
A Methodology to Refine Labels in Web Search Results Clustering
- DOI
- 10.2991/ijcis.2019.125905647How to use a DOI?
- Keywords
- Information retrieval; Machine learning; Web search results clustering; Web intelligence
- Abstract
Information retrieval systems like web search engines can be used to meet the user’s information needs by searching and retrieving the relevant documents that match the user’s query. Firstly, the query is inputted to the web search engine and assumed to be a good representative for the user’s intention and reflecting specifically his information needs and thus it should be long enough, discriminative, specific and unambiguous. Secondly, the web search engine typically respond to the query by sending back a long flat list of web search results and each search result represents a relevant document. Typically, that list may contain thousands or millions of web search results and thus it is difficult to navigate and locate a specific document relevant to a specific topic. As a postretrieval process, web search results clustering may be a solution for this issue where web search results can be categorized as clusters. These clusters supposed to contain topically related documents and labelled by descriptive and concise labels. These labels supposed to correctly describe the contents of each cluster. Thus the users can easily choose a cluster representing the intended topic and navigate through relatively few documents inside that cluster. High-quality labelling for clusters is crucial for users who can now gain insight into that clusters’ contents, general structure, and distribution of the topics among documents in the clusters. This make the user able to preview and navigate easily and fast. To this end, the authors in this paper introduced a methodology to enhance labels for clusters of web search results. The proposed methodology is founded on the idea of using the existing labels nominated by the original Suffix Tree Clustering (STC) algorithm and adapting these labels and/or clusters so that it become more concise and descriptive. The propose methodology was conducted on the original STC algorithm to produce an enhanced version of the classical STC algorithm. The enhanced algorithm was experimented and the produced clusters and labels were evaluated and compared with respect to the classical STC algorithm. For evaluation, the authors used clusters labelling performance measure considered five parameters f1: Comprehensibility, f2: Descriptiveness, f3: Discriminative Power, f4: Uniqueness, and f5: Nonredundancy. The reported results shown that the new enhanced labels outperformed the original labels and the overall performance has been enhanced. The recorded results indicated that: (i) The proposed methodology achieved better performance and the overall average recorded values for the used performance measure (f6) was 0.921. (ii) Number of clusters was decreased from 15 to 9 clusters only. (iii) Number of duplicated results was decreased from 143 to 121 only, and (iv) average number of phrases per label was increased from 1.67 to 2.00 phrases.
- Copyright
- © 2019 The Authors. Published by Atlantis Press SARL.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
Web pages are dynamic, superabundant, and miscellaneous and thus a heterogeneous variation of topics represented by this massive amount of documents is expected as these documents are originated from various resources worldwide and covering various topics like, for example, arts, science, engineering, economy, politics, sport, and so on.
Starting, typically, from the first web search result(s) the user may waste a valuable time to browse many search results which are irrelevant to the intended topic that the user looking for. As a result, nearly (50%) of users only browse the first two pages of the Web Search Results returned from the search engine [1]. This arises the need for more sophisticated web search engines that may employ “postretrieval” process to improve the presentation of the search results to the users [2] where the search results can be organized into labelled clusters. Each cluster represents a specific topic and this is very important to the user who will be able to avoid previewing many irrelevant documents by deepen the navigation inside the intended cluster covering a specific topic and containing homogenous documents relevant to the user’s information needs. Furthermore, it is beneficial for the naive users to possibly find “unexpected relevant documents” too [3]. To achieve this we need more than document grouping; the most important requirement is how to choose a comprehensible and expressive descriptor or label for each documents group, so that the user will be able to locate the intended documents easier and faster depending on that short and meaningful labels to concisely explain to the users what the group’s content is about [4].
In general, the performance of many search results clustering techniques is still poor in the context of clusters labelling especially when the labelling phase is highly dependent on the efficiency of clustering phase that determine the content of each cluster. Homogeneous content for a cluster is crucial to induce a good label for that cluster. Many promising directions for various research approaches presented themselves so as to extend the functionality and enhance the operation of specific phases in the clustering algorithms. Choosing the appropriate clustering algorithm with optimized parameters and efficient mechanism to elect the representative terms to be used as candidate labels are the key to produce better clusters with concise and knowledgeable (descriptive and informative) labels.
Web search engines (like, for example, Google, Bing, Dogpile, Yahoo, and Baidu) respond to the user query by sending a long list of search results meeting the information requirements (user intention) expressed by that query. In ranked retrieval systems, thesearch results list is ordered decreasingly according to a specific relevancy ranking (scoring) scheme and typically contains a title, a small portion of text called snippet and a URL for each search result [3]. Figure 1 shows an example of web search results for the query: Hashemite university represented as a flat ordered list of results. Both the low precision and flat presentation of search results made the process of meeting the user’s information needs far more exhaustive than it should to be and thus raise the need for more sophisticated search engines in which the relevant search results are easier to brows and to navigate [5].
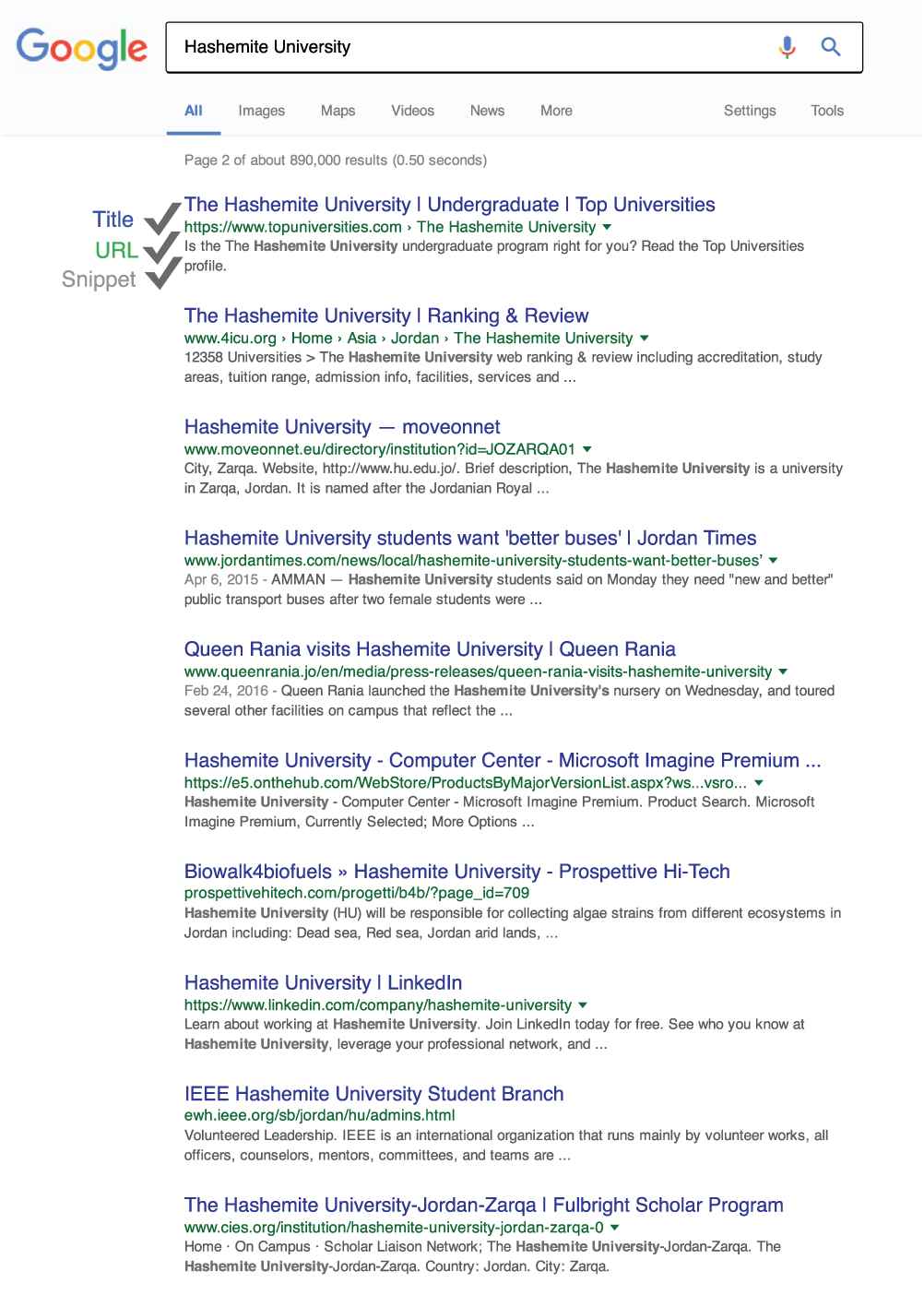
An example of a flat list of web search results for the query: Hashemite university containing a title, a URL and a snippet for each search result associated with a relevant document.
Query used for clustering.
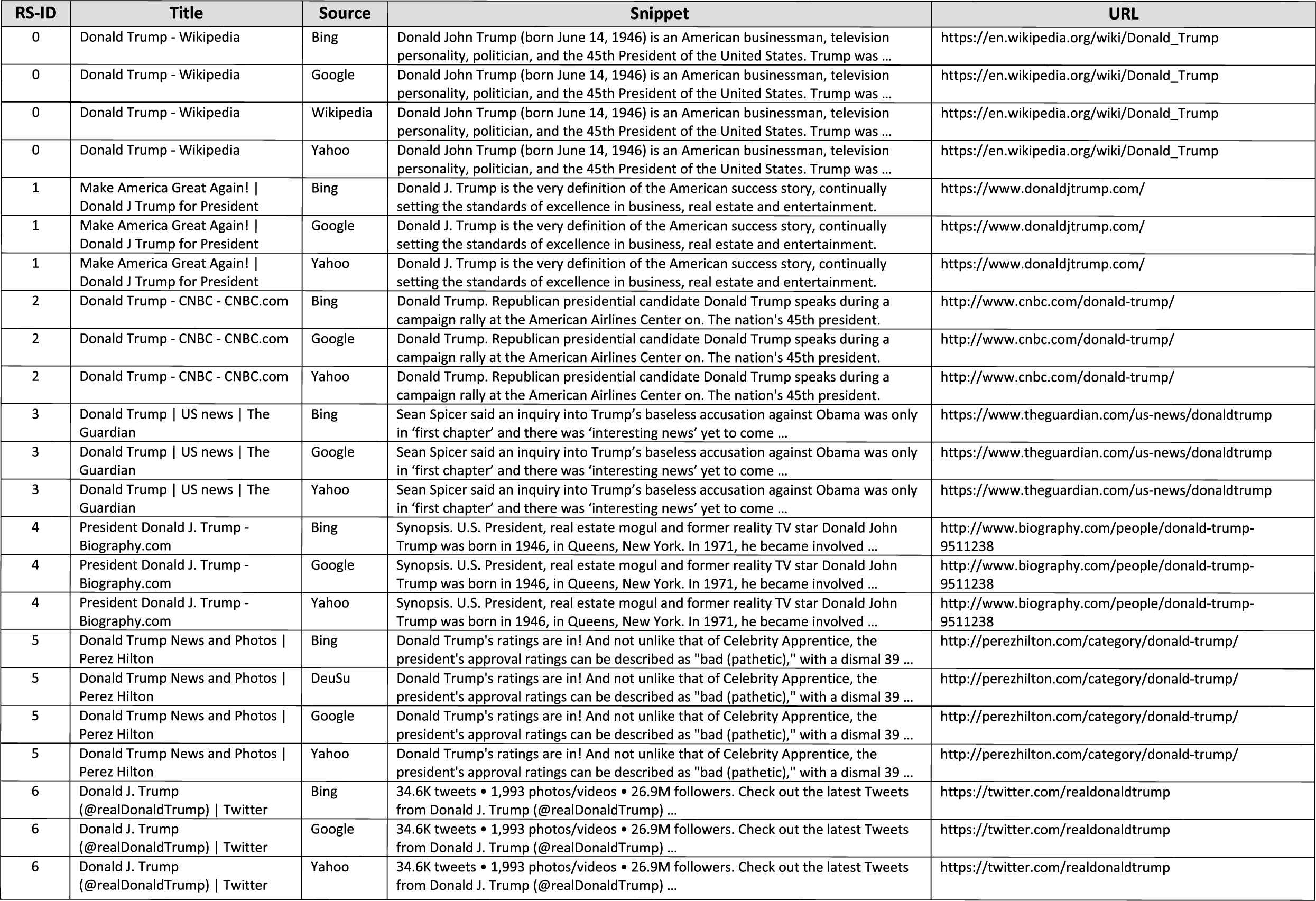
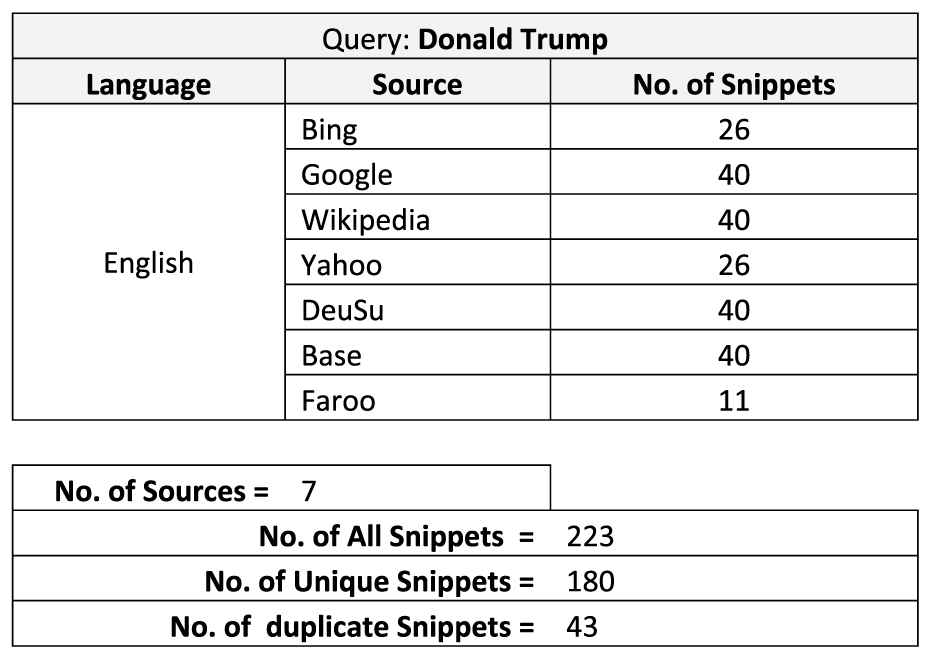
A list of the first 6 web search results retrieved from different web search engines (meta search) for the query: Donald Trump and containing a title, a URL and a snippet for each search result.
2. PRELIMINARIES
In this previous work section we provide some background concerning the labelling phase in the process of web search results clustering (WSRC). Various types of algorithms can be adopted for clustering textual documents employing, for example: neural network, fuzzy logic, rough set, or graph theory. WSRC algorithms can be classified into two categories [6]: (i) Numerical-based algorithms which have performance issues with web search result clustering because it expect full-text as input not short-text snippets like in web search results. In the other hand, its output is “raw numerical” thus it cannot be used to label clusters because it is un-interpretable by the user. (ii) Phrase-based algorithms which produce more comprehensible and descriptive labels than numerical algorithms. Table 1 [6] below differentiates between numerical-based and phrase-based algorithms while Table 2 [7] presents a comparison between the most typically used clustering algorithms in the literature based on various characteristics.
| Numerical-Based Algorithms |
|
| Phrase-Based Algorithms |
|
Comparison between numerical-based and phrase-based algorithms.
| Method | Semantic Relation | Cluster Label | Phrase Based | Incremental | Complexity |
|---|---|---|---|---|---|
| K-Means Clustering | No | One word only | No | No | O(nkt) k: initial clusters n: no. of documents t: iteration |
| Suffix Tree Clustering | Yes | Shorter but appropriate | Yes | Yes, but merging phase is not incremental | O(n) |
| Lingo | No | Longer more descriptive | Yes | No | O(n) |
| Semantic Suffix Tree | Yes | Meaningful and readable labels | Yes | Yes | O(n) |
| Improved K-Means | Yes | Based on K-means first and then on the documents linked to it | No | No | Time Consuming |
| Inductive Clustering | Yes | Phrases extracted from results from internal and external summary | Yes | No | Negligible with cluster titles |
| Fuzzy C-Mediod Clustering | No | Produce category | Yes | Yes | O(n2) |
| Histogram-based Clustering | Yes | Matching phrases of documents | Yes | Yes | O(n2) |
| Hierarchical Clustering | No | Most frequent terms from inside clusters | No | Yes | O(n2): single link O(n3): complete link |
| Semantic Hierarchical Online Clustering (SHOC) | Yes | Labels that describe clusters (extract frequent phrases and SVD technique) | Yes | Yes | O(n) |
SVD, singular value decomposition.
A comparison between the most typically used clustering approaches.
The Commonly used Suffix Tree Clustering (STC) algorithm deals with each document as a string (sequence of words) instead of a bag-of-words (BOW) which neglects the order of words while considers only the frequencies of distinct words occurrences in the corpus. STC uses suffix trees for summarizing the documents and extracting the frequent phrases while other algorithms like semantic hierarchical online clustering (SHOC) uses suffix arrays instead [8]. Label Induction Grouping Algorithm (Lingo) produces more clusters than STC and K-mean algorithms while STC is more scalable than Lingo and K-mean. [9] Lingo commences with extracting expressive labels first and then clustering documents individually to the fittest label (each label representing a cluster). Labels are generated from the pruned frequent terms (phrases and words) that achieve the required level of labelling descriptiveness and informativeness quality [7, 10].
In both Lingo and SHOC algorithms, labels of the clusters should be (i) present in a web search result snippet a number of times exceed a given threshold, (ii) meaningful and contained in a single sentence covering a specific topic, and (iii) clear by being complete (not partial phrase), long enough and frequent phrase. In addition, stop words that are present in the phrase must be preserved to produce more eligible cluster labels [11].
STC is fast (linear to the number of documents) and incremental thus it is very useful in search results clustering process which is online postretrieval process where time is critical requirement [8]. STC clusters documents or search resultsnippets containing common phrases (sequence of words or single terms) and uses information about frequency and order of terms in the documents. STC works in two main phases namely: (i) base cluster discovery using a suffix tree and (ii) merging base clusters into proper clusters. Firstly, STC summarizes document contents and extracts phrases to be assigned then as cluster labels and thus produces concise and meaningful cluster labels [6] depending on candidate frequent phrases describing the main topic covered by the document contents. Secondly, STC assigns snippets to each of these labels to form proper clusters. Thresholds are used to manage the clustering process but tuning these thresholds is often problematic [6].
In the work described in [12], documents are also treated as strings (sequence of words) and similarity between documents is computed using string-kernel function where similarity between two documents is the number of matching subsequences. More shared substrings (not always contiguous) means more similar documents. To grouping the documents, Spectral clustering is used which is a graph-based clustering algorithm where in short, the clustering problem is a graph cut problem to isolate set of nodes from others in the collection.
In general, there are three essential steps for any WSRC method [13] listed as follows:
Retrieve a list R = (r1, r2, ⋯, rn) of n search results for the user query q.
Cluster R to form a list C = (C0, C1, ⋯, Cm) of m + 1 clusters.
Label clusters.
The method described above uses each created cluster to extract a meaningful label to be assigned as a good descriptor for that cluster while in [14], for example, labels are induced first and then clustering is performed by assigning snippets to the closest preextracted label. This is the same in the Lingo “description comes first” approach which uses frequent phrases to induce distinct enough labels to cover as much topics as possible, and after that the clustering is performed by assigning each snippet to the closest label [8, 11]. Steps for “description comes first” approach are listed briefly as the following:
Preprocessing the input snippets by performing tokenization, stemming, and stop-words removal.
Extracting frequent words and phrases in the input snippets.
Inducing cluster labels by employing singular value decomposition (SVD).
Assigning snippets to each of these labels to form proper clusters.
Postprocessing like clusters merging and pruning.
In addition to clustering documents automatically in acceptable time, it is essentially to assign a meaningful and comprehensible label to each cluster to describe the semantic topic covered by that cluster concisely. Labelling is not a priority in traditional data mining approaches which is mainly concerned in grouping data precisely and efficiently. While WSRC is concerned in making search results easier to brows by grouping search results in well-described clusters [6] in order to make it easier to locate the required documents and even unexpected relevant documents by reviewing certain cluster [3].
3. CLUSTERS LABELLING
Extracting relevant terms for labelling clusters and act as readable, meaningful and distinguishing group descriptor is a challenging process especially in WSRC where search results snippets (small portion of text) contain few terms. The high locally frequent and low globally frequent term in a cluster is typically good representative label for that cluster [3]. Terms can be weighted using local and global factors as the following:
Local Factor:
FCt is the frequency of documents containing term t in cluster C. Logarithmic frequency is used to avoid FCt high-frequency problem.Global Factor:
FRt is the frequency of documents containing term t in search results R.
Label selection criterion combines local and global factors to calculate scores for terms in each cluster as the following:
For each cluster, the term with the highest score will be selected as the cluster label.
[15] used Lingo algorithm to extract frequent phrases and original terms in addition to synonym terms from WordNet lexical database, in order to induce better abstractive labels for clusters. Other external knowledge resources like Wikipedia †can be used to enrich the candidate label with new meaningful terms imported from the online free encyclopedia which contains a huge amount of “controlled” preclustered and manually annotated contents [4].
[16] proposed an approach to extract and combine significant bi-grams into n-grams according to term co-occurrence statistics and use the top-ranked unredundant phrases as candidate labels. To retrieve significant bi-grams, for each pair of words <w, wi>, strength is computed as the following:
Word pairs with strength value < the threshold β0 will be discarded.
Also spread is computed as the following:
Now, bi-grams will be used to discover n-grams. Each bi-gram <w, wi> will be represented in a graph as a directed edge and the two words will be the vertices. A tri-gram “abc” is identified if the edges a → b, b → c, a → c exist.
Depth-first traversal to all nodes results in extracting all the n-grams. After that, redundant n-grams need to be eliminated and only unredundant n-grams will be used as candidate cluster labels. Removing the redundancy in n-grams can be performed by applying remove-or-merge process.
Let ts(p) be the term set of n-gram p, ss(p) be the sentence set of p, and ω0 be a threshold. The remove-or-merge condition is defined as:
Each candidate cluster label p is ranked by its significance (Sig(p)) as the following:
The top M candidate cluster labels are selected to construct base clusters. All snippets containing the same label (phrase) are aggregated in a base cluster labelled by the phrase.
Even though it is generated automatically, evaluation of clusters labels may be better to be conducted against manually created gold standard data where human annotators are asked to identify the fittest cluster given a cluster label [17].
4. STC CLUSTERS LABELLING ENHANCEMENT
The enhancement process is founded on the idea of using the existing labels nominated by the standard STC algorithm. The original labels and/or clusters will be modified and combined so that it become more concise and descriptive. To this end, the propose methodology will be conducted on the original STC algorithm to produce an enhanced version of the classical STC algorithm. The proposed methodology employed a deeper linguistic analysis and more robust techniques (as seen in Algorithm 1) than that used in other research works like, for example, the work described in [18].
Once the raw original labels are induced using STC algorithm all the cluster label phrases and clusters will be processed with respect to the Algorithm 1. The aim of this algorithm is to enhance f1, f2, f3, f4, and f5 (see Section 5 for details) by refining and reformulating both of labels and clusters. The major steps are described Algorithm 1.
5. CLUSTERS LABELLING QUALITY EVALUATION
Labels for web search results clusters should be discriminatory and carefully describe the contents of individual clusters. Low-quality labelling for web search results clusters may confuse the user and mislead him during navigation through clusters and thus negatively affect the whole process aiming to meet the user information needs [18]. In this section, a discussion concerning the evaluation of the generated labels for the produced clusters of web search results is presented. This is important for generating descriptive and precise labels for clusters and/or conducting a comparison concerning the descriptiveness of different labelling techniques.
Clusters labelling quality measures can be conducted as an external measure according to the source of the “validity criteria.” External measure compares the clustering algorithm’s results against external, manually, or automatically, prelabelled results in order to compare the difference between the two results. Many labelling quality measures have been proposed in different contexts in the literature. [18] introduced a new metric to evaluate the quality of clusters labels using a comparative evaluation strategy. The authors in [18] argued that, to be responsible, clusters labelling evaluation should take into consideration the following five parameters:
Algorithm 1 Labels Enhancement and Clusters Refinement

Comprehensibility (f1): A cluster label should give a clear interpretation for the contents of a cluster to the user. It can be formally defined as
The exponential expression in Equation (7) is used to penalize too short or too long phrases by setting |p|opt = 4 and d = 8. [19].
Descriptiveness (f2): All documents in a cluster should contain the label associated with that cluster. It can be formally defined as:
Discriminative Power (f3): A cluster label should only exist, exclusively, in documents from its associated cluster. It can be formally defined as:
Where ci and cj are two clusters while dfc(p) represents the number of documents in a cluster containing the phrase p.Uniqueness (f4): Each cluster label should be uniquely associated with one cluster. It can be formally defined as:
Where p is a phrase and lc is the label associated with a cluster.Nonredundancy (f5): Cluster labels can not be synonymous (having the same or nearly the same meaning). It can be formally defined as
Where Syn : p × p →{0,1}.
Label relevancy: Relevance of a phrase with respect to a cluster: All constraints can be combined into a single criterion:
f1 : Comprehensibility
f2 : Descriptiveness
f3 : Discriminative Power
f4 : Uniqueness
f5 : Nonredundancy
Clusters labelling quality measures can be categorized as (i) external, (ii) internal, and (iii) relative measures according to the source of the “validity criteria.” External measure compares the clustering algorithm’s results against external, manuallyor automatically, preclustered results in order to disclose the difference between the two results. While internal measure employs functions to assess the similarity between cluster’s documents in addition to the dissimilarity between resulted clusters without referring to any external information. Relative measure assesses the results by comparing them against results from different algorithms, or compares the results of the same algorithm but under different conditions like different thresholds [20].
6. RESULTS AND DISCUSSION
One of the challenges of work on WSRC is the lack of “ground truth” data. In some cases it is possible to construct such data by hand however this still entails subjectivity and requires considerable resources (to the extent that it is not possible to construct significant benchmark data).
To act as a focus for the work described in this paper, the top-ranked web search results automatically clustered into relatively small thematic collections of documents for the query Donald Trump (see Figure 4). These clustered web search results retrieved from Carrot2 which is an open source WSRC engine (available on: http://search.carrot2.org/stable/search) using STC algorithm.

Clustering and labelling results using the classical Suffix Tree Clustering (STC) algorithm for the query: Donald Trump.
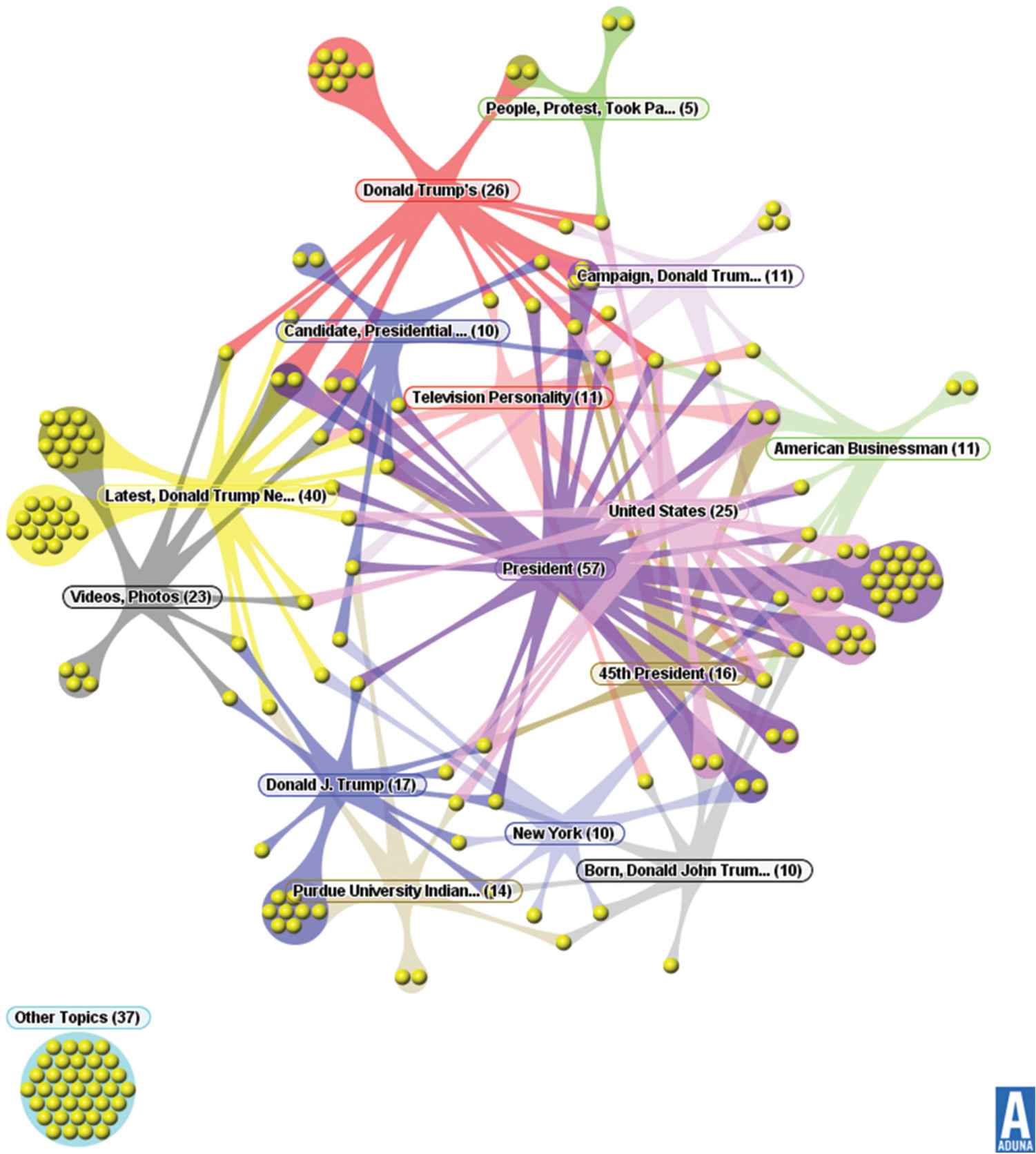
Clusters visualisation for the resulted clusters produced from the Suffix Tree Clustering (STC) algorithm for the query: Donald Trump.
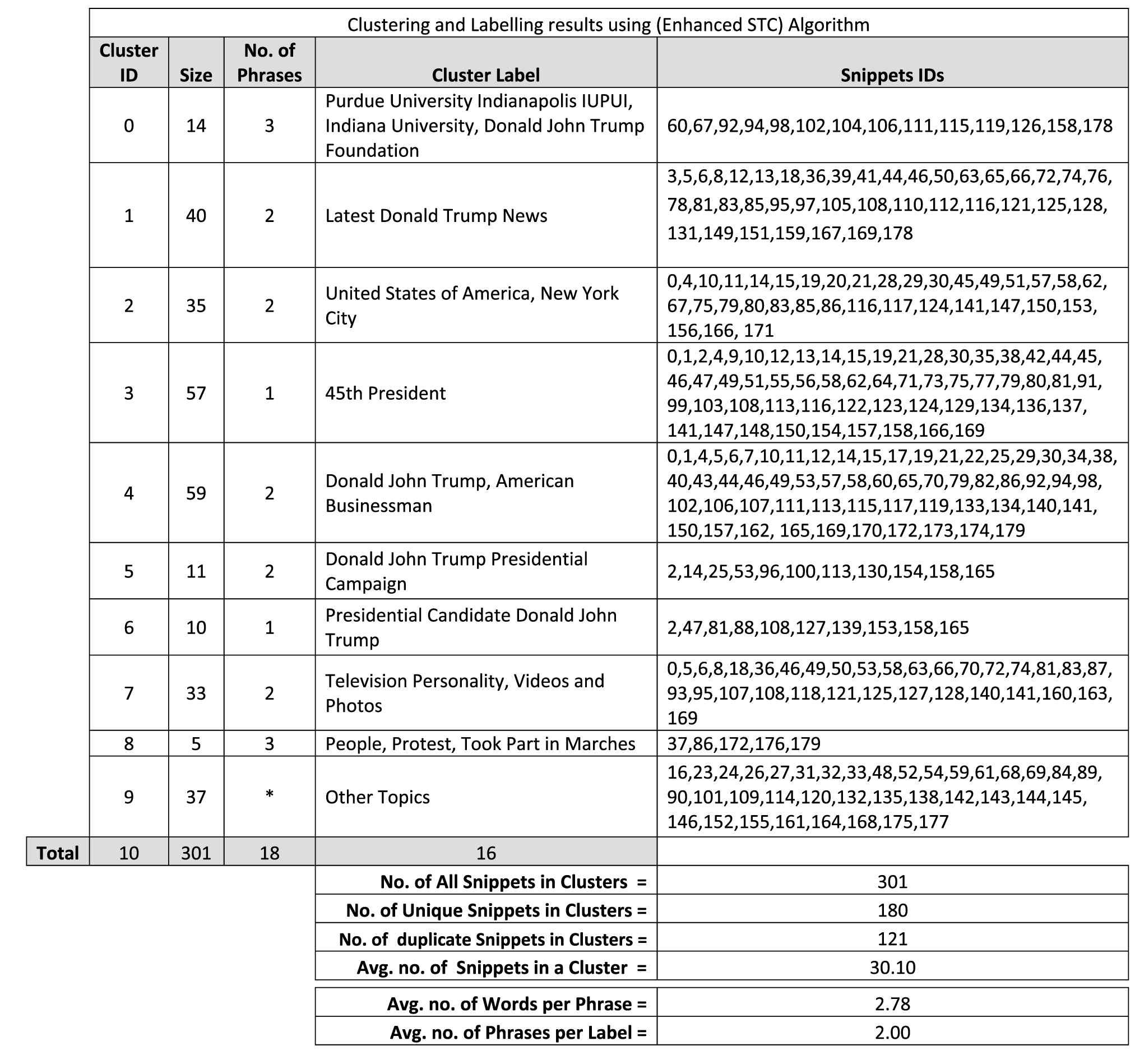
Clustering and Labelling results using the enhanced Suffix Tree Clustering (STC) algorithm for the query: Donald Trump.
To evaluate the proposed methodology the authors compared the reformulated clusters and their enhanced labels with the original clusters and labels generated from the classical STC algorithm. For evaluation, the authors used clusters labelling performancemeasure considered five parameters (as discussed in Section 5). We also had to forget, for the purpose of the evaluation, the numerical “intensity” of the computed values for f1: Comprehensibility, f2: Descriptiveness, f3: Discriminative Power, f4: Uniqueness, and f5: Nonredundancy.
The results are presented in tabular form and show the performance of the proposed methodology to enhance the STC algorithm with respect to the classical STC algorithm. The evaluation shows that the proposed methodology to enhance the STC algorithm performs well with respect to the quality of the enhanced labels for clusters. Inspection of the recorded results in Figure 7 indicates that (i) The proposed methodology achieved better performance and the overall average recorded values for the used performance measure (f6) was 0.921. (ii) Number of clusters was decreased from 15 to clusters only. (iii) Number of duplicated results was decreased from 143 to 121 only, and (iv) average number of phrases per label was increased from 1.67 to 2.00 phrases.
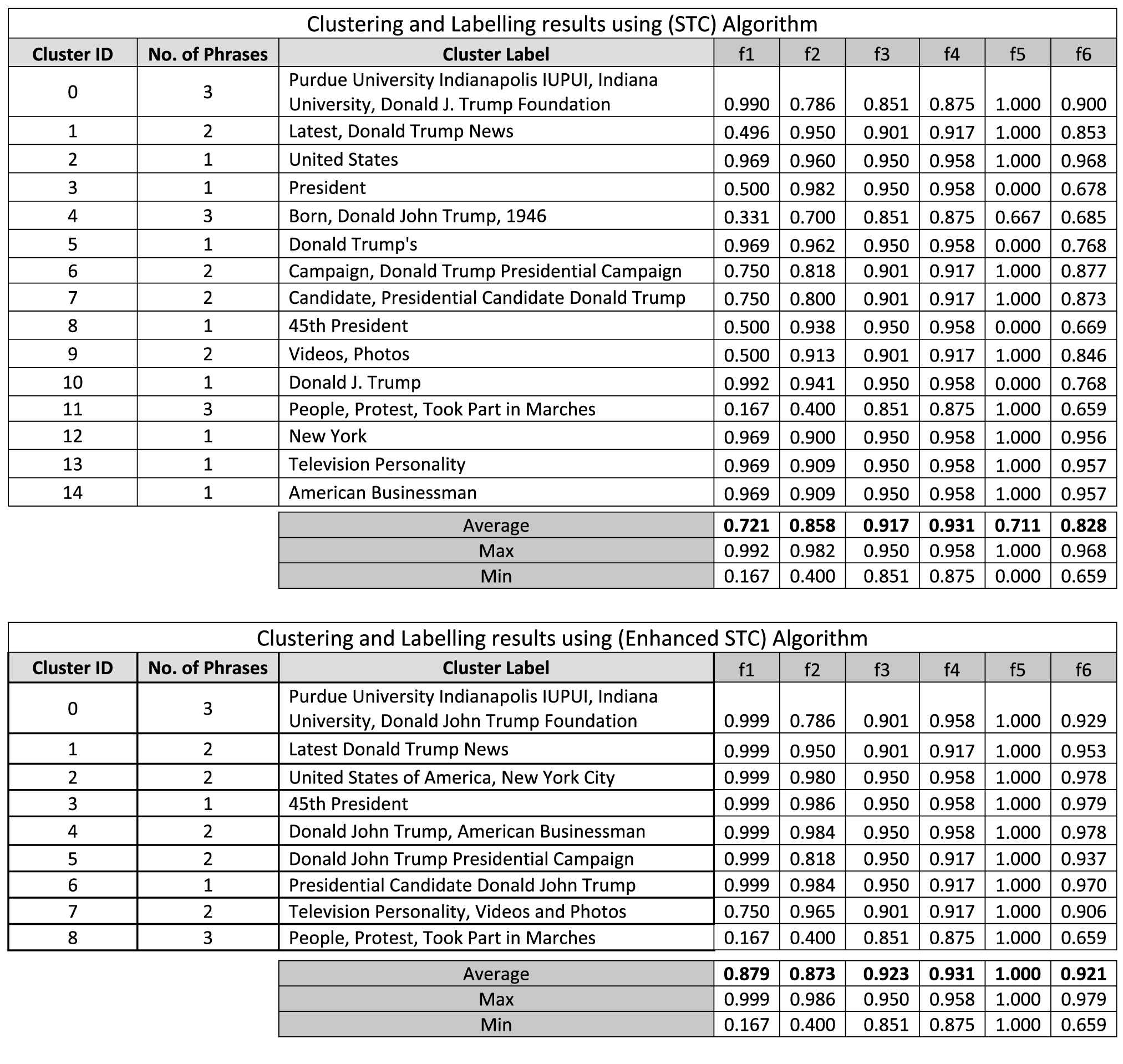
Classical Vs enhanced Suffix Tree Clustering (STC).
7. CONCLUSIONS
In this paper the authors described the proposed methodology for enhancing the classical STC algorithm for clustering web search results. The operation of the proposed methodology was illustrated and evaluated. The objective of this research was to deploydeep linguist analysis techniques for the enhancement of phrase labels that will in turn allow for the reformulation of the structure of web search results clusters and thus produce better performance for web search engines and achieve a better end-user satisfaction. The proposed methodology used the existing labels nominated by the original STC algorithm and adapted that labels and/or clusters to be more concise and descriptive. The propose methodology was conducted on the original STC algorithm to produce an enhanced version of the classical Suffix Tree Clustering algorithm. The enhanced algorithm was experimented and the produced clusters and labels were compared and evaluated with respect to the classical STC algorithm using clusters labelling performance measure considered five parameters f1: Comprehensibility, f2: Descriptiveness, f3: Discriminative Power, f4: Uniqueness, and f5: Nonredundancy. The recorded results indicated that the new enhanced labels outperformed the original labels and the overall performance has been enhanced. The results shown that better performance was achieved (f6 = 0.921), clusters were decreased (from 15 to 9 clusters only), duplicated web search results were decreased (from 143 to 121 only), and average number of phrases per label was increased (from 1.67 to 2.00 phrases).
The promising results obtained so far indicate that (i) it is possible to capture the clusters structure (ii) it is possible to enhance the produced labels from STC algorithm to improve the overall performance by producing more comprehensive and descriptive labels for clusters and thus the user will be able to preview and navigate easily and fast.
Future work will initially be directed at the adoption of deeper linguistic approaches and data mining techniques to enhance other WSRC algorithms like Lingo and K-mean. The intention is also to increase the size of our dataset.
Footnotes
REFERENCES
Cite this article
TY - JOUR AU - Zaher Salah AU - Ahmad Aloqaily AU - Malak Al-Hassan AU - Abdel-Rahman Al-Ghuwairi PY - 2018 DA - 2018/12/31 TI - A Methodology to Refine Labels in Web Search Results Clustering JO - International Journal of Computational Intelligence Systems SP - 299 EP - 310 VL - 12 IS - 1 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.2019.125905647 DO - 10.2991/ijcis.2019.125905647 ID - Salah2018 ER -