
Predicting Cards Using a Fuzzy Multiset Clustering of Decks
 , Rudolf Kruse2,
, Rudolf Kruse2, - DOI
- 10.2991/ijcis.d.200805.001How to use a DOI?
- Keywords
- Fuzzy multisets; Clustering; Deck analysis; Hearthstone
- Abstract
Search-based agents have shown to perform well in many game-based applications. In the context of partially-observable scenarios agent's require the state to be fully determinized. Especially in case of collectible cards games, the sheer number of decks constructed by players hinder an agent to reliably estimate the game's current state, and therefore, renders the search ineffective. In this paper, we propose the use of a (fuzzy) multiset representation to describe frequently played decks. Extracted deck prototypes have shown to match human expert labels well and seem to serve as an efficient abstraction of the deck space. We further show that such deck prototypes allow the agent to predict upcoming cards with high accuracy, therefore, allowing more accurate sampling procedures for search-based agents.
- Copyright
- © 2020 The Authors. Published by Atlantis Press B.V.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
Automated game playing poses many interesting challenges to the development of artificial intelligence (AI) agents. While many studies presented good results on full information games, the agent's performance is often restricted by partial information on the current game state. The online game Hearthstone: Heroes of Warcraft (in short Hearthstone) [1] is such a partial information game, which is currently very popular among players [2]. Hearthstone is a deck-building card game in which players create their own decks to play against each other. At the time of writing this paper, Hearthstone includes roughly
During a game, players do not know their opponent's deck nor hand cards, but observe newly played cards every turn. Since the game state is partially unknown, missing information needs to be completed by the agent before it can apply any search-based algorithm to determine its actions. Similar to other games, expert players of Hearthstone are able to predict opponent moves to a certain degree. This ability can be attributed to their knowledge of the current meta-game, which can be understood as the likelihood of decks and strategies an opponent may play. When building a deck, users often combine cards and their effects with a certain strategy in mind. Players of the game often refer to the concept of deck archetypes, when they discuss decks with a common theme and similar card sets. Such a deck archetype may develop due to the popularity of a certain strategy and its accompanied deck. However, many players do not own all the necessary cards of a specific deck they are trying to build, therefore, variants of these deck archetypes can exist.
In the context of research, the annual Hearthstone AI competition compares agents based on their ability to play the game in various game modes [4]. It has motivated many interesting works, which often focus on the agent's ability to optimize its own turn. Nevertheless, winning approaches also attempt to model the opponent's general strategy [5,6].
In regard of the creation of an autonomous agent, estimating the opponent's upcoming actions is crucial in choosing their own actions. However, due to the opponent's cards being hidden, agents are limited in their capability of predicting these moves. Algorithms like Information Set Monte Carlo Tree Search (MCTS) [7,8] try to handle this problem by randomly sampling the opponent's hand cards to create a determinization of the game state. Based on the generated determinization the search process simulates its own and its opponent's actions and chooses the most promising action. Nevertheless, due to the large number of available cards, the accuracy of this sampling strategy is fairly low and can therefore limit the agent's success. To reduce the sampling size, it has been suggested to use a data base of frequently played decks. Agents using this sampling strategy have resulted in agents with very high performance [9,10] when being compared to other game-playing agents. Nevertheless, they require frequent updates of their deck data base in case the decks' popularity changes over time.
Sievers and Helmert [11] developed an extended version of Information Set MCTS, which does not sample a single determinization, but multiple determinizations of the game state. For each of these determinizations, the algorithm performs a separate run of MCTS. The results of each run are later aggregated to determine the agent's next action. Sievers and Helmert evaluated their approach on the game Doppelkopf, in which player's need to guess their teammates during the first turns of every game. This critical guess can have a high impact on the following actions. Their approach showed to be valuable in estimating the risk of the next action and improved the agent's overall performance. A study by Dockhorn et al. [12] further extended this approach by using neural networks for guiding the simulation, therefore, improving the quality of simulations during the search process and its result.
In a recent paper, we introduced an autonomous agent for Hearthstone [6], which implements a similar approach to the one presented in Reference [12]. We observed that the prediction accuracy and the agent's game-playing performance is still limited, which seems to be due to the enormous number of possible game state determinizations. We reduced the game state's sample space by using information of previously played cards to predict likely cards on the opponent's hand [13]. Using card co-occurrences of previously seen cards and the opponent's hand cards we were able to sample game state determinizations with a higher likelihood. We observed an improvement of the agent's game-playing performance in comparison to a uniform sampling. However, agents that were given complete information still outperformed the proposed agent. From this, we infer that further increasing the accuracy of the game state sampling may in turn further improve the agent's performance.
In the pursuit of creating a better agent for Hearthstone, we want to enhance the agent's prediction capabilities by modeling deck archetypes. In Section 2 we review restrictions of the deck-building process and provide a short overview of the theory of (fuzzy) multisets and various clustering approaches. In the subsequent Section 3, these methods will be used to develop a theoretical model of deck archetypes and how to mine them from a database of recent games. Especially the advantages of using fuzzy multisets instead of crisp multisets are highlighted based on some explanatory examples. We further present a case study, which is based on extracting deck archetypes and their centroid representation from actual playing data of the game Hearthstone (Section 4). We compare our result with a hand-labeled data set and show that the developed approach is able to identify deck archetypes of similar quality.
In this extended version of our conference paper [14] we added a method for predicting upcoming cards based on identified deck archetypes. The proposed sampling approach will be described in Section 5. Finally, we will evaluate the agent's ability to predict upcoming cards in the opponent's deck (Section 6). The paper concludes with a short analysis of the proposed approach and its possible application to the development of game-playing agents.
2. PRELIMINARIES
We begin this section with a short overview of deck archetypes and how they are defined in Hearthstone. A complete description of the game Hearthstone will be beyond the scope of this paper. For this reason, we would like to refer the interested reader to some excellent web sources maintained by developer [1] and the community [3]. We further provide detailed explanations on (fuzzy) multisets and selected clustering algorithms, which will be used to model and mine deck archetypes in Section 3.
2.1. Deck Building and Deck Archetypes
In Hearthstone a deck is a set of
players can only include cards they currently own (which are unlocked on their player's account)
a deck belongs to one out of 9 hero classes who are limited to a subset of about 400 cards each
a deck can only include cards that are either neutral or specific to the chosen hero class
depending on its rarity, a card can be included either once or twice
a deck can be made for a specific game mode that adds additional restrictions, e.g., standard or arena.
While players can create a large number of different decks not all of them are equally successful. The most successful decks define the meta and get known as meta-decks. Often these meta-decks will spawn multiple variants in which players replace just a few cards without changing the main theme of the deck.
A deck archetype describes the resulting cluster of decks with common card subsets. In this work, we will distinguish included cards into two groups, namely core and variant cards. While the core of a deck archetype contains cards that are included in all instances of this archetype, the inclusion of variant cards depends on the given instance. Core cards often define the main building blocks of the archetype and its accompanying strategy. In contrast, variant cards are often included to compensate for cards that the player does not own or to reflect the player's personal preferences. The following subsection will introduce (fuzzy) multisets, which will later be used to model deck archetypes.
2.2. (Fuzzy) Multisets/Bags
Multisets (also called bags) are collections of objects in which an object can be represented multiple times. In this paper, we will closely follow the notation introduced by Miyamoto [15] and Yager [16]. We denote a multiset by
The collection of all possible multisets of a universal set X is denoted by
For comparing two multisets
Union, intersection, and addition are defined pointwise for all
A fuzzy extension of multisets was first introduced by Yager (using the term fuzzy bags) [16]. Here, the sample fuzzy multiset
For simplicity we group objects of the same kind and their membership degrees, such as in
For each object
Let
Any operation between two multisets
For the sake of simplicity we assume a membership degree of
Similar to crisp multisets we can define inclusion, equality, union, and intersection based on the membership sequences of each element. Let
Similarly, union and intersection are defined pointwise for all
To clarify the notation we provide the following short example. Consider the two fuzzy multisets
The length per object is
For simplicity we extend the membership sequences for both multisets according to the maximal observed length:
Based on the extended membership sequences we can determine union and intersection of both multisets:
2.3. Clustering Algorithms
In this work, we are going to present the results of our deck archetype clustering process. The interested reader is referred to specialized literature on the topics of data mining and (fuzzy) cluster analysis, which provide a more comprehensive review of alternative approaches than this paper could offer [17–21].
2.3.1. Partitional clustering
The clustering algorithm k-means [22] is the most common representative of partitional clustering algorithms. During initialization,
2.3.2. Hierarchical agglomerative clustering
Hierarchical agglomerative clustering is a class of bottom-up clustering algorithms, in which each data point is assigned to a unique cluster during initialization. These clusters are iteratively merged according to a linkage criterion. The merge process is repeated until a minimum number of clusters is reached or all data points belong to a common cluster.
In this work we will make use of the following linkage criteria, which both determine the distance of two clusters based on the distances of points contained in differing clusters:
single linkage [23] reports the minimal distance between two points of different clusters
complete linkage [24] reports the maximal distance between two points of different clusters
Similar to k-means, the complete linkage favors compact and well-separated clusters. In contrast, the single linkage criterion may exhibit a phenomenoncalled chaining in which existing clusters are merged due to having two points, which are close to each other, even though other points are far apart.
2.3.3. Density-based clustering
The Density-Based Spatial Clustering of Applications with Noise (DBSCAN) algorithm proposed by Ester et al. [25], forms clusters by searching for dense regions of points. The
The region around a point is considered to be dense in case the number of points in its
3. (FUZZY) MULTISET ANALYSIS OF DECK ARCHETYPES
In the previous section, we discussed various building components for the deck archetype mining algorithm we are proposing in this section. We will first define how a deck archetype can be represented in terms of fuzzy multisets and further describe a mining routine based on the clustering algorithms presented above.
A natural representation of a deck is a multiset of cards.
3.1. Modelling Deck Archetypes
The Hearthstone community defines a deck archetype to be a collection of decks with a common set of cards. In the following, we are going to model a deck archetype to be the representative of a cluster of decks.
Let's consider two crisp decks
The intersection
While the resulting set describes the core of these two decks, the information of possible variants is lost during the generation of the common subset. A similar problem occurs if we generate the union
While the union operator preserves information on the inclusion of
For the crisp multiset we define the average multiset
Hence, the average of clusters
While the average operator already clearly distinguishes the inclusion patterns for
For this purpose, we transfer the average operator for crisp multisets to fuzzy multisets by calculating the average of every element of an object's grade sequence. Thus, the average operator for two fuzzy multisets
Representing both decks as fuzzy multisets results in the following centroid:
To ensure a stable clustering process we want to adjust the definition of the (fuzzy) multiset centroid to fulfill the associative property, since the result of merging multiple multisets should be independent of their merging order, specifically we want the following properties to be fulfilled:
Let a cluster
The same can be done for a cluster of fuzzy multisets
We will use the cluster centroid to represent the cluster and all its contained decks in a single (fuzzy) multiset.
3.2. Clustering of (Fuzzy) Multisets
For mining deck archetypes we are going to apply the clustering algorithms introduced in Section 2.3 to a data set of recently played decks. Since these clustering methods are distance-based we need a suitable distance measure to group data points into clusters of similar objects.
To measure the distance of two multisets
In our work, we will compare results based on the Euclidean distance with results obtained from applying the Jaccard distance measure. Here we use the general Jaccard distance [26]:
Similar to the Euclidean distance we transfer the equation to measure the distance of two fuzzy multisets
4. CLUSTERING EVALUATION
All project files for the following evaluation are available at Github (see Ref. [27]). We evaluated our clustering approach using deck data of the HSReplay website [28]. The website offers easy access to a large collection of recently played games. Players can choose to use the Hearthstone Deck Tracker plugin, which automatically records played games and uploads them to the HSReplay servers. In return, players can access information on the probability of their opponent's cards while playing the game.
We have extracted a deck data set that contains data from February 5th to 20th 2019. Each deck entry stores the deck's cards, the total amount of games recorded during the two weeks, its average win-rate, average game-length, and average turn count. Additionally, each deck entry provides information on the suggested deck archetype, which was labeled by expert players. The deck data set consists of a total of 956 distributed over 9 hero classes (cf. Table 1).
| Hero | nr Games in |
|
|---|---|---|
| Class | Deck Data Set | Replay Data Set |
| Druid | 70 | 191 |
| Hunter | 171 | 264 |
| Mage | 118 | 344 |
| Paladin | 120 | 187 |
| Priest | 183 | 542 |
| Rogue | 89 | 205 |
| Shaman | 18 | 287 |
| Warlock | 108 | 243 |
| Warrior | 79 | 799 |
| Total | 956 | 3062 |
Distribution of hero classes in used data sets.
We will compare the result of each clustering method with the labeling provided in the data set. For this purpose, we use the external validation measures homogeneity, completeness, and v-measure [29]. While homogeneity is satisfied in case the clusters contain only data points that are members of a single class (as labeled in the ground truth), completeness is satisfied if all the data points that are members of a given class are elements of the same cluster. The v-measure is the harmonic mean of homogeneity and completeness. All three measures provide values between
We first calculated the distance matrix of decks of the same hero class for each of the nine heroes. Figure 1 shows the heat map plot of the Jaccard distance of all Druid decks (70) contained in the data set encoded as fuzzy multisets. Clusters of similar groups are clearly distinguishable. Euclidean distance looks similar but is not limited to a range of
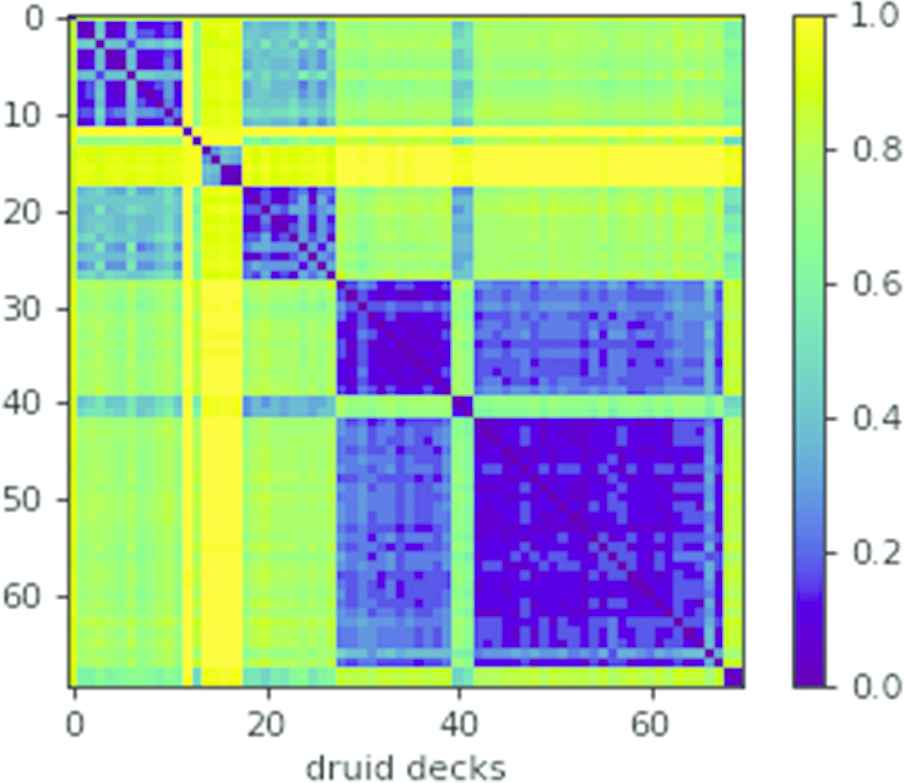
Jaccard distance matrix of Druid decks.
For each clustering algorithm we perform a parameter search. For k-means we varied the number of clusters
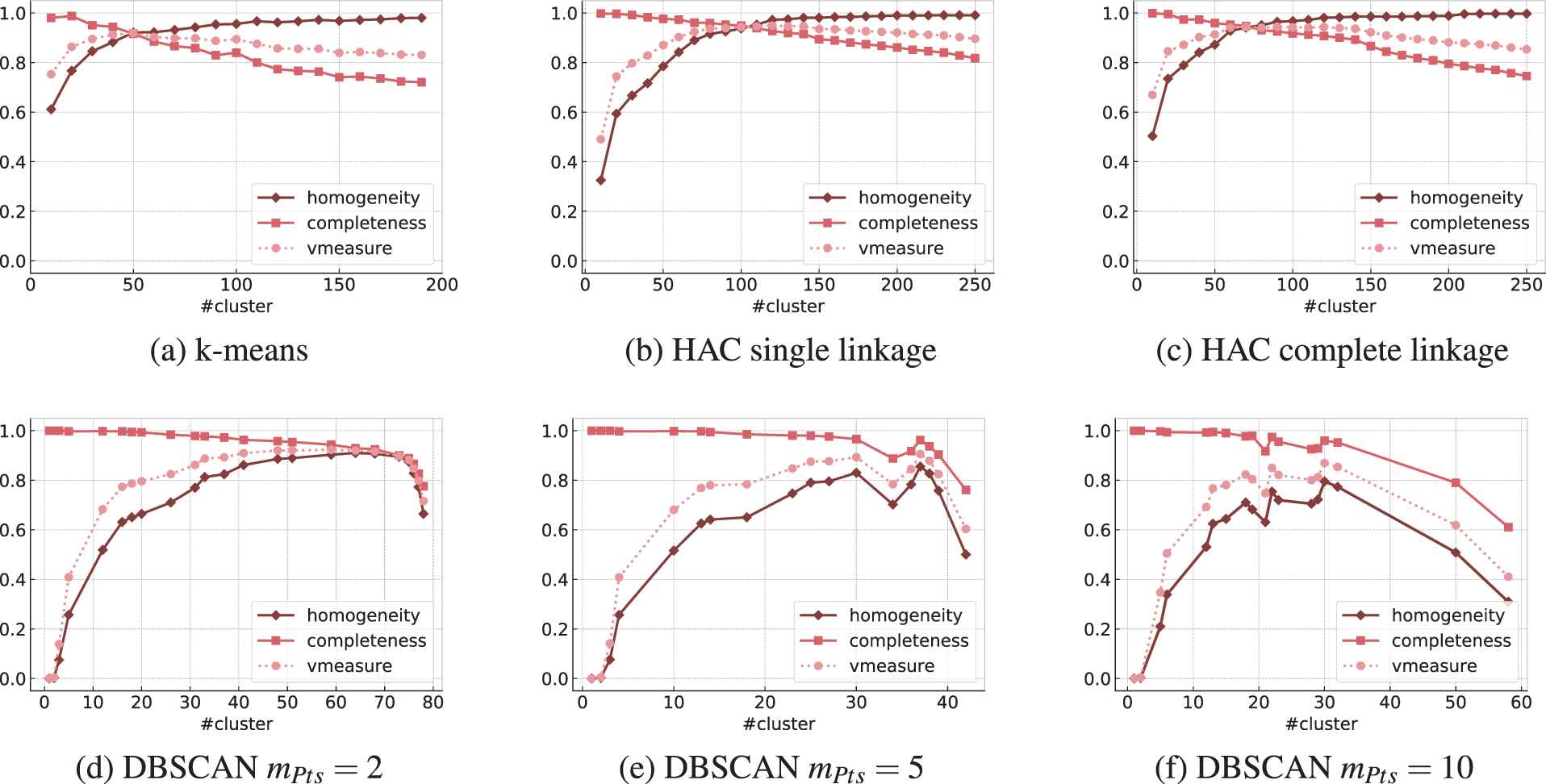
Comparison of clustering results based on external validation measures homogeneity, completeness, and the v-measure.
| Algorithm | Parameters |
Max V-Measure | |
|---|---|---|---|
| k-means | |||
| HAC single linkage | |||
| HAC complete linkage | |||
Best-performing parameter configuration per clustering algorithm.
The results show that the best clustering result in terms of the v-measure was achieved by single linkage (
5. PREDICTING UPCOMING CARDS
In the previous sections we have shown how a clustering of decks that resembles a human labeling can be extracted from a data set of played games. In the following, we will propose a method to predict upcoming cards based on a given clustering. Knowing the cluster centroids, a prediction of the opponent's cards can be made using the multi-process described in the following subsections.
5.1. Keeping Track of Observed Cards
At the beginning of the game the agent starts with an empty fuzzy multiset. During the opponent's turn, the agent keeps track of all the opponent's actions. Each card played is added to the agent's fuzzy multiset with a membership grade of
5.2. Determine the Most-Likely Deck Archetype
During the agent's turn, the agent first needs to determine the most-likely deck archetype. This can be done by calculating the pair-wise distance between the fuzzy multiset of observed cards and all the cluster centroids, which represent the deck archetypes of the current meta-game. The closest centroid is assumed to be the most-likely deck archetype and will be considered for the card prediction of upcoming cards. In case the agent can handle multiple state determinizations, a distance-weighted sampling can be applied to select one deck archetype per requested determinization. For this purpose, all distances
The resulting similarity values are further transformed into a probability distribution by
In the upcoming evaluation of the agent's prediction accuracy, we will only consider the most-likely deck archetype during the prediction process. However, in the context of a game-playing agent which uses a search process that can handle an ensemble of state determinizations [11] it may be advantageous to extract cards from a variety of possible archetypes to find a more robust sequence of actions.
5.3. Sample Cards
The final step of the prediction process is the sampling of cards. For this purpose, the agent first removes previously observed cards from the centroids membership sequence. For each observed card, the agent removes the highest value from the centroids membership sequence of this card. The remaining entries in the centroid are ranked according to the sum of their membership sequence. Similar to the bigram-based prediction each card receives a sampling probability based on the determined sum. The resulting probability distribution can be used to sample cards based on their likelihood to appear in the remaining cluster. Sampled cards are temporarily removed from the decks centroid before the next cards are sampled. This process will be repeated until a set of opponent cards has been determined to fully determinize the current game state.
6. EVALUATING THE PREDICTION ACCURACY
Given the prediction process proposed in the previous section, we evaluate the resulting prediction accuracy in two prediction tasks. First, we are testing the agent's ability to predict cards of the remaining game (Section 6.1), and second, we evaluate its accuracy to predict cards of the upcoming turn (Section 6.2). While the former gives us an understanding how well the considered deck archetype matches the opponent's deck, the second scenario is especially relevant when selecting the agent's next actions.
In this evaluation, we will be using a second data set that consists of human player replay data. Each record includes all observed cards that have been played per match but does not contain any information on the remaining cards of both players' decks. Only records that cover games of the standard game mode played during the same patch period (21 February 2019 to 3 April 2019) will be used for evaluating the proposed methods' prediction performance. Used data sets, the source code for the following evaluations, and the raw results can be found in the public git-repository [27].
6.1. Card Prediction for the Remaining Game
In this first evaluation, the accuracy of predicting upcoming cards of the remaining game will be measured. Since the number of observed cards and the complexity of turns changes over time, results will be reported bucketed by turn. Each algorithm is used to predict the 10 most-likely cards after each of the first 10 turns. To assure that the prediction of the last turns can be reasonably tested, only games that lasted at least 15 turns have been selected for this evaluation which resulted in a total of 3062 games. The hero class distribution is shown in (cf. Table 1).
Figure 3 shows the prediction accuracy for the best clustering per algorithm (see Table 2) bucketed by turn. Rank 1 represents the card that is believed to be the most-likely card to be played by the opponent during the remaining game. Vice versa rank 10 is believed to be the 10th most-likely card. Additionally, we report the average accuracy of the 10 cards to be believed the most likely to appear. Since the opponent is not able to play many cards per turn, we also report the aggregated prediction accuracy in Figure 4. This value represents the accuracy of any of the top
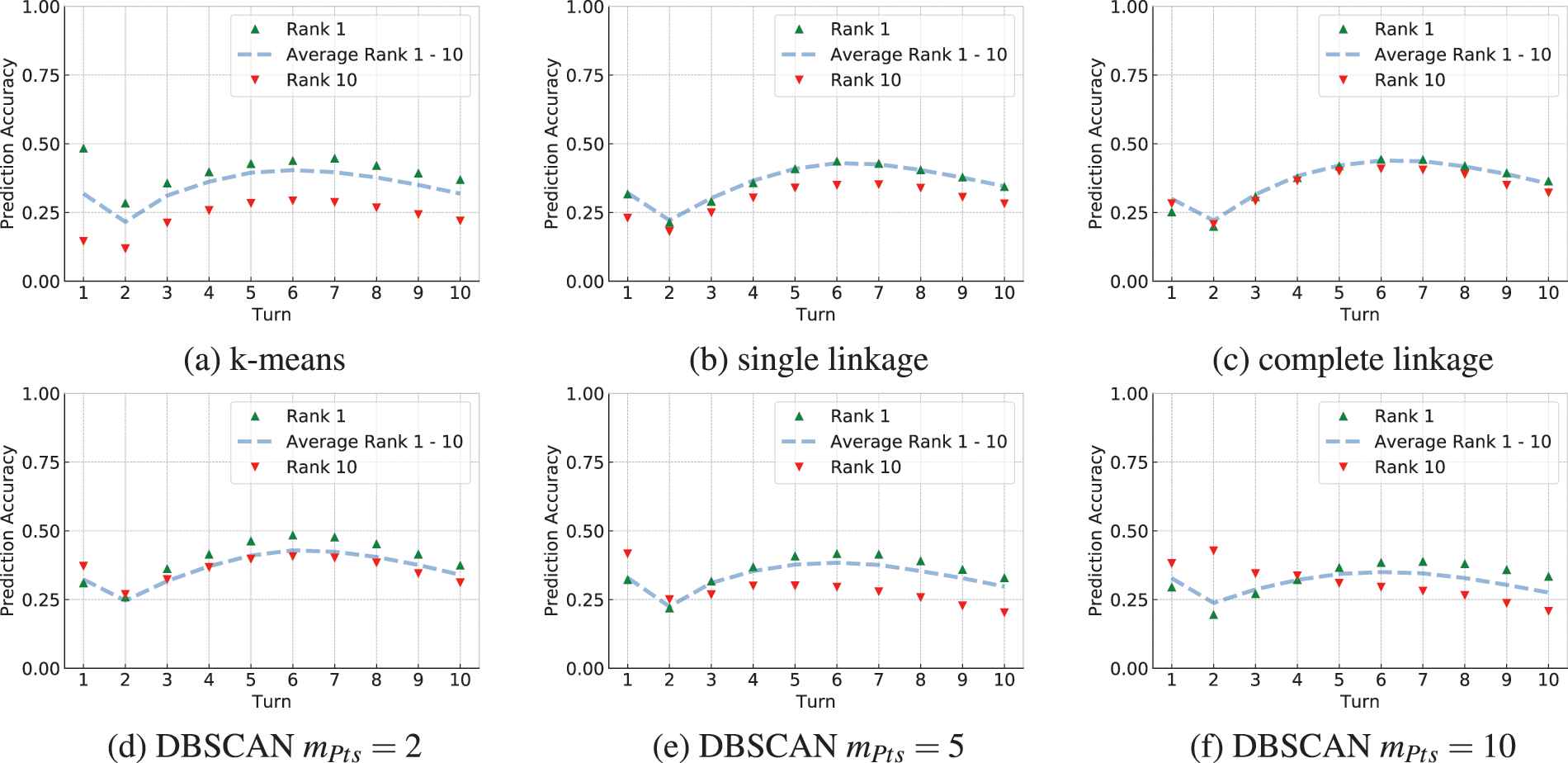
Accuracy for the prediction of cards that may appear in the remaining turns of the game bucketed by turn. Subfigures (a)-(f) show the prediction results based on the clustering result achieved using each algorithm's best-performing parameters. The highest-ranked card is marked in green while the prediction of the 10th ranked is shown in red. The average accuracy of all ten ranks is shown in blue.
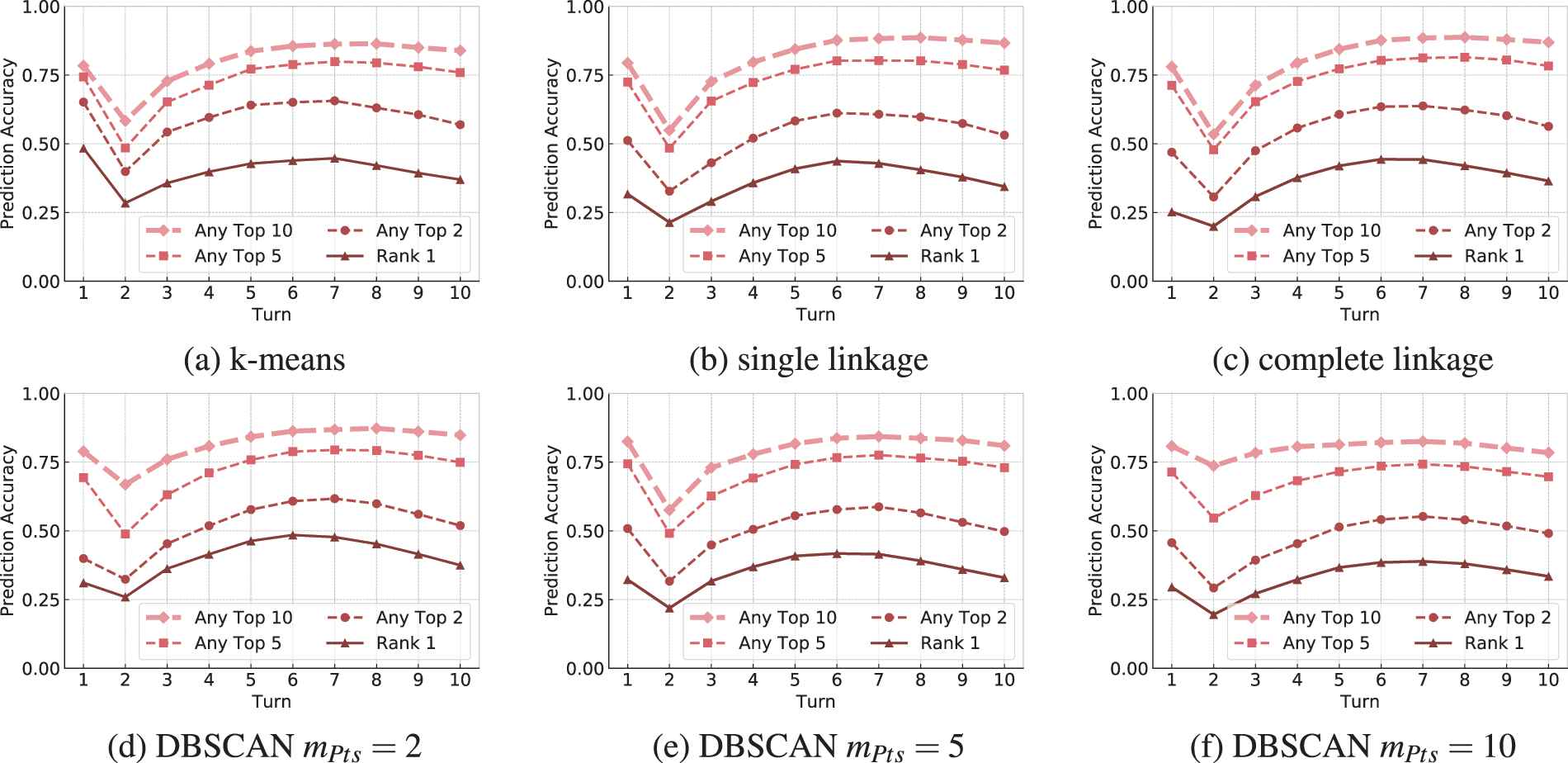
Accuracy for the aggregated prediction of cards that may appear in the remaining turns of the game bucketed by turn. Subfigures (a)-(f) show the prediction results based on the clustering result achieved using each algorithm's best-performing parameters. Reported values describe the accuracy of any of the top ranked cards being correct.
For all algorithms, the peak performance of predicting the highest-ranked card is achieved in turns 6 or 7. This is likely to be a result of the information gained until this turn, which helps the agent to identify the deck. Since the replay length is limited, we do not know all cards of the opponent's deck. Even in case cards are correctly predicted, chances are that the agent will not be able to observe them due to winning or losing the game before the card can be played. This is likely to be the cause of the steady decline of the prediction accuracy from turn 8 on.
Since multiple cards need to be sampled to create a state determinization of the opponent's hand cards, we also compared the aggregated prediction accuracy of the top
6.2. Card Prediction of the Next Turn
In a similar manner we evaluate the agent's accuracy in predicting cards of the next turn. Naturally, the accuracy will be much lower, since the number of cards that can be played during the next turn is limited.
Figure 5 reports the prediction accuracies of the highest-ranked card, the card with rank 10 and the average of the first 10 ranked cards. While the accuracy during all turns is very low, the aggregated values shown in Figure 6 look more promising. The prediction accuracy of upcoming cards steadily increases until the 9th turn at which it peaks at a value in between 40% and 50% depending on the clustering algorithm used. As a result the agent has a 40%–50% chance to correctly sample a card to be played during the next turn when only considering the most-likely deck.
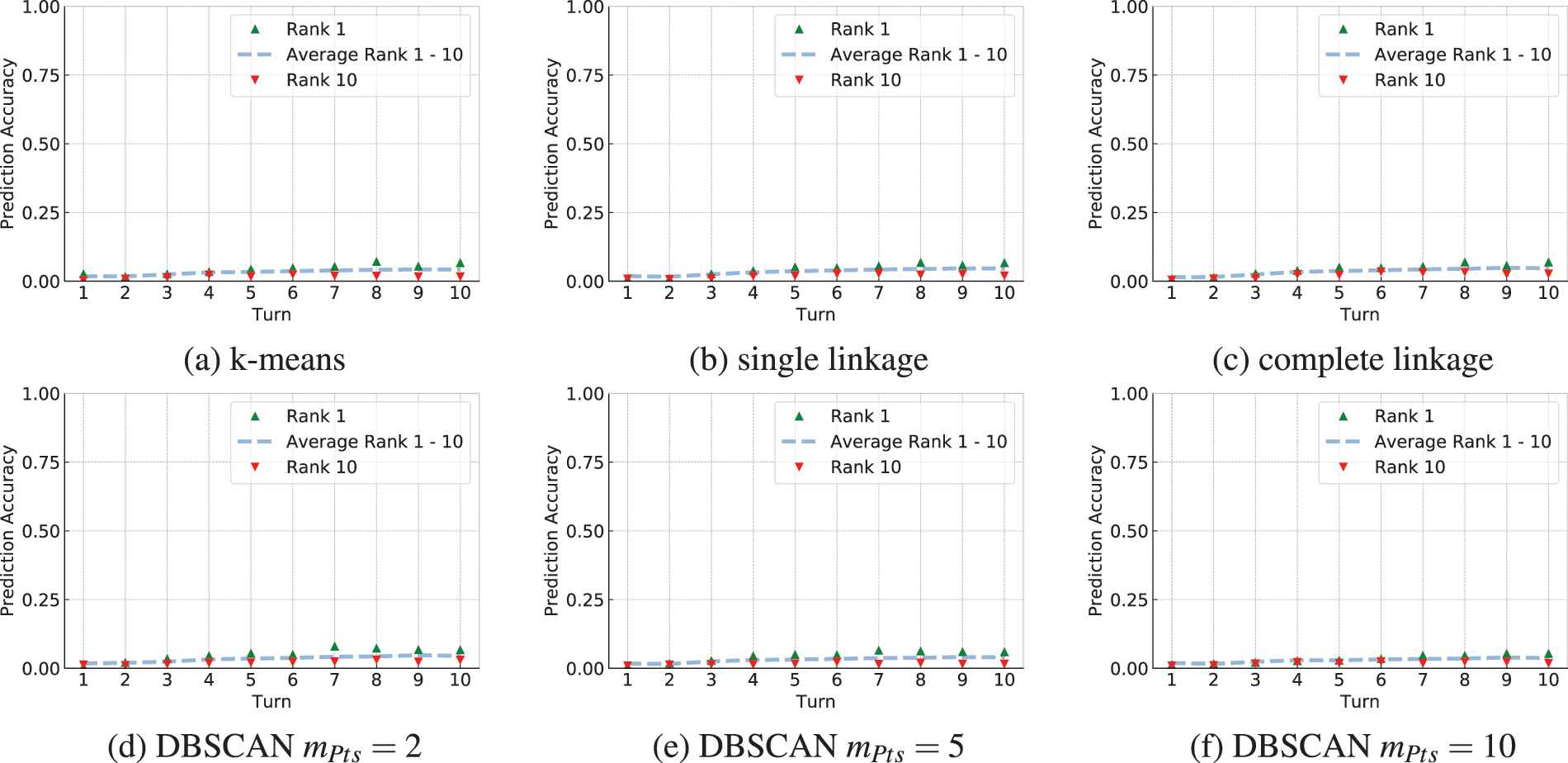
Accuracy for predicting cards that may appear in the remaining turns of the game bucketed by turn. Each model (a)-(f) ranks cards according to their estimated probability of appearance. The validation set is used to determine the accuracy of each prediction for every rank. The highest-ranked card is marked in green, while the prediction of the 10th ranked is shown in red. The average accuracy of all ten ranks is shown in blue.
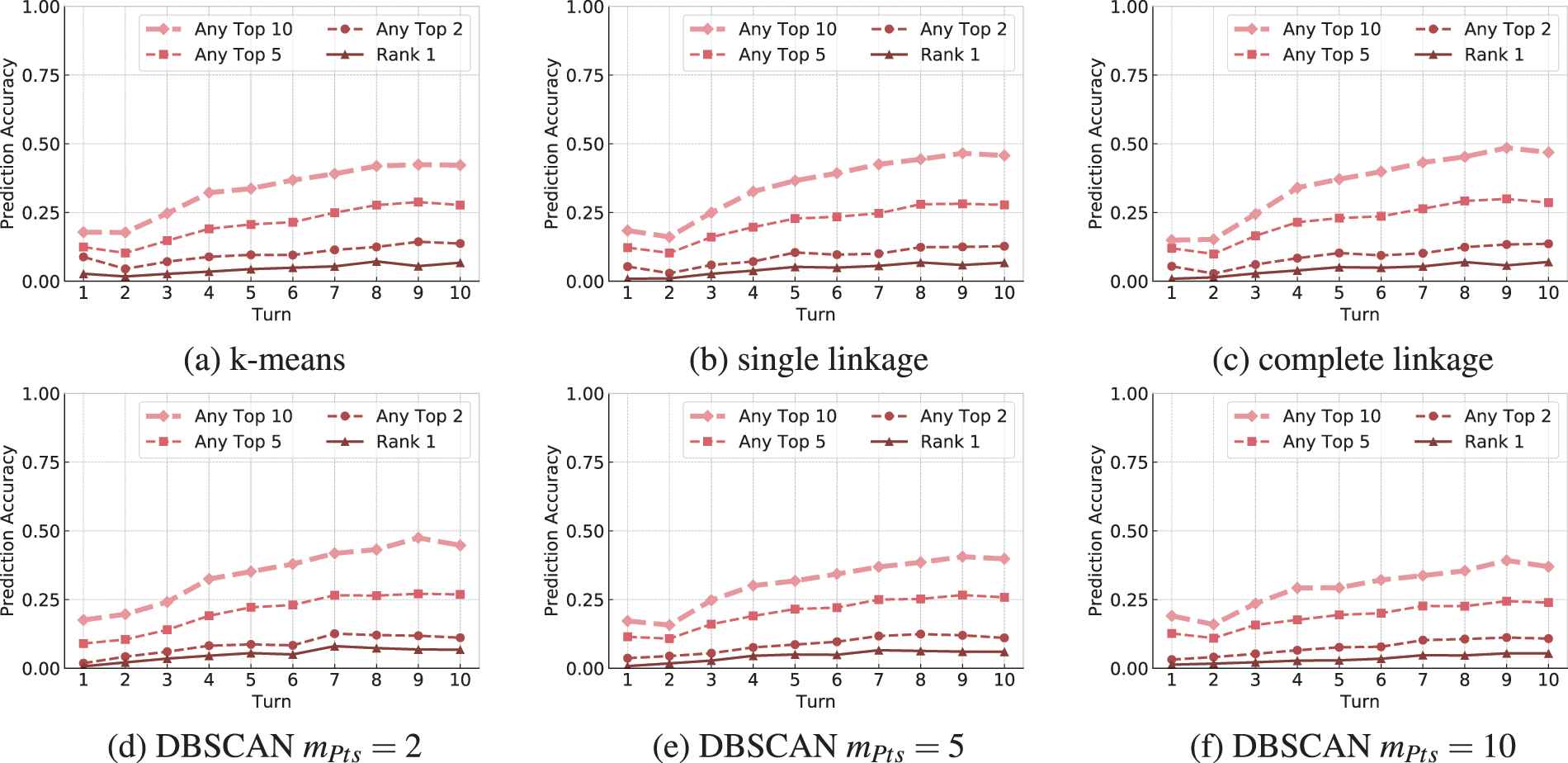
Accuracy for the aggregated prediction of cards that may be played by the opponent during its next turn bucketed by the turn the prediction has been made. Each model (a)-(f) ranks cards according to their estimated probability of appearance. The validation set is used to determine the accuracy in case the ranks 1-k are considered. Values describe the accuracy of the top ranked being correctly predicted.
It needs to be noted that the sampling approach does not consider if a card is playable during the next turn. Using an opponent model, the agent still needs to determine which of the sampled cards is likely to be played next.
7. CONCLUSION
In this paper we reviewed our automatic clustering process for deck archetypes and evaluated it in the context of the collectible card game Hearthstone. We chose to represent decks in the form of (fuzzy) multisets and define a centroid of clusters of such multisets. On the basis of fuzzy multisets, we clustered real player deck data using multiple clustering algorithms. The result of each algorithm was evaluated in context of real player data and has shown to match human expert player labels of deck archetypes reasonably well. Based on the extracted deck archetypes we proposed a sampling algorithm, which can be used to determinate a state. Predicted state determinizations have been evaluated regarding the prediction accuracy of upcoming cards of the whole game and the opponent's next turn. Results show that the process is able to identify upcoming cards with high accuracy. This forms an excellent basis for applying the proposed approach to state-determinizing search agents and may allow agents to play complex games such as Hearthstone on a higher level than they can currently achieve. Our next step will be to compare state-determinization methods and their effects on an agent's game-playing performance.
While our process currently assumes a static meta-game, we are eager to explore dynamic clustering and prediction schemes in the future. Since web sources frequently update their databases, it may be interesting to capture the dynamic evolvement of new strategies and decks among human players. At the same time, it would allow the agent to keep track of popular strategies to play accordingly. A better understanding of the process in which decks emerge may even help to construct new decks or to further balance the game. However, much work needs to be done until these challenges can be solved.
CONFLICT OF INTEREST
The authors declare they have no conflicts of interest.
AUTHORS' CONTRIBUTIONS
We would not like to explicitely state the authors contributions.
Funding Statement
No funding to be reported.
REFERENCES
Cite this article
TY - JOUR AU - Alexander Dockhorn AU - Rudolf Kruse PY - 2020 DA - 2020/08/18 TI - Predicting Cards Using a Fuzzy Multiset Clustering of Decks JO - International Journal of Computational Intelligence Systems SP - 1207 EP - 1217 VL - 13 IS - 1 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.200805.001 DO - 10.2991/ijcis.d.200805.001 ID - Dockhorn2020 ER -