
Exploring Fuzzy Rating Regularities for Managing Natural Noise in Collaborative Recommendation
- DOI
- 10.2991/ijcis.d.191115.001How to use a DOI?
- Keywords
- Recommender systems; Natural noise; Regularities; Fuzzy logic
- Abstract
Recommender systems have played a relevant role in e-commerce for supporting online users to obtain suggestions about products that best fit their preferences and needs in overloaded search spaces. In such a context, several authors have proposed methods focused on removing the users' inconsistencies when they rate items, so-called natural noise, improving in this way the recommendation performance. The current paper explores the use of rating regularities for managing the natural noise in collaborative filtering recommendation, having as key feature the use of fuzzy techniques for coping with the uncertainty associated to such scenarios. Specifically, such regularities are used for representing common rating patterns and thus detect noisy ratings when they tend to contradict such patterns. An experimental study is developed for showing the performance of the proposal, as well as analyzing its behavior in contrast to previous natural noise management procedures.
- Copyright
- © 2019 The Authors. Published by Atlantis Press SARL.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
Recommender systems (RSs) have become an outstanding tool for providing personalized information about items (e.g. movies, books, e-services) in overloaded search spaces [1,2]. In such spaces, the huge amount of items make difficult to users the task of choosing the most suitable items according to their current preferences and needs. RSs are then highly appreciated for facilitating the access to the right information for each individual user.
Different paradigms have driven the development of RSs in which two of them outstand over the others: (i) content-based approaches [3], focused on suggesting items with similar features to those preferred in the past by the current user; and (ii) collaborative filtering approaches [4,5], focused on suggesting items preferred in the past by other users which have similar preferences to the current user. Beyond these paradigms, several authors have referred to other paradigms such as social, knowledge-based or hybrid filtering [6], taking into account the information sources and techniques that were used to generate the desired recommendations.
The majority of the recommendation approaches assume that the user ratings are free of inconsistencies, and are then focused on proposing new methods centerd on directly improving the recommendation accuracy. However, some recent research works reveal that such ratings can be either inconsistent or noisy, and it has been pointed out the existence of a “magic barrier,” which can limit the reaching of recommendation improvements due to such rating inconsistencies [7]. Several authors have shown that these inconsistencies can be caused by users' personal conditions, social influences, emotional states, contexts, or certain rating scales [8]. Due to the fact that they appear without a malicious or premeditated intention, such inconsistencies have been coined as natural noise by the research community.
Natural noise management has then become a key aspect to improve the performance of RSs. In this way, the research works in this area can be divided in two groups: (i) those that need additional information beyond the rating values to perform the noise management [9–12], and (ii) those that are able to perform the noise management using as input only the preferences values [13–15]. While there are several research efforts associated to the first group, there are still few research works belonging to the second one.
This work is focused on the proposal of a new approach for natural noise management that takes as initial input only the user preference values, and retrieves a de-noised dataset that leads to the improvement of the recommendation performance. Furthermore, it manages the uncertainty associated to the recommendation scenario through the use of fuzzy concepts. With this goal in mind, the approach introduces the concept of rating regularity. Even though, this concept has not had a common use in RSs research, it is closely related with frequent itemsets and association rules in the RS scenario [16–18], which have had a wider application by the research community.
Specifically, the main contributions of the paper consist of:
Introducing the rating regularity concept in the collaborative filtering scenario, as a tool for capturing common behaviors that could be useful in the detection of anomalous rating patterns that could result in natural noise.
Introducing a fuzzy transformation for the rating values as well as for rating regularities, that takes into account the uncertainty associated to the RS scenario.
Presenting an approach for noise degree calculation, based on the identified regularities after their fuzzy transformation.
Validate the proposal through studying the sensitivity of their main parameters, and comparing with regards to previous research.
The paper is structured as follows. Section 2 presents the necessary background for the current proposal presentation. Section 3 presents the proposal, which includes the formalization of rating regularities, regularities detection, regularities filtering, noise degree calculation, and noise detection and correction. Section 4 presents a case study for validating the proposal. Section 5 concludes the paper.
2. BACKGROUND
This section provides the necessary background for the proposal presentation, which includes basic notions about RSs, some related works on natural noise management and elementary concepts of fuzzy sets (FSs) theory.
2.1. Recommender Systems
RSs are considered as “any system that produces individualized recommendations as output or has the effect of guiding the user in a personalized way to interesting or useful objects in a large space of possible options” [19]. In a similar direction, Gunawardana and Shani [20] have pointed out that the two more common tasks related to RSs are the prediction task (i.e. the prediction of the user ratings about a group of items), and the recommendation task (i.e. the recommendation of a set of interesting and useful items to the user). Based on such goals, several recommendation approaches have been developed. One of the most popular classification of RSs has been provided by Bobadilla et al. [6], which groups them into a) demographic filtering, b) collaborative filtering, c) content-based filtering and d) hybrid filtering. Specifically, since 90s the collaborative and the content-based filtering have played a relevant role both at research-oriented and at application-oriented scenarios.
The most widely used paradigm for developing recommendation approaches has been the collaborative filtering, that is focused on performing the prediction and the recommendation tasks through only users' rating values [1]. This paradigm usually generates the recommendations for the current user, by exploring the preferences of other related users regarding their degree of similarity. Such an exploration is typically based on their rating patterns. This approach does not depend on items attributes; therefore it could be used in any recommendation scenario having enough preference values.
On the other hand, content-based RSs use the item's descriptions and a profile with the interests of the active user, for suggesting items similar to those the user already preferred in the past [3]. Content-based recommendation focuses on comparing the user profile and the candidate items, to find the items that should be suggested. Items profiles are usually represented through a set of attributes that can include weights to represent the importance of each one of them [1]. The user profiles are then represented by aggregating the profiles associated to their preferred items.
2.2. Related Works on Natural Noise Management in Recommender Systems
The majority of the recommendation approaches assume that the user ratings are free of inconsistencies, and then are focused on proposing new methods centerd on directly improving the recommendation accuracy. However, some recent research works reveal that such ratings can be either inconsistent or noisy [14,21]. Such noise has been grouped in two main categories according to the purpose of the user introducing erroneous information in the system [14]: (i) malicious noise, which is intentionally introduced by users to bias the recommendation and promote/demote certain products or diminish the system quality [21], or (ii) natural noise, which is introduced by users without malicious intentions when they provide their preferences [14]. Specifically, natural noise has attracted the attention of the researchers in the last few years, as inconsistencies that can be caused by users' personal conditions, social influences, emotional states, contexts, or certain rating scales [8].
On the other hand, recent researches have shown that there is a “magic barrier” in recommendation performance that algorithms were reaching, and it prevents them from improving their results [7]. In order to overcome such magic barrier it is necessary to check several elements in the input of the recommendation algorithm, such as the rating scale, or inconsistencies in preferences [9]. With this regard, natural noise management is focused on mitigating the negative influence of inconsistent preferences in the RSs performance [9,14,22].
Several research works have been focused on natural noise management in RSs. As it was pointed out in the Introduction section, these works can be divided in two groups: (i) those that depend on additional information for performing the natural noise management (e.g. item attributes, semantic information), and (ii) those that are able to perform the noise management using as input only the preferences values. Table 1 presents such two groups of recent related works, and introduces a new classification based on the use of crisp or fuzzy techniques for information modeling in each analyzed work.
| AdditionalInformation | Only Ratings | |
|---|---|---|
| Crisp | Amatriain et al. [9] | |
| Pham and Jung [11] | Li et al. [13] | |
| Saia et al. [12] | Yera et al. [14] | |
| Said and Bellogin [7] | Bag et al. [23] | |
| Dixit et al. [10] | ||
| Fuzzy | Yera et al. [15] | |
| Moses and Babu [24] |
Research works focused on natural noise management.
Regarding the research works that need additional information for performing its role, most of them depend on additional information that could be difficult to obtain in certain scenarios, and therefore lack of generalization capacity. Here, Amatriain et al. [9] proposed the mining and usage of a de-noised dataset with information provided by experts to reduce noise. Pham and Jung [11] used item attributes to create user models and correct the ratings that do not match such models, built by using information of other users identified as experts. In a different direction, Said and Bellogin [7] used item attributes for measuring user coherence in the rating patterns, showing that the recommendation accuracy is improved when the less coherent users are discarded from the dataset. Saia et al. [12] also presented an approach for removing incoherent items from a user profile, using semantic information. Finally, Dixit et al. [10] have brought the natural noise management into the context-aware recommendations, by proposing in this scenario a framework for noise detection and correction that depends on the contextual dimensions beyond the user-item matrix.
In a lesser extent, some authors have recently developed approaches focused on natural noise management using only the rating values. Li et al. [13] proposed the discovery of noisy but non-malicious users by detecting user's self-contradictions, regarding that highly-correlated items should receive similar rating value. Here the authors are centered on noise management at the user level by considering the removal of top-noisy rating for improving the recommendation accuracy. To manage noise at the rating level, Yera et al. [14] proposed a method for correcting noisy preferences following the principle that users and items have their own tendency giving or receiving ratings. Once the tendencies have been identified, the ratings that contradict them can be classified as possibly noisy and corrected by performing a new rating prediction for the same user and item. Recently, Bag et al. [23] followed a similar idea for natural noise management in highly sparse scenarios.
Furthermore, we have also detected a small group of works that consider the management of uncertainty associated to rating values through the use of fuzzy logic, and only rely on rating values for natural noise management. Here, Yera et al. [15] used fuzzy tools for composing user, item, and rating profiles; and identified as noisy to the ratings where the corresponding user and item profiles are close enough, but far from the rating profile. Noisy ratings are corrected through the prediction of a new rating value for the same user and item using a traditional collaborative filtering algorithm. Following this scheme, Moses and Babu [24] have also proposed a noise detection algorithm that formalizes the use of a fuzzy linguistic approach.
The analysis of the related literature concludes that there are few works focused on natural noise management using fuzzy techniques in spite of their potential to improve natural noise management. In addition, we have detected that the developed works suffer from some drawbacks such an important intrusiveness level and a high computational cost because they have embedded a collaborative filtering algorithm. The current research work aims at mitigating such drawbacks by proposing a new approach for natural noise management that uses the concept of rating regularity and also incorporates the uncertainty management through fuzzy techniques.
2.3. Fuzzy Sets Theory: Basic Concepts
This section reviews briefly different basic concepts of FSs theory such as, FS, fuzzy number (FN), linguistic variable, and so on that will be used in the main proposal of this research work.
Definition 1.
[25] FSs extend the notion of a set by introducing the degree of membership of elements. This establishes a correspondence between the elements of the universe of discourse
A FS
Definition 2.
[26] A FN is a FS
Normality: There exists at least one number
Convexity:
Definition 3.
[26] A triangular FN
A triangular FN is given by a tuple
Taking as basis these concepts, the use of linguistic descriptors based on the fuzzy linguistic approach [27], has been a straightforward and popular tool to model the uncertainty and vagueness inherent to the human reasoning and natural language. Using words or linguistic descriptors, humans are able to valuate some subjective aspects, rather than using numbers. The concept of linguistic variable arises to support this reasoning, where values are not numbers but words.
Definition 4.
[27] A linguistic variable
Typically, triangular FNs are used to provide the semantic rule in the context of RSs [28,29]. Figure 1 shows an example of a linguistic variable, using triangular FNs, being the terms set
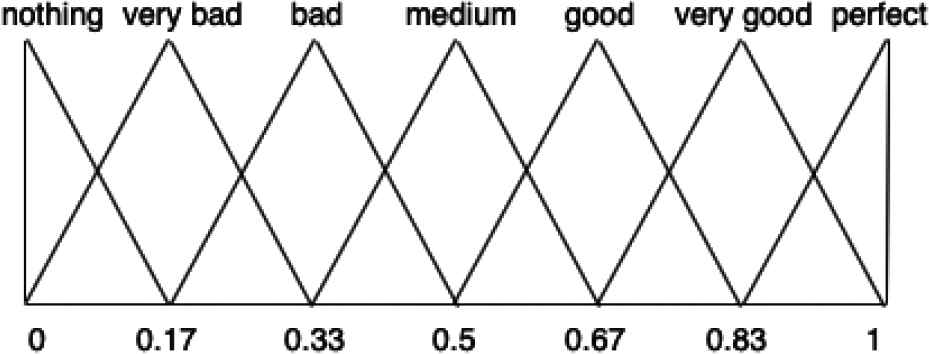
Semantic of a linguistic variable using triangular fuzzy numbers (FNs).
3. USING FUZZY RATING REGULARITIES FOR NATURAL NOISE MANAGEMENT
Here, it is presenting our new proposal that uses fuzzy rating regularities for natural noise management in RSs. Initially the concept of rating regularity is formalized (Section 3.1). Subsequently, the four stages of the proposal are presented (Figure 2): regularities detection (Section 3.2), regularities filtering (Section 3.3), noise degree calculation (Section 3.4), and noise detection and correction (Section 3.5).

Scheme of the proposed approach in a collaborative filtering scenario.
Furthermore, Figure 2 shows the role of this proposal in a collaborative filtering scenario, as an alternative to remove noise from the rating data before the application of the collaborative filtering recommendation approach.
To facilitate the proposal presentation, Table 2 contains the main notation used across the paper.
| Notation | Meaning |
|---|---|
| Rating of user |
|
| Value of the rating |
|
| Regularity term | |
| Rating regularity composed of a set of regularity terms | |
| Set of regularities |
|
| Set of regularities |
|
| Fuzzy transformation of |
|
| Fuzzy transformation of the regularity |
|
| Membership value of |
|
| Membership value of |
|
| Membership value of |
|
| Fuzzy transformation of the rating to get its noise degree | |
| Noise degree of |
Main notation used across the proposal.
3.1. Formalizing Rating Regularities
The definition of regularity takes as base the concept of frequent itemsets, widely used in association rule mining [30]. Consider
Based on the concept of frequent itemset, in this work we propose the concept of regularity as a frequent itemset but not composed by simple items. Instead, it is composed by a term (called regularity term), that represents a possible rating value of the current user over certain item. As far as we know, we only identified the use of the concept of regularity in RSs in the research work developed by Yera et al. [32], where the authors presented some evidences that regularities could be used for performing data preprocessing in RSs. However, such work only presents an initial analysis and does not consider any kind of uncertainty management.
To define the regularity concept, at first it is necessary to formally define the concept of regularity term.
Definition 5.
A regularity term is a term with the form
Example 1.
In order to show a demonstrative example across this proposal presentation, Table 3 shows a small dataset of a collaborative filtering RS with 4 users and 4 items. Here
| 5 | 4 | 3 | 1 | |
| 5 | 5 | 3 | 2 | |
| 5 | 4 | 3 | 2 | |
| 5 | 3 | 3 | 2 |
Working scenario for the proposal. Ratings in range [1; 5].
A regularity is then defined as follows:
Definition 6.
A regularity
Therefore, a user satisfies a regularity if he/she satisfies all the regularity terms associated to such regularity. This leads to the definition of support.
Definition 7.
The support of a regularity
Example 2.
Regarding the mentioned example in Table 3, the regularity
3.2. Regularities Detection
We then consider each user's set of ratings as an individual transaction composed by a set of regularity terms that represent the ratings of the current user (e.g. according to Table 3,
Here, we use an Apriori-like algorithm to find such regularities [30]. The Apriori algorithm comprises the detection of frequent itemsets in transactional data, and is composed by two stages. The first stage of the algorithm simply counts item occurrences to determine the large 1-itemsets. The second stage is composed by k passes, where in the pass k the large itemsets
Algorithm 1 presents an overview of this method, contextualized to the current scenario. At first, lines 01–03 initialize the three auxiliary sets
Algorithm 1: Algorithm for regularities detection
Input:
Output:
01: 1-sized-regularities=
02: large-regularities=
03: final-set=
04: For each item
05: Count = the amount of users satisfying
06: If Count
07:
08: 1-sized-regularities.Add(
09: large-regularities.Add(
10: While large-regularities !=
11: final-set.add(large-regularities)
12: New-regularity-set=
13: For each regularity
14: For each regularity
15: If
16:
17: Count = the amount of users satisfying
18: If (
19: New-regularity-set.Add(
20: large-regularities=New-regularity-set
21: End-While
22: Return final-set as
The second stage (lines 10–21), is composed of an iterative procedure where the iteration
Algorithm 1 uses as parameter the minimum support for considering a regularity as valid (i.e. a regularity which support is under such minimum value, is not discovered by the algorithm). Such parameter will be adjusted in the experimental section.
3.3. Regularities Filtering
It is expected that the set of the discovered regularities using the Apriori-like algorithm, has similar regularities and therefore contains redundancy. Considering Table 3 and a minimum support = 3, some valid regularities are:
However, both
To avoid such redundancy, we include a filtering stage that removes any regularity which is a subset of other regularity also included in the set. Algorithm 2 shows this procedure.
Algorithm 2: Regularity filtering algorithm
Input:
Output:
1: For each pair
2: If
3: Remove
4: Return
3.4. Noise Degree Calculation
Once the set of filtered regularities is obtained, such set is used as the key information source to calculate the noise degree of a given rating.
The idea of noise degree calculation consists of analyzing the ratings of those items that belong to a regularity in the filtered set and assign a greater noise degree when such rating values do not match with the values of the regularity. To manage the inherent uncertainty of this process, we use fuzzy modeling for our information representation.
We then consider the transformation of the rating values into a fuzzy representation according to their membership degree to three FSs that represent their tendency to be
Definition 8.
The fuzzy representation,
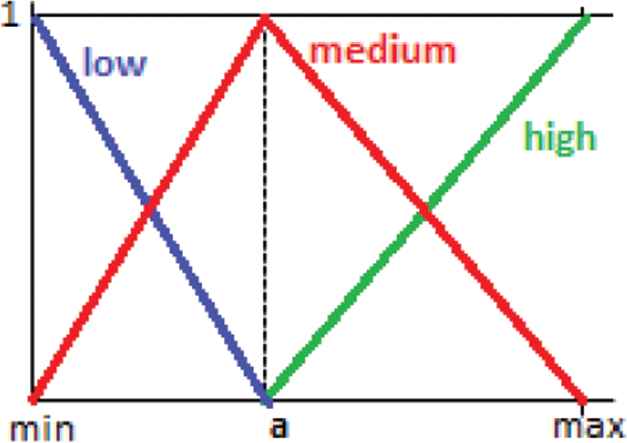
Membership function of the fuzzy sets low, medium, and high.
The fuzzy representation of the ratings leads to the definition of a fuzzy regularity.
Definition 9.
A fuzzy regularity,
Algorithm 3 presents the procedure to calculate the noise degree of a rating, based on these concepts. Once the fuzzy regularities and the fuzzy representation of the ratings have been obtained, the noise degree of a rating
Algorithm 3: Algorithm for noise degree calculation
Input:
Output:
1:
2: For each regularity
3: If
4:
5: Return
Initially the noise degree value is initialized as 0 (line 1). Afterward, line 2 at Algorithm 3 checks all the discovered regularities, considering their fuzzy transformation. For each one, line 3 checks whether the current fuzzy regularity has a term that makes reference to the same item associated to the rating received as input to calculate its noise; i.e. for the input rating
Figure 4 also shows a visual representation of this process, which is a key component of the whole approach for natural noise management.

Scheme of noise degree calculation process.
This algorithm required the use of a distance for calculating the dissimilarity between two fuzzy-transformed ratings. In this case it will be applied the Manhattan distance between such three dimensional vectors, regarding that its use in similar scenarios of fuzzy profiling in RSs has been previously discussed and justified [15]. Such distance reflects in a direct way the differences between the membership values, and considers the differences between the dimensions without giving importance to its distribution accross the dimensions.
The Manhattan distance between two n-dimensional vectors
Being
Previous works on a different scenario have shown that the value
Example 3 presents an example of a fuzzy regularity as well as its use in the whole noise degree calculation process that is currently being presented.
Example 3.
Assume Table 3 where the only one regularity, being the minimum support = 3, is
To obtain the noise degree of
The fuzzy transformation of
The fuzzy transformation of
Directly executing the Algorithm 3; in this case there is only one regularity.
Therefore, in such iteration, it is satisfied the condition at line 3, because such regularity contains a term (
Afterward, the noise degree is calculated as the distance between both fuzzy representations (see Eq. 10). This is:
3.5. Noise Detection and Correction
Once the noise degrees have been calculated, we process as noisy the top-n ratings with higher noise degree for each user. This research work will take into account several values for the parameter n, in order to consider a lower or higher intrusiveness degree.
Even though, previous works consider sophisticated rating replacement strategies that incorporate the use of collaborative filtering schemes to predict rating values [14,15], this work will consider simpler strategies with a lower computational cost. Specifically, it will consider two different strategies that can be applied indistinctly, depending on the desired goal of reaching a more or less accuracy improvement by removing or modifying ratings. The strategies are:
Remove the rating detected as noisy.
Replace the noisy ratings with the average rating associated to the current user.
Future works will consider regularities-driven strategies for noise correction in the framework associated to this research work (Figure 2).
Example 4.
Assume the working scenario presented in the Example 1, i.e. Table 3 where the only one regularity is
4. CASE STUDY
This section provides a case study to show how the application of the proposal as a preprocessing stage in the rating data, leads to an improvement in the recommendation accuracy. At first the experimental setup will be presented, including datasets and evaluation protocol. Furthermore, the experimental results are presented and discussed.
Datasets The proposal will be evaluated using three well-known datasets in RS research.
Movielens 100K, composed of 943 users and 1682 items, with a sparsity of 0.9369.
MovieTweeting, specifically it will be used a subset composed of 1692 users and 10123 items, with a sparsity of 0.995.
Netflix, specifically it will be used a subset composed of 1758 users and 1001 items, with a sparsity of 0.974.
Evaluation protocol The datasets are prepared through the approach presented by Gunawardana and Shani [20]. To build training and test sets, they choose a set of users from the dataset and randomly hide
To apply the current proposal over the training set, obtaining the modified training set.
To recommend with a given recommendation method using the modified training set, which is a de-noised version of the original training set. In this case we will use the item-based collaborative filtering approach, which is a well-recognized and widespread recommendation approach [36]. Here the number of neighbors in the prediction calculation are fixed to
To evaluate the recommendation results using an evaluation measure. In this case we use the Mean Absolute Error (MAE) [20], which focuses on how well the recommendation technique predicts the hidden ratings.
To compare the evaluation results against the recommendation results by using the original training set, instead of the modified one.
This proposal also depends on the parameter
Analysis of the results Tables 4–9 present the MAE results of the execution of the proposals for the three datasets. Specifically, the tables show the results associated to the two noise correction strategies (the average and the removal strategies), considering a minimum support value in the range [20; 70]. Furthermore, it was also considered the value n in the top-n ratings per user to process as noisy, in the range [1; 10], even though in some scenarios other values of n were considered.
| Support/n | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 20 | 0.7671 | 0.7668 | 0.7653 | 0.7659 | 0.7657 | 0.7679 | 0.7694 | 0.7716 | 0.7725 | 0.7741 |
| 30 | 0.7669 | 0.7663 | 0.7650 | 0.7655 | 0.7670 | 0.7677 | 0.7686 | 0.7707 | 0.7722 | 0.7729 |
| 40 | 0.7729 | 0.7667 | 0.7665 | 0.7666 | 0.7669 | 0.7679 | 0.7696 | 0.7707 | 0.7717 | 0.7725 |
| 50 | 0.7679 | 0.7667 | 0.7671 | 0.7669 | 0.7672 | 0.7669 | 0.7677 | 0.7685 | 0.7705 | 0.7717 |
| 60 | 0.7689 | 0.7681 | 0.7668 | 0.7668 | 0.7677 | 0.7696 | 0.7702 | 0.7711 | 0.7723 | 0.7733 |
| 70 | 0.7688 | 0.7692 | 0.7680 | 0.7686 | 0.7693 | 0.7707 | 0.7719 | 0.7733 | 0.7739 | 0.7749 |
Bold values indicate best results.
Results for the dataset Movielens. Average strategy. Baseline 0.7705.
| Support/n | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 20 | 0.7673 | 0.7683 | 0.7690 | 0.7713 | 0.7694 | 0.7727 | 0.7741 | 0.7761 | 0.7778 | 0.7814 |
| 30 | 0.7681 | 0.7693 | 0.7691 | 0.7701 | 0.7728 | 0.7734 | 0.7742 | 0.7782 | 0.7798 | 0.7795 |
| 40 | 0.7688 | 0.7696 | 0.7722 | 0.7724 | 0.7731 | 0.7765 | 0.7783 | 0.7824 | 0.7855 | 0.7869 |
| 50 | 0.7692 | 0.7707 | 0.7739 | 0.7748 | 0.7758 | 0.7759 | 0.7780 | 0.7790 | 0.7815 | 0.7828 |
| 60 | 0.7707 | 0.7707 | 0.7715 | 0.7730 | 0.7727 | 0.7757 | 0.7792 | 0.7800 | 0.7809 | 0.7826 |
| 70 | 0.7702 | 0.7730 | 0.7720 | 0.7721 | 0.7734 | 0.7770 | 0.7798 | 0.7815 | 0.7820 | 0.7851 |
Bold values indicate best results.
Results for the dataset Movielens. Removal strategy. Baseline 0.7705.
| Support/n | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 20 | 1.1844 | 1.1814 | 1.1815 | 1.1839 | 1.1870 | 1.1887 | 1.1912 | 1.1927 | 1.1971 | 1.1991 |
| 30 | 1.1886 | 1.1897 | 1.1892 | 1.1887 | 1.1899 | 1.1915 | 1.1926 | 1.1927 | 1.1953 | 1.1978 |
| 40 | 1.1962 | 1.1925 | 1.1927 | 1.1920 | 1.1902 | 1.1916 | 1.1919 | 1.1947 | 1.1962 | 1.1985 |
| 50 | 1.1934 | 1.1923 | 1.1932 | 1.1918 | 1.1917 | 1.1925 | 1.1915 | 1.1929 | 1.1949 | 1.1992 |
| 60 | 1.1967 | 1.1905 | 1.1905 | 1.1918 | 1.1937 | 1.1951 | 1.1944 | 1.1945 | 1.1970 | 1.1981 |
| 70 | 1.1937 | 1.1926 | 1.1917 | 1.1944 | 1.1974 | 1.1966 | 1.1967 | 1.1980 | 1.2025 | 1.2037 |
Bold values indicate best results.
Results for the dataset MovieTweeting. Average strategy. Baseline 1.2076.
| Support/n | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 20 | 1.1933 | 1.1945 | 1.1971 | 1.2029 | 1.2085 | 1.2137 | 1.2211 | 1.2218 | 1.2278 | 1.2290 |
| 30 | 1.1964 | 1.2029 | 1.2060 | 1.2099 | 1.2186 | 1.2236 | 1.2230 | 1.2340 | 1.2366 | 1.2419 |
| 40 | 1.2031 | 1.2080 | 1.2121 | 1.2191 | 1.2197 | 1.2245 | 1.2298 | 1.2345 | 1.2389 | 1.2426 |
| 50 | 1.2027 | 1.2092 | 1.2193 | 1.2212 | 1.2227 | 1.2238 | 1.2231 | 1.2247 | 1.2284 | 1.2342 |
| 60 | 1.2069 | 1.2121 | 1.2160 | 1.2183 | 1.2230 | 1.2263 | 1.2263 | 1.2267 | 1.2329 | 1.2351 |
| 70 | 1.2058 | 1.2128 | 1.2136 | 1.2217 | 1.2237 | 1.2277 | 1.2307 | 1.2335 | 1.2365 | 1.2370 |
Bold values indicate best results.
Results for the dataset MovieTweeting. Removal strategy. Baseline 1.2076.
| Support/n | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 20 | 0.7917 | 0.7887 | 0.7862 | 0.7864 | 0.7844 | 0.7846 | 0.7850 | 0.7845 | 0.7825 | 0.7830 | 0.7821 | 0.7831 |
| 30 | 0.7911 | 0.7891 | 0.7867 | 0.7862 | 0.7854 | 0.7861 | 0.7853 | 0.7843 | 0.7836 | 0.7827 | 0.7836 | 0.7841 |
| 40 | 0.7911 | 0.7902 | 0.7874 | 0.7852 | 0.7851 | 0.7837 | 0.7834 | 0.7833 | 0.7826 | 0.7821 | 0.7828 | 0.7831 |
| 50 | 0.7920 | 0.7897 | 0.7863 | 0.7849 | 0.7854 | 0.7854 | 0.7850 | 0.7850 | 0.7835 | 0.7838 | 0.7840 | 0.7835 |
| 60 | 0.7905 | 0.7884 | 0.7863 | 0.7871 | 0.7860 | 0.7858 | 0.7849 | 0.7846 | 0.7842 | 0.7852 | 0.7862 | 0.7857 |
| 70 | 0.7923 | 0.7884 | 0.7864 | 0.7863 | 0.7868 | 0.7865 | 0.7846 | 0.7839 | 0.7840 | 0.7846 | 0.7851 | 0.7846 |
Bold values indicate best results.
Results for the dataset Netflix. Average strategy. Baseline 0.8012.
| Support/n | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 20 | 0.8017 | 0.8041 | 0.8069 | 0.8067 | 0.8095 | 0.8100 | 0.8115 | 0.8140 | 0.8162 | 0.8142 |
| 30 | 0.8018 | 0.8042 | 0.8070 | 0.8048 | 0.8107 | 0.8133 | 0.8111 | 0.8117 | 0.8154 | 0.8164 |
| 40 | 0.8030 | 0.8055 | 0.8053 | 0.8035 | 0.8097 | 0.8084 | 0.8087 | 0.8102 | 0.8102 | 0.8105 |
| 50 | 0.8041 | 0.8044 | 0.8044 | 0.8031 | 0.8091 | 0.8116 | 0.8119 | 0.8157 | 0.8149 | 0.8175 |
| 60 | 0.8034 | 0.8041 | 0.8042 | 0.8067 | 0.8085 | 0.8095 | 0.8113 | 0.8133 | 0.8157 | 0.8189 |
| 70 | 0.8044 | 0.8016 | 0.8054 | 0.8060 | 0.8151 | 0.8127 | 0.8130 | 0.8160 | 0.8171 | 0.8227 |
| 80 | 0.8006 | 0.8011 | 0.8033 | 0.8079 | 0.8106 | 0.8094 | 0.8071 | 0.8100 | 0.8113 | 0.8160 |
| 90 | 0.8012 | 0.8034 | 0.8109 | 0.8155 | 0.8156 | 0.8128 | 0.8091 | 0.8154 | 0.8173 | 0.8185 |
Bold values indicate best results.
Results for the dataset Netflix. Removal strategy. Baseline 0.8012.
At first, it is significant that for the six experimental scenarios, the proposal leads to improvements in the recommendation performance in relation to the baseline values (specified in the caption of the corresponding tables). Here we recall that the baseline values are represented by the recommendation performance without considering the application of the proposal for natural noise management.
In the case of the natural noise management using the average user rating as correction strategy the proposal clearly outperforms such baseline reaching a MAE value of 0.7650 (baseline 0.7705) for Movielens; 1.1814 (baseline 1.2076) for MovieTweeting; and 0.7821 (baseline 0.8012) for Netflix.
It is also remarkable that for Movielens and MovieTweeting such results were obtained just for n = 3 and n = 2 respectively (i.e. modify 3 and 2 ratings per user), indicating that only the transformation of a small portion of the user profile, can lead to a relevant improvement in the recommendation performance.
In this way, for all the minimum support values, the tendency was to decrease the recommendation accuracy with the increment of n. This fact suggests that a higher intrusiveness degree in the user profile using the proposed correction strategies, seems to introduce noise, instead of removing it. In relation to the minimum support values, we also report a tendency to decrease the recommendation accuracy with the increasing of such support. Such fact suggests that a higher minimum support value gives the reaching of too general regularities that do not cover more specific knowledge that is useful for the noise correction. We also remark that we do not present results for a minimum support lower than 20 because the computational cost of the process disables its reaching in a rational time.
On the other hand, in the case of the removal strategy for noise correction, the results were most modest in relation to the average strategy. Here it was obtained a MAE value of 0.7673 (baseline 0.7705) for Movielens; 1.1933 (baseline 1.2076) for MovieTweeting; and 0.8006 (baseline 0.8012) for Netflix. For all cases, such results were obtained for n = 1 (i.e. modifying only 1 ratings per user). Furthermore, for higher values of n it was obtained a performance worse that the baseline. This behavior was expected, regarding that the information losing notably affects any recommendation scenario. However, it is notable that even a natural noise management approach that introduces information losing, can lead to recommendation improvements when such losing is slight and at very specific scenarios. In other direction, for the removal strategy the variation of the minimum support and the n values across their parameter scales, has a similar behavior in relation to the average strategy.
Comparison with previous works: In this subsection we compare our proposal against the most relevant previous work in natural noise management, according to our criteria in relation to this contribution. This is the proposal developed by Yera et al. [15], that is one of the few works on natural noise management that uses fuzzy tools for representing a user profile, an item profile, and a rating profile; and identifies as noisy to such ratings where the user and item profile are close enough, but far from the rating profile. Additionally, for noisy ratings it performs their correction by predicting a new rating value for the same user and item.
This last step adds an important computational complexity to the Yera et al. [15] proposal regarding it makes a new prediction for any detected noisy rating; in contrast to our current proposal which performs a very light prediction step that includes a simple average, and also identifies the required regularities in a very short time period regarding the nature of the RSs datasets.
Table 10 shows a comparison between our proposal and Yera et al. [15], in terms of recommendation accuracy (MAE) and also the amount of corrected ratings (it would be desirable a lower amount of corrected ratings to avoid intrusiveness). The table proves that even though our proposal has a lower computational cost in relation to Yera et al. [15], it is competitive with this research work and even outperforms it in some scenarios. In the case of Movielens, our proposal outperforms Yera et al. [15] by getting a lower MAE value and even reaching it by needing the modification of a lower amount of ratings. For MovieTweeting, our proposal obtains its best accuracy value by needing the modification of a lower amount of ratings, and even thought does not achieve the value at Yera et al., widely improves the original baseline and then could be used in several scenarios that require a low intrusiveness. Finally, for Netflix both methods obtain a similar recommendation accuracy, but our research work required the modification of a higher amount of ratings. This finding was obtained because the best result was at
| Method | MAE | Amount of Corrected Ratings |
|---|---|---|
| Movielens | ||
| Yera et al. [15] | 0.7655 | 8663 |
| Our proposal (Average strategy) | 0.7650 | 2652 |
| MovieTweeting | ||
| Yera et al. [15] | 1.1784 | 3932 |
| Our proposal (Average strategy) | 1.1814 | 3338 |
| Netflix | ||
| Yera et al. [15] | 0.7820 | 3647 |
| Our proposal (Average strategy) | 0.7821 | 13695 |
MAE, Mean Absolute Error. Bold values indicate best results.
Comparison of our proposal against a previous related research.
5. CONCLUSIONS
The current research work introduces the use of fuzzy rating regularities in the context of the natural noise management task. With this goal in mind, it proposes an approach composed of four stages which are regularities detection, regularities filtering, noise degree calculation, and noise detection and correction. The working principle of the proposal is that the regularities represent common rating behaviors that can be used to identify as noise to such ratings that contradict them.
The experimental results of the evaluation of the proposal conclude that it outperforms the baseline for all the considered datasets and experimental scenarios. Specifically, the best results tend to be obtained for lower values of the minimum support and lower values of the top-n noisy ratings corrected for each user. Furthermore, it was proven that the proposal is competitive with a recent related work in the state of art, outperforming it in several scenarios.
Future works will be focused on: 1) exploring the behavior of the proposal in the group recommendation scenario [37]; 2) incorporating the time dimension into the proposal, and 3) exploring its effect in the recommendation performance at more specific recommendation domains, such as an e-learning scenario [38].
CONFLICT OF INTEREST
The authors declare no conflict of interest.
AUTHORS' CONTRIBUTIONS
R. Yera, M. Barranco and A.A Alzahrani participate in the development of the proposal, its evaluation, discussion of results, and paper writing. L. Martínez participates in the development of the proposal, and guides the discussion of the results and paper writing.
ACKNOWLEDGMENTS
This work was supported by the Deanship of Scientific Research (DSR), King Abdulaziz University, Jeddah, under grant No. (DF-679-611-1441). The authors, therefore, gratefully acknowledge DSR technical and financial support.
REFERENCES
Cite this article
TY - JOUR AU - Raciel Yera AU - Manuel J. Barranco AU - Ahmad A. Alzahrani AU - Luis Martínez PY - 2019 DA - 2019/11/25 TI - Exploring Fuzzy Rating Regularities for Managing Natural Noise in Collaborative Recommendation JO - International Journal of Computational Intelligence Systems SP - 1382 EP - 1392 VL - 12 IS - 2 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.191115.001 DO - 10.2991/ijcis.d.191115.001 ID - Yera2019 ER -