y, and cars U and V, we use common Euclidean distance as well as the proposed IBA comparison approach: ABA and OL.
| car | speed | comfort |
|---|---|---|
| X | 0.7 (fast) | 0.6 (comfortable) |
| Y | 0.3 (slow) | 0.4 (not so comfortable) |
| U | 0.7 (fast) | 0.4 (not so comfortable) |
| V | 0.3 (slow) | 0.6 (comfortable |
The characteristics of observed cars X, Y, U and V
On the intuitive level, it seems that cars U and V are more similar than cars X and Y.
If Euclidean metric is used to measure the dissimilarity of X and Y, and U and V the resulting values are equal:
The similarities between the cars in the example are also equally valued by means of IBA-based ABA comparison. The corresponding GBPs and relations on the valued level are given in Appendix A.
The graphical interpretation of similarities between the analyzed cars is presented in Fig. 1. Although the geometrical distance between points U and V is equal to the distance between points X and Y, the hatched surfaces that represent the similarity of objects from the aspect of the proposed IBA-based approach are different. More precisely, the hatched surface for U and V is greater than the surface for X and Y. Thus, the graphical interpretation supports the conclusion that objects U and V presented on the right in Fig. 1 are more similar than objects X and Y.
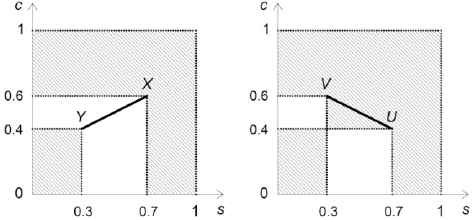
Geometrical interpretation of similarities S(X, Y) and S(U, V)
Example 2 Similarity-based classification.
Similarity-based classification is another example where we apply and evaluate the IBA similarity modeling framework. Basically, we use a simple k-NN algorithm constructed using IBA similarity measure and logical aggregation. The benefits of the proposed aggregation approaches – ABA and OL are also presented. We also compare the results to the traditional k-NN algorithm with Euclidean distance.
Our classification problem is to predict bankruptcy of Serbian middle-sized companies. Using financial reports of 72 Serbian companies, we calculated five financial ratios used in the Z-score model46 which is widely applied for predicting corporate bankruptcy. These five financial ratios also served as inputs in our classification models, whereas company status (active or bankrupt) is the output. For the purpose of fair comparison among different similarity-based classifiers, we used a balanced dataset. To ensure low bias, we applied the holdout method that is run 100 times as in Ref. 24. Each time data were randomly divided in two equal parts for training and testing.
In the data preprocessing step, attributes’ values were scaled to unit interval using standard min-max normalization. Further, a high positive correlation was detected in the data between attributes a2 and a3 and attributes a2 and a4.
For IBA similarity modeling, three groups of IBA similarity classifiers (Eqs. (14), (15), (16)) were constructed on the basis of proposed ABA and OL comparison. The first two classifiers employ a simple average as aggregation operator:
The following two classifiers aim to model interaction in the data by using the conjunction of attributes/similarities. Herein, the simple product is used as the operator of GP in aggregation. These models do not include possible correlations.
Average accuracy (accy.) and variance (var.) of all presented classification models and k = {1,3,5,7,9} are presented in Table 2.
| k-NN | level | Euclidean distance (X,Y) | S1(X,Y) (average) | S2(X,Y) (product) | S3(X,Y) (correlation) | ||||
|---|---|---|---|---|---|---|---|---|---|
| accy. | var. | accy. | var. | accy. | var. | accy. | var. | ||
| 1-NN | ABA | 0.7389 | 0.0028 | 0.7268 | 0.0049 | 0.7486 | 0.0052 | 0.8823 | 0.0027 |
| OL | 0.5391 | 0.0038 | 0.8368 | 0.0054 | 0.7873 | 0.0039 | |||
| 3-NN | ABA | 0.7931 | 0.0019 | 0.8000 | 0.0057 | 0.7986 | 0.0056 | 0.9068 | 0.0029 |
| OL | 0.5064 | 0.0008 | 0.8350 | 0.0045 | 0.8441 | 0.0041 | |||
| 5-NN | ABA | 0.8050 | 0.0019 | 0.8109 | 0.0040 | 0.8055 | 0.0043 | 0.9068 | 0.0029 |
| OL | 0.4995 | 0.0000 | 0.8464 | 0.0045 | 0.8677 | 0.0046 | |||
| 7-NN | ABA | 0.8233 | 0.0016 | 0.8164 | 0.0040 | 0.8127 | 0.0042 | 0.8623 | 0.0045 |
| OL | 0.5000 | 0.0000 | 0.8441 | 0.0045 | 0.8791 | 0.0042 | |||
| 9-NN | ABA | 0.8189 | 0.0018 | 0.8232 | 0.0055 | 0.8209 | 0.0044 | 0.8450 | 0.0053 |
| OL | 0.5000 | 0.0000 | 0.8427 | 0.0054 | 0.8673 | 0.0040 | |||
Results k-NN classification based on Euclidean distance and IBA similarity relations.
The traditional k-NN with Euclidean distance serves as a benchmark with classification accuracy of around 82%. Similar classification results are achieved for the IBA-based classifiers with the simple average of similarities (Eq. (14.1)) for k = 9. However, the low accuracy for simple average on OL (Eq. (14.2)) shows that the described relation could not present the object properly. The previous classifiers neither take into account interaction nor the correlations.
The following models (Eq. (15)) that use product function as an aggregation operator try to capture possible interaction among attributes/similarities. The results indicate that modeling interactions as an aggregation of attributes makes more sense than aggregating similarities. In case of the analyzed data, the described aggregation function on the object level (Eq. (15.2)) improves classification results and classification accuracy is greater than the benchmark. The highest classification accuracy is achieved when the detected correlations among attributes/similarities are taken into account. Both described classifiers (Eq. (16.1)) and (Eq. (16.2)) improve classification results considerably. However, this time ABA approach outperforms OL comparison, having the best classification accuracy of approximately 90%.
In a nutshell, the classification accuracy is significantly improved as we are able to model existing dependencies and interactions in the data by means of the proposed similarity framework. The constructed classifiers are very descriptive and we can understand the results easily. When it comes to large datasets, IBA-based k-NN inherits all well-known pros and cons from a traditional k-NN. Additionally, it is obvious that comparison on OL is less computationally demanding than ABA comparison.
5. Conclusion
The aim of this paper is to introduce the unified logical framework for modeling similarity based on IBA. It employs the benefits of the existing IBA similarity as interpretable measure and logical aggregation as a descriptive aggregation operator.
In this paper, we have shown that proposed IBA-based similarity framework has a solid mathematical background. More precisely, we have formalized IBA similarity framework and further investigated its properties. In the general case, the proposed IBA similarity models satisfy properties of being similarity measure. Additionally, IBA-based similarity framework can also be expanded to model non-monotonic inference. Still, the main contribution of our framework lies in its novel approach to multi-attribute object comparison which includes attribute-by-attribute level and object-level comparison, as well as their combination.
The practical advantage of the IBA-based similarity modeling is evaluated on two numerical examples. The first example is illustrative and it confirms motivation and reasoning behind the novel OL comparison. Even though it may not be conventional, OL comparison is important; particularly in the occasions when one object’s attribute is logically dependent or can be compensated by another attribute. In the second example, the proposed similarity framework is applied for predicting corporate bankruptcy. Different k-NN classifiers are easily derived on the basis of IBA similarity and LA operators, which has illustrated the generic nature of the proposed IBA-based approach. It is shown that these classification models outperform traditional k-NN with Euclidean distance. They also demonstrate descriptive power and transparency of the proposed similarity modeling.
From the theoretical standpoint the proposed IBA-based similarity framework is rather complete. In future work, the main focus will be on application of the proposed similarity approach to solving problems such as similarity-based classification, clustering, recommender systems as well as TOPSIS based on IBA similarity. Other natural directions for future research include parameterization of IBA similarity measure.
Appendix A.
Similarity models given in Eq. (12) are mapped in the following GBP.
The product function is used to aggregate speed and comfort since attributes s and c are independent, while the min function is used to aggregate attributes of the same nature.
Appendix B.
Similarity models given in Eq. (13) are mapped in the following GBP.
The product function is used to aggregate speed and comfort since attributes s and c are independent, while the min function is used to aggregate attributes of the same nature.
References
Cite this article
TY - JOUR AU - Pavle Milošević AU - Ana Poledica AU - Aleksandar Rakićević AU - Vladimir Dobrić AU - Bratislav Petrović AU - Dragan Radojević PY - 2018 DA - 2018/01/01 TI - IBA-based framework for modeling similarity JO - International Journal of Computational Intelligence Systems SP - 206 EP - 218 VL - 11 IS - 1 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.11.1.16 DO - 10.2991/ijcis.11.1.16 ID - Milošević2018 ER -