
Aggregating Interrelated Attributes in Multi-Attribute Decision-Making With ELICIT Information Based on Bonferroni Mean and Its Variants
- DOI
- 10.2991/ijcis.d.190930.002How to use a DOI?
- Keywords
- ELICIT information; Aggregation operator; Interrelationship; Bonferroni mean
- Abstract
In recent times, to improve the interpretability and accuracy of computing with words processes, a rich linguistic representation model has been developed and referred to as Extended Comparative Linguistic Expressions with Symbolic Translation (ELICIT). This model extends the definition of the comparative linguistic expressions into a continuous domain due to the use of the symbolic translation concept related to the 2-tuple linguistic model. The aggregation of ELICIT information via a suitable rule that reflects the underlying interrelation among the aggregated information in output is the key tool to design decision-making algorithm for solving multi-attribute decision-making problems under linguistic information. In this study, we introduce three aggregation operators for aggregating ELICIT information in aim of capturing three different types of interrelationship patterns among inputs, which we refer to as ELICIT Bonferroni mean, ELICIT extended Bonferroni mean and ELICIT partitioned Bonferroni mean. Further, the key aggregation properties of these proposed operators are investigated with the proposal of weighted forms. Based on the proposed aggregation operators, an approach for solving multi-attribute decision-making problems, in which attributes are interrelated is developed. Finally, a didactic example is presented to illustrate the working of the proposal and demonstrate its feasibility.
- Copyright
- © 2019 The Authors. Published by Atlantis Press SARL.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
With the growing complexity of the socio-economic environment, it is quite common to prevail the uncertainty and vagueness in the decision-making process, in particular, the situations, where human judgments/assessments/perceptions are inevitable to reach a final decision over a set of alternatives [1]. The emergence of such scenarios involving human cognition leads us to use linguistic information based on the fuzzy linguistic approach [2] to effectively manage uncertainty in such decision-making processes. The fuzzy linguistic approach uses fuzzy set theory [3] to manage uncertainty and model linguistic information by using linguistic variables described by Zadeh [2] as “A variable whose values are not numbers but words or sentences in a natural or artificial language.” A linguistic variable is characterized by a syntactic value or label and a semantic value. Whereas the label is a word that belongs to a set of linguistic terms, semantics is provided by a fuzzy set in a discourse universe. Over the years, the fuzzy linguistic approach has been applied successfully in solving many practical multi-attribute decision-making (MADM) problems from the different domains [1,4] and many linguistic computational models have been put forwarded to improve and enhance the information modeling and computation process capability of the Zadeh's approach [2]. They can be broadly classified into two distinct categories: symbolic computational models [5–7] and semantic-based computational models [8]. In terms of simplicity and interpretability, symbolic models stand out semantic models. The symbolic models have evolved enormously over the years. The first proposals [4,9,10] made use of single linguistic variables, for instance, good, horrible, very bad, perfect, to provide the decision makers’ preferences and carried out the linguistic computations. Among these symbolic models, 2-tuple linguistic computational model [4,5], which enhanced the interpretability of the fuzzy linguistic approach by introducing the concept of symbolic translation, has got wide speared acceptance among the community and successfully applied in solving the MADM problems [11,12]. However, in spite of many of these approaches have been applied successfully in decision-making problems, the modeling of linguistic information is limited when experts provide their preferences by using just single terms. To overcome this drawback, several proposals that obtain richer linguistic expressions than single linguistic terms have been proposed [13]. One of the most outstanding proposals is the so-called Hesitant Fuzzy Linguistic Term Sets (HFLTSs) [14], which were introduced to model the hesitancy of the experts when they doubt among several linguistic terms at the same time. HFLTSs are also based on the fuzzy linguistic approach that will serve as bases to increase the flexibility of the elicitation of linguistic information. An example of HFLTS might be
In the same way that representing information in the decision process is key, the aggregation of such information, which comes from different sources via a suitable rule (aggregation operator), plays also a pivotal role in decision-making process by combining several pieces of information into a single information, which represents overall overview [22]. In the context of MADM, aggregation operators are generally used to find overall performance of the alternatives from their performances against the predefined set of criteria. The need of modeling specific interaction among the attributes and computational formalization with different types of linguistic information to conduct decision-making process under specific linguistic environment were the cornerstone behind the development of several classes of aggregation operators in MADM context.
In this vein, to aggregate interrelated linguistic information represented by 2-tuple linguistic information, several 2-tuple linguistic aggregation operators have been proposed in the literature [4,23–27]. On the other hand, to fuse linguistic information, expressed by HFLTSs, many aggregation operators have been developed considering the nature of the interaction (independent/interrelated) among the aggregated HFLTSs [28–33]. Despite many successful uses of the hesitant fuzzy linguistic computational model in decision-making, it has limitations in modeling complex linguistic expressions by HFLTS [34] and can be overcome with the capability of ELICIT expression. The use of ELICIT information in the decision-making makes it necessary to consider the issue of aggregation of ELICIT information. In this view, Labella et al. [21] defined an aggregation operator, which we can refer to as ELICIT arithmetic mean, to aggregate ELICIT expressions in the decision-making process. However, the proposed aggregation operator does not consider the interrelationship among the aggregated ELICIT expressions that are connected with the underlying interrelationship structure of associated concepts/objects, like the attributes’ interrelationship and the corresponding ratings. Further, considering the importance/weights of the inputs in the aggregation process is vital to take into account in many decision-making processes and that have not been considered by Labella et al.[21]. Therefore, in spite of ELICIT information advantages, there is an evident lack of proposals about ELICIT aggregation operators that consider the interrelation among the ELICIT expressions and their importance in the aggregation process. For this reason, this study aims:
Develop several aggregation operator to aggregate ELICIT information by capturing different interrelationship patterns (homogeneous, heterogeneous and partitioned structure) among the aggregated arguments.
Capture the homogeneous relationship among ELICIT expressions by developing the ELICIT Bonferroni mean (ELICITBM) operator.
Reflect the heterogeneous interaction among the aggregated ELICIT expressions by developing the ELICIT extended Bonferroni mean (ELICITEBM) operator
Capture the partitioned structured interrelationship among aggregated ELICIT expressions by developing the ELICIT partitioned Bonferroni mean (ELICITPBM) operator.
Study the proposed aggregation operators properties and weighted form to take into account weight information in the aggregation process.
Based on the proposed aggregation operators, present an approach for solving MADM problems in which attributes follow the different interrelationship patterns.
To this end, the paper is organized as follows. In Section 2, we provide a brief primer of classical aggregation operator that captures interrelationship of among the aggregated arguments along with fuzzy set theory. A brief overview of the ELICIT representation and computational model is also included in Section 2. In Section 3, we develop three aggregation operators to fuse the ELICIT information according to their underlying interrelationship structures, namely, ELICITBM, ELICITEBM and ELICITPBM. The key properties of these operators are also studied along with the weighted forms: ELICITWBM, weighted ELICITEBM (ELICITWEBM) and WELICITPBM. In Section 4, an aggregation operator-based approach to solving the MADM problems, in which attributes are interrelated with different patterns is proposed. A didactic example is presented in Section 5 to illustrate the working of our approach and feasibility. Finally concluding remarks are made in Section 6.
2 PRELIMINARIES
In this section, we overlay the key concepts related to Bonferroni mean (BM), arithmetic operational laws of fuzzy numbers and ELICIT information for easy understanding of our subsequent proposals on aggregation of interrelated ELICIT information and linguistic decision-making process.
2.1 Aggregation Operators for Interrelated Information
In this section, we briefly introduce the BM and its variants, which are capable of capturing different kinds of interrelationship patterns among the aggregated information. We start by recalling the definition of the BM operator.
Definition 1.
[35] Let
Although, BM was introduced by Bonferroni [35] in 1950, it is analyzed and interpreted in decision-making context by Yager [36]. Specifically, BM captures a homogeneous interrelationship pattern among the inputs that every input
Definition 2.
[25] For any
Partitioned Bonferroni mean (PBM) is another variant of BM, which is capable of capturing partition structure interrelationship pattern among the input set in the aggregation process and reflects it in the aggregated value [24]. In the following, we provide a brief description of the specific partition structure interrelationship pattern and PBM operator.
Let a
Definition 3.
[24] For
It is evident from the Definitions 1 and 3 that BM is a special case PBM when all the inputs belong to same class [24]. To establish more concrete link between BM and PBM, we can write Eq. (3) as follows:
2.2 Arithmetic Operations of Fuzzy Numbers
In this section, key concepts associated with the fuzzy numbers and their operational laws are briefly described. We start by recalling the definition of a fuzzy set, which is well known to model the concept that does not possess the sharp boundaries. Throughout this article, we will restrict ourselves to the class of fuzzy sets over the universe of discourse
Definition 4.
[3] A fuzzy set
A fuzzy set
Definition 5.
[3] The support of the fuzzy set
Definition 6.
[37] A fuzzy set
Definition 7.
[37] A fuzzy set
Definition 8.
[37] A fuzzy number
As a fuzzy set is completely characterized by its membership function, we can say the membership functions are synonyms of the fuzzy sets. Although any function
Definition 9.
A trapezoidal fuzzy number (TrFN)
Definition 10.
A triangular fuzzy number (TFN)
The obvious motivations behind the use of trapezoidal and TFNs come from the simplicity of the membership functions and their characterization requires reasonably limited information about the linguistic term [38,39]. For example, when a triangular
The fuzzy arithmetic operational laws allow us to facilitate the computation over linguistic information. There are several ways to derive the arithmetic operational laws of the fuzzy numbers based on the Zadeh's extension principle [37]. As in the ELICIT computational model [21] the meaning of the primary linguistic term sets are represented by using TFNs or TrFNs, we restrict ourselves on fuzzy arithmetic operational laws, which preserve the shape of the original fuzzy numbers. In this view, we adopt Chen's function principle based arithmetic operational laws, which is given as follows [40]:
Definition 11.
Let
Addition:
Multiplication:
Scalar multiplication:
Exponent:
Note that the function principle based arithmetic laws differ from extension principle-based arithmetic laws in multiplication operation as the former approximate resultant fuzzy number shape. Further, one may observe that with the increment of the number of aggregated fuzzy numbers in the aggregation process, the difference between function principle based aggregation and extension principle based aggregation results diminishes.
2.3 ELICIT Information
Despite the evolution of the symbolic approaches over the time [4,14,16], there exists several drawbacks in terms of interpretability and/or accuracy. ELICIT information allows us to keep the interpretability and precision of the results in MADM problems under linguistic environments thanks to the extension of CLEs into a continuous domain. To carry out such extension, the ELICIT expressions are generated by means of a context-free grammar by using the symbolic translation concept used by the 2-tuple linguistic model.
Definition 12.
[21] Let
The production rules defined in an extended Backus–Naur Form are:
Therefore, the possible ELICIT expressions generated according to the previous context-free grammar are: “at least
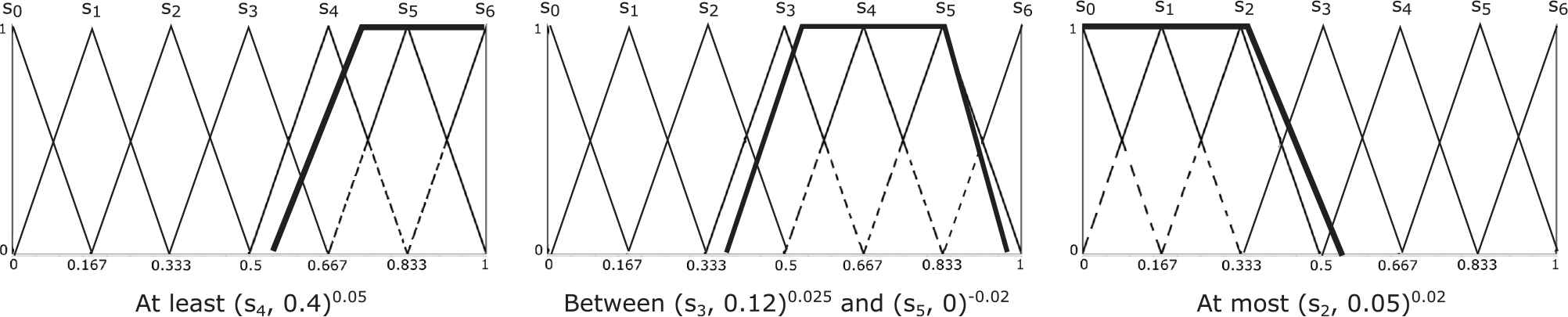
ELICIT information examples.
To obtain linguistic results represented by ELICIT information in decision-making processes, a novel approach was introduced in [21]. This approach starts from linguistic preferences provided by the experts modeled by CLEs and/or ELICIT information. Afterward, CLEs and ELICIT information are transformed into TrFNs. Whereas the CLEs are transformed into TrFNs through the computation of their fuzzy envelope [18], the transformation of the ELICIT information into TrFNs is carried by means an inversefunction.
Definition 13.
[21] Let
Such that, from an ELICIT expression, it returns its equivalent TrFN.
In this point, the adjustment,
At least expression: The function
Definition 14.
[21] Let
At most expression: The function
Definition 15.
[21] Let
Between expression: The function
Definition 16.
[21] Let
Remark 1.
Appendix A.1 has been included in order to show the performance of
Once the TrFNs are obtained, they are manipulated and aggregated by means of fuzzy operations that keep the fuzzy parametric representation of such TrFNs [41]. Finally, the resulting TrFNs, noted as
Identify relation: The relation of the ELICIT expression is determined by the fuzzy number
Definition 17.
Let
For sake of space, it is assumed that the ELICIT expression is composed by a “between” relation (see [21] for further detail about the construction of other ELICIT expressions).
2-tuple linguistic terms computation: The ELICIT expression with the relation “between” is composed by two continuous primary terms
Compute linguistic terms: To select the linguistic terms
The ELICIT expression so far is “between
Compute symbolic translations: According to [4,43],
The ELICIT expression so far is “between
Compute adjustments: The steps to compute the adjustments for the ELICIT expression are:
Compute HFLTS: The HFLTS of an ELICIT expression whose relation is between would be composed by:
Compute fuzzy envelope: The fuzzy envelope [18] of the computed HFLTS is computed and noted as
Compute adjustments
Finally, the ELICIT expression is completed “between
Remark 2.
Appendix B.1 has been included in order to show the retranslation process through a practical example.
3 AGGREGATION OF INTERRELATED ELICIT EXPRESSIONS
The fusion of linguistic information that is represented by CLEs and/or ELICIT expressions according to underlying interrelationship structure of the information is essential to design a variety of linguistic decision-making processes. In this section, we extend the classical interrelated aggregation operators described in the previous section to aggregate the ELICIT expressions with certain underlying interrelationship pattern. From now onward, we are going to use
3.1 ELICIT Bonferroni Operators
Based on the Definition 1, the homogeneously interrelated ELICIT expressions can be aggregated as follows:
Definition 18.
Let
Based on the arithmetic operational laws of fuzzy numbers, we illustrate the computational formula of ELICITBM in the following theorem:
Theorem 1.
Let
Proof.
Please see Appendix C.1
Remark 3.
With the notation of the BM operator, the computational formula for ELICITBM (Eq. 16) can be rewritten as follows:
Example 1.
Let us consider the aggregation of homogeneously interrelated ELICIT information:
From Eq. (1), we have
By utilizing Eq. (11) with the retranslation steps of ELICIT information, we obtain
Theorem 2.
The ELICIT expressions aggregation operator
- where
Proof.
Please see Appendix C.2.
Theorem 3.
Let
Proof.
Please see Appendix C.3.
In the above, we have not considered the weight of the aggregated ELICIT expressions. But, in many practical applications, we need to consider the weight of input arguments in the aggregation process. In this view, we define the weighted form of ELICITBM as follows:
Definition 19.
Let
With the operational laws of the fuzzy numbers, we derive the computational formula of the
Theorem 4.
Let
Proof.
It follows in the lines of Theorem 1.
3.2 ELICIT Extended Bonferroni Mean
This section focuses on aggregating ELICIT expressions that are heterogeneously interrelated in the fashion described in Section 2 and define ELICITEBM operator as follows:
Definition 20.
Let
For the computational purpose, we derive the explicit mathematical formulae based on the arithmetic operational laws of TrFNs and ELICIT computational model as follows:
Theorem 5.
Let
It is not difficult to show that ELICITEBM satisfies commutative, idempotency and ratio-scale invariant properties of the aggregation operator as those properties holds for classic EBM. Further, it is bounded by
Definition 21.
Let
The explicit computational formula of ELICITWEBM could be obtained by using the arithmetic laws of fuzzy numbers with ELICIT computational model and summarized in the following:
Theorem 6.
Let
3.3 ELICIT Partitioned Bonferroni Mean
In this section, we consider the aggregation of ELICIT expressions, which follows a partitioned structure interrelationship pattern described in Section 2. Based on the fact in Eq. (4) and Definition 18, we define ELICITPBM operator in the following:
Definition 22.
Let
From the Definition 22, we note that by repeated application of ELICITBM over the partitions of the input set we can obtain the aggregated value of ELICITPBM. The more explicit computational formula to find the aggregated value of the ELICICTPBM in terms of BM is given below:
Theorem 7.
Let
As the ELICITPBM operator is composed of a set of ELICITBM operators with different dimensions, we can easily exhibit that the ELICITPBM operator satisfies commutative, idempotent and ratio-scale invariant properties with help of Theorem 2. Further, the ELCITPBM operator is bounded as follows:
When the inputs ELICIT expressions have different relative importance, we need to take account it in the aggregation process and to reflect on the aggregated value. In this view, the weighted form of the ELICITPBM can be defined as follows:
Definition 23.
Let
Theorem 8.
Let
4 APPROACHES TO MADM WITH ELICIT ASSESSMENTS
In this section, we develop an approach based on ELICIT expressions aggregation operators to solve MADM problem in which attributes follow a typical interrelationship pattern, and the decision maker provides his/her assessments by using CLEs and/or ELICIT expressions.
We consider a typical MADM problem, where a finite set of alternatives are evaluated against a predefined set of performance measuring attributes in the aim of ranking the alternatives from best to worst on their suitability. In such a decision-making problem two pieces of information are required to find the ranking of the alternatives. One is assessment information of the alternatives against the criteria, which we often refer to as decision information. Another one is related to the relative importance of the criteria that is referred to as weight information. Mathematically, we can describe the MADM problem with all the relevant information as follows:
A finite set of
A fixed set of criteria:
The weight vector of the criteria:
The alternatives are assessed over criteria and evaluations are summarized in the following decision matrix:
where
Apart from these binding pieces of information, the decision maker needs to provide the typical pattern of the interrelationship among the attributes. As interrelationship is vital in the selection of an appropriate aggregation operator, this information is crucial to make a reliable decision.
With this available information in hand, we intend to design an algorithm based on the aggregation operators, developed in the previous section, to find the most desirable alternative(s) from the alternatives’ pool
Step 1
Give the decision maker's preference summarized in the decision matrix
Step 2
Provide the interrelationship patter among the attributes, i.e., whether, the attributes follows homogeneous interrelationship pattern, heterogeneously interrelation patter or partitioned structured interrelationship pattern. In the cases of heterogeneous and partitioned interrelationship, specific structure of interrelationship data need to be provided.
Step 3
Based on the interrelationship pattern, the suitable aggregation operator is selected to obtain the overall performance of the alternative
attributes are homogeneously related in this case, we utilize ELICITBM operator to find the alternatives
whereattributes are heterogeneously interrelated, in this case, we employ ELCITWEBM operator to obtain overall performance
where,attributes are partitioned structured, in this case, WELCITPBM operator is utilized to obtain overall performance
where,
Step 4
The overall performance of the alternatives
Step 5
Based on the
5 PRACTICAL EXAMPLE
In this section, we provide a practical example to demonstrate the working and feasibility of the proposed decision-making algorithm.
In the face of a trade war, a major company is considering to shift its manufacturing plant from the current location. After, initial screening the company has identified five possible locations around the world to step up the new manufacturing plant. We name this potential locations as
Due to the presence of vagueness and uncertainty, the decision maker uses linguistic information to assess the locations against the attributes. According to the expertise of the decision maker, a linguistic term set with
Decision maker uses a single linguistic term or complex linguistic expression, modeled by CLEs to rate the alternatives against the attributes. The decision maker's preferences are represented by CLEs (Table 1Rating in CLEs) that are transformed into ELICIT information and modeled by the decision matrix
| at least S | at least VS | S | S | at least F | at least S | bt F and S | |
| at most VUS | F | bt F and S | bt UF and VUS | at least F | F | F | |
| VS | at least VS | S | VS | bt US and F | at most F | F | |
| UF | UF | VUS | bt F and S | at most US | F | US | |
| E | F | E | at least S | US | bt S and VS | VS |
bt = between.
Alternatives rating under different criteria.
Further all performance measuring attributes are not equally important. To take into account the variation in relative importance of the attributes, weight information is set as
With this available information about the locations’ choices problem, we employ the proposed decision-making algorithm to prioritize the locations and to find the most suitable one.
Step 1
To carry out the linguistic computations, all the ELICIT expressions are required to transform into machine manipulative format, i.e., TrFNs. Decision maker's opinions in terms of ELICIT expressions given in
Step 2
From the description of the attributes interrelationship pattern, it is quite evident that the attributes are heterogeneously related with no independent arguments. In the aim of capturing this heterogeneous interaction among the attributes and its reflection in the aggregated value, we choose ELICITWEBM (Eq. 29), to compute the overall performance of the alternatives. We set the associated parameter
| Alternative | ||
|---|---|---|
| between |
||
| between |
||
| between |
||
| between |
||
| between |
Alternatives overall performance.
Step 3
From the overall performances
In the above analysis, we have set the parameters associated with ELICITWEBM as
| Alternative | |||||
|---|---|---|---|---|---|
Percentage of occupying different ranking positions by alternatives.
As we have emphasized on the fact that capturing the underlying interrelationship pattern in the aggregated ELICIT information is vital to make a reliable decision, it is worthy here to investigate the consequence if we do not consider the interrelationship in the information fusion process. For this purpose, we use the weighted ELICIT arithmetic mean operators, which assume that the input arguments are independent, in place of ELICITWBM in the proposed decision-making algorithm to compute the overall performances of the alternatives. Rest of the steps in our proposed MADM algorithm to find the ranking of the alternatives is kept unaltered. With this new configuration of the algorithm, we re-execute the step of the MADM algorithms and found the following ranking order of the alternatives
6 CONCLUSION
In this study, we have investigated the aggregation of linguistic information that is represented by ELICIT expressions and followed some specific interrelationship patterns. Specifically, we have considered three types of interrelationship patterns, namely, heterogeneous, homogeneous and partition structure among the aggregated arguments and such relationships are captured via direct conjunctions among the aggregated arguments with the core of three classical aggregation operators: BM, EBM, and PBM. In this view, we have extended these classical operators in ELICIT information environment and developed three new aggregation operators for aggregation ELICIT expressions, which we have referred to as ELICITBM, ELICITEBM, and ELICITPBM. Furthermore, we have investigated the properties of these aggregation operators and proposed the weighted form of these aggregation operators to deal with the situations where inputs have different relative importance. Using these aggregation operators as an information fusion tool, an algorithm for solving the MADM problems, in which attributes follow some specific interrelationship patterns, has been develped. Finally, we have presented numerical examples to illustrate the feasibility and applicability of our proposed approach.
In the future, it would be interesting to investigate the more complex interaction among the ELICIT expressions via Choquet integral [47]. Further, one may consider extending the aggregation of ELICIT expressions for other class of averaging aggregation operators, such as ordered weighted average operators [48], power averaging operator [49], prioritize aggregation operator [50] and their different variants.
CONFLICT OF INTEREST
The authors declare that they have no conflict of interest.
AUTHORS' CONTRIBUTIONS
Bapi Dutta, Alvaro Labella, Rosa M. Rodriguez, and Luis Martinez did the conceptualization, methodology, validation, review writing, and editing. Bapi Dutta and Alvaro Labella wrote the original draft.
ACKNOWLEDGMENT
This work is partially supported by the Spanish Ministry of Economy and Competitiveness through the Spanish National Research Projects TIN2015-66524-P and PGC2018-099402-B-I00 and the Postdoctoral fellow Ramón y Cajal (RYC-2017-21978).
APPENDIX A
A.1 ELICIT Inverse Function Example
In order to facilitate the understanding of the inverse function,
Extended Comparative LInguistiC Expressions with SymbolIc Translation (ELICIT) information examples.
First, it is necessary to compute the fuzzy envelope [18] of the ELICIT expression. To do that, the HFLTS of the expression is obtained through the transformation function defined in [21]:
For our example:
Once the HFLTS is computed, the different fuzzy memberships functions of the linguistic terms that belong to the HFLTS are aggregated with the OWA operator [48]. The OWA operator assigns different importance to the linguistic terms that compose the HFLTS through the orness measure thus, the way of computing the OWA weights affect directly to the resulting fuzzy envelopes. This process is carried out in [21] by means of a parameter, noted as
Finally, the corresponding TrFN of the respective ELICIT expression is obtained by applying Prop. 16:
APPENDIX B
B.1 ELICIT Retranslation Process Example
In order to facilitate the understanding of the retranslation process to obtain an ELICIT expression from a TrFN, let us suppose the TrFN computed in A.1,
Identify relation: The relation of the ELICIT expression is determined by the fuzzy number
According to the fuzzy number
2-tuple linguistic terms computation (see Figure B.1): The ELICIT expression with the relation “between” is composed by two continuous terms,
Compute linguistic terms: First, we select the linguistic terms
The ELICIT expression so far is “between
 Figure B.1
Figure B.1Select linguistic terms.
Compute symbolic translations: Once the linguistic terms have been selected, the symbolic translations of the continuous terms are computed as follows:
The ELICIT expression so far is “between
Compute adjustments: Finally, to complete the ELICIT expression, we compute the adjustments for the ELICIT expression following the steps below:
Compute HFLTS:
Compute fuzzy envelope (see Figure B.2): The fuzzy envelope [18] of the HFLTS
 Figure B.2
Figure B.2Extended Comparative LInguistiC Expressions with SymbolIc Translation (ELICIT) fuzzy envelope.
Compute adjustments
Finally, the ELICIT expression is completed “between
APPENDIX C
C.1 Proof of Theorem 1
By using operational laws of fuzzy numbers, we have
Clearly, the right-hand side of Eq. (C.1) is a TrFN due to the assumption
With the help of scalar multiplication laws of TrFNs, we get
Finally by using exponential operational laws of TrFN from Eq. (C.3), we obtain
Since
It infers that
C.2 Proof of Theorem 2
(i) First we will show that
The values of the parameters
It follows that
(ii) Now we will show that
Since the BM operator is idempotent, i.e.,
(iii) Now we will prove that
As the BM operator is ratio-scale invariant i.e.
C.3 Proof of the Theorem 3
We will show that ELICITBM is bounded. Since
Similarly, we can obtain
From these inequalities, we have
Note that the inequality Eq. (C.10) is in the sense of lexicographic ordering of TrFNs, i.e.,
Similarly, we can show that
Hence the result.
REFERENCES
Cite this article
TY - JOUR AU - Bapi Dutta AU - Álvaro Labella AU - Rosa M. Rodríguez AU - Luis Martínez PY - 2019 DA - 2019/10/21 TI - Aggregating Interrelated Attributes in Multi-Attribute Decision-Making With ELICIT Information Based on Bonferroni Mean and Its Variants JO - International Journal of Computational Intelligence Systems SP - 1179 EP - 1196 VL - 12 IS - 2 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.190930.002 DO - 10.2991/ijcis.d.190930.002 ID - Dutta2019 ER -