
MADL: A Multilevel Architecture of Deep Learning
 , Hafsa Raissouli2
, Hafsa Raissouli2- DOI
- 10.2991/ijcis.d.201216.003How to use a DOI?
- Keywords
- Convolutional neural network; Multilevel architecture of deep learning; Advanced activation function; CIFAR-10; MADL
- Abstract
Deep neural networks (DNN) are a powerful tool that is used in many real-life applications. Solving complicated real-life problems requires deeper and larger networks, and hence, a larger number of parameters to optimize. This paper proposes a multilevel architecture of deep learning (MADL) that breaks down the optimization to different levels and steps where networks are trained and optimized separately. Two approaches of passing the features from level
- Copyright
- © 2021 The Authors. Published by Atlantis Press B.V.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
The use of deep neural network (DNN) has been a growing trend over the years in solving many real-life problems [1]. DNN consists of several layers of neurons that are fully connected to each other. The layers that are located between the input layer and the output layer are called hidden layers. The value of each neuron in the hidden layers is computed as the weighted sum of the previous layers' neurons added to a bias factor and activated using an activation function. The fact that DNN are fully connected makes them heavy and computationally expensive. As stated in Ref. [2], this full connectivity can be wasteful. Convolutional neural networks (CNNs) on the other hand, are not fully connected. CNN uses convolutional layers to pass a filter of size
CNN has witnessed a tremendous popularity in the last decade making machines and humans rivals [4]. CNN has contributed in many domains and helped solving real-life problems such as object detection [5,6], image classification [7,8] face recognition [9], image denoising [10], and pose estimation [11]. A lot of interest was given to ways to improve the prediction accuracy of the CNN model and the rummage for simple and efficient techniques is still persistent [12–14]. CNN is powerful in extracting high-level features from images [15]. Traditional feature extraction techniques generally consider limited types of features [16,17]. CNN on the other hand, has the ability to learn invariant features [18]. To make use of the feature extraction ability of CNN, many studies have used CNN as a feature extractor [15]. Ensembling methods are also popular techniques where one or several CNNs are used to extract features from the image and then perform class decision using another classifier such as support vector machine (SVM) [19,20]. Some studies have used several CNNs to classify a set of given images and have performed voting to assign the final decision class [21]. Other studies have combined different CNN architectures (e.g. AlexNet and LeNet) in one architecture for richer domain specific feature learning [22].
This paper proposes an ensembling approach of CNN architectures. The approach of this model is to break down the optimization of deeper networks to levels where each network in a given level is trained and optimized separately leading to a better performance. Advanced customizable activation function that is comparable in its performance to ReLU is also proposed. The rest of the paper is organized as follows: Section 2 presents a literature review, the proposed approach is in Section 3, Section 4 discussed the experiments and results, and the conclusion is in Section 5.
2. LITERATURE REVIEW
2.1. Ensembling Techniques
The use of CNN for feature extraction and ensembling techniques have been explored in many studies [19–21]. The motivations to seek techniques to assemble different models have been discussed amply [19,23]. The main reasons manifest in the limitations of building one perfect model due to the possibilities for the training phase to land on a local instead of a global minimum [23,24]. In addition, the fact that CNN performs well as a feature extractor supports the concept of assembling several CNNs for more various features [2,21]. In Ref. [19], the authors investigated the use of CNN for feature extraction for face recognition. The method used suggests extracting the features using a CNN of three convolutional layers. Feature selection on the extracted features is then performed using PCA. For the final classification, SVM is employed. The experiments showed that SVM performs better with the reduced features. The authors suggest that the PCA helps describing the data vectors in a better way. Similar to the latter study, in Ref. [20], the authors tackled face detection using two different CNNs for feature extraction (Clarifai and VGG), PCA for feature selection, and SVM for classification. In Ref. [25], the proposed method is a fusion of multiple models that are trained with different feature sets that are extracted using different machine learning algorithms. Then as in Refs. [19,20] feature selection is done using PCA. Other studies have combined popular architectures such as AlexNet and LeNet in one architecture for better feature extraction [22]. A study in Ref. [2] combined AlexNet and LeNet to form three different architectures namely, RFTPM, FTPM, and HTPM. The three proposed architectures are shown to be effective in unconventional image filtering. Out of the three, the HTPM, that is a half trainable model where the first four convolutional layers are initialized by AlexNet, is shown to be the superior and the most scalable compared to the baseline models. Another study in Ref. [26] uses five convolutional layers to extract obstacle features. The features are passed to a network that detects the obstacle area. This developed architecture shows promising results in intricate driving environments. An other study in Ref. [21] introduced an ensembling technique of several CNNs that are optimized and fine-tuned multiple times to form twelve separate models. Two architectures were used in the generation of the models, namely, Resnet and Densenet. The fusion of the models is done by taking the output of the CNNs, that is a probability value, and voting for the correct label.
From the literature, the ensembling techniques use roughly one of the following approaches:
Using convolutional layers for feature extraction which leads to a large number of features impelling to perform feature selection before passing the features to another classifier.
Combining different architectures into one architecture forming a single network with a set of convolutional and pooling layers for feature extraction followed by fully connected layers for decision-making.
Taking the output of
This paper addresses a generalized ensembling model, namely, multilevel architecture of deep learning (MADL). MADL performs the feature extraction using
2.2. State-of-the-Art on CIFAR-10
Many studies aimed to improve the performance of CNN through various techniques especially for image classification on the benchmark datasets such as CIFAR-10. Ref. [27] presented Mixup distribution that makes the model act linearly between training examples in order to reduce the oscillations that occur when predicting the labels of the test examples. CIFAR-10 was trained using Mixup and resulted in an accuracy of 97.3%. Ref. [28] proposed the Manifold Mixup regularizer that improves the model generalization. The conducted experiments on CIFAR-10 achieved an accuracy of 97.46%. Ref. [29] argued that standard CNNs are overparameterized and presented a scheme for parameter sharing that results in a hybrid network between CNN and RNN. The experimentations on CIFAR-10 recorded an accuracy of 97.47%. In Ref. [30], the authors proposed Fixup initialization technique that promotes a network training without batch normalization. Fixup initialization was used with mixup and cutout on CIFAR-10 to achieve an accuracy of 97.7%. Ref. [31] proposed the squeeze and excitation (SE) blocks that improve the modeling of the channel-wise features. CIFAR-10 was trained using SE blocks on shake-shake network with cutout to achieve an accuracy of 97.88%. In Ref. [32] the study performed a reduction of the search cost of NAS and employed it using a proxyless strategy, namely, ProxylessNAS. CIFAR-10 was trained with ProxylessNAS gradient using PyramidNet backbone and cutout and resulted in an accuracy of 97.92%. Ref. [33] proposed a semi-supervised learning auto encoding approach the experiments were conducted on 250 labels of CIFAR-10 and resulted in an accuracy of 98.01%. Ref. [34] got an accuracy of 98.3% with 4000 labels of CIFAR-10 that was used to experiment the proposed auto-augment technique that searches for effective augmentation policies. Table 1 describes briefly the state-of-the-art on CIFAR-10.
| Ref. No. | Network Type | Improvement Technique | Epochs | Augmen-tation | Trans-fer Learning | Acc (%) |
|---|---|---|---|---|---|---|
| [27] | WideResNet and DenseNet-190 | Mixup | 200 | 97.3 | ||
| [28] | PreAct ResNet34 | Manifold Mixup | 1200 | 97.46 | ||
| [29] | SWRN 28-14-2 | parameter sharing | 200 | 97.47 | ||
| [30] | WideResNet40-10 | Fixup | Not stated | 97.7 | ||
| [31] | Shake-Shake 26 2x96d | Squeeze and excitation | Not stated | 97.88 | ||
| [32] | Proxyless-G | ProxylessNAS | 600 | 97.92 | ||
| [34] | BiT-M (4000 labels of CIFAR-10) | Auto-augment | 90 | 98.4 |
Summary of the state-of-the art on CIFAR-10.
3. THE PROPOSED APPROACH
3.1. Multilevel architecture of deep learning
Improving the accuracy of deep networks has been a heed to researchers [35–38]. According to the previous work, the concept of grouping several CNNs appeared in many studies [20,21]. In this paper, MADL is proposed as an accuracy improvement technique that makes use of the features extracted by several networks. This architecture builds several networks in levels as illustrated in Figure 1. As Figure 1 shows, there is
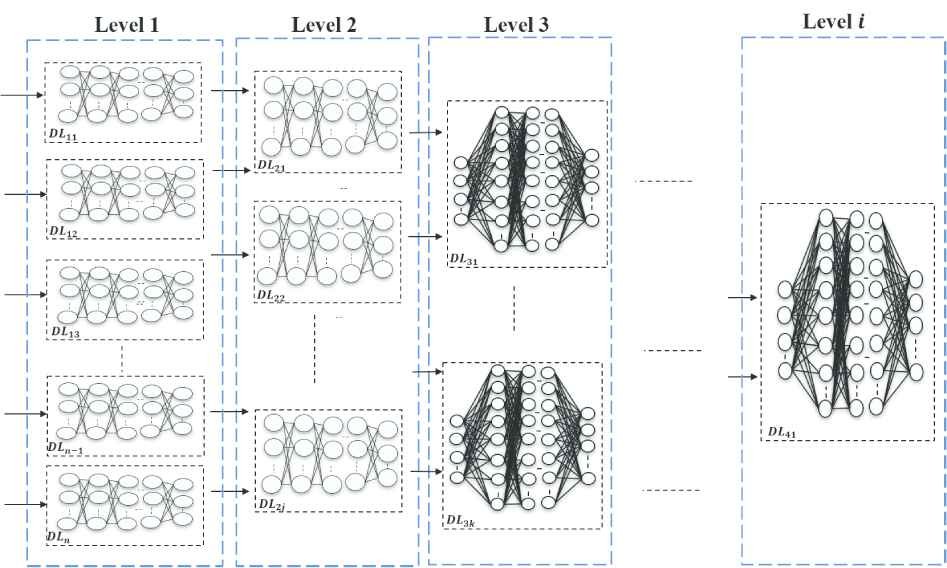
Multilevel architechture of deep learning (MADL) concept.
The goal of this concept is to break down the parameter optimization of the networks to multi levels and steps,
MADL Approach one: taking the values of the output layer in level
MADL Approach two: Introducing an additional fully connected layer with
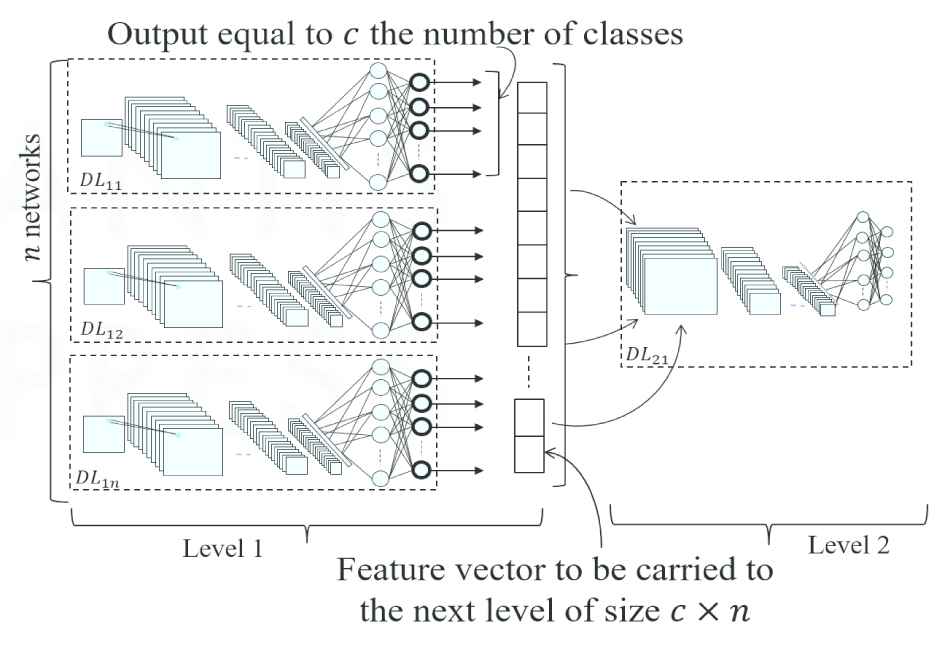
Multilevel architecture of deep learning (MADL) Approach one: A two-level architecture where the input of the second level is taken from the output layer.
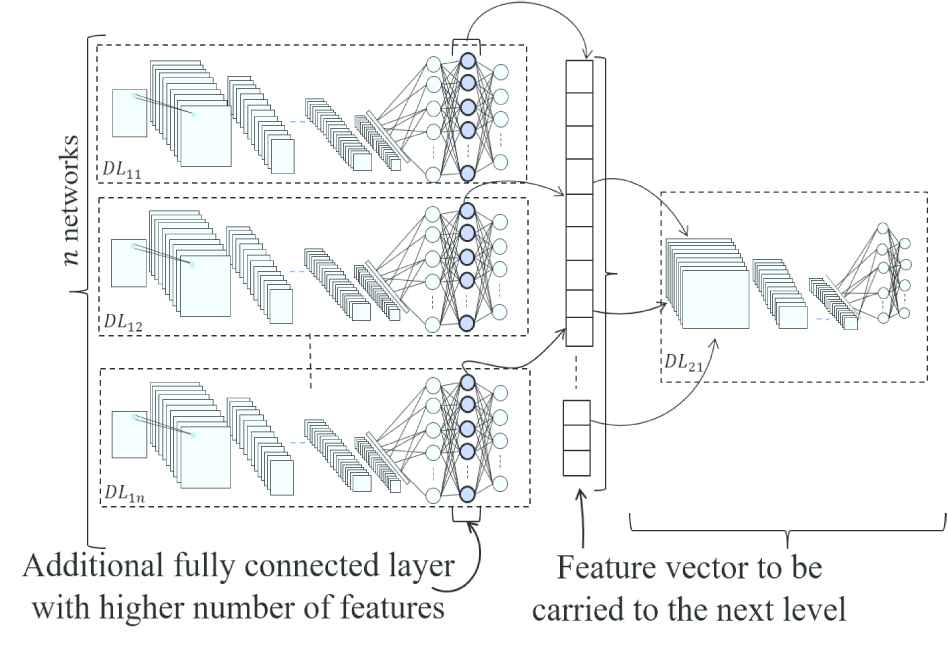
Multilevel architecture of deep learning (MADL) Approach two: A two-level architecture where the input of the second level is taken from the additional fully connected layer.
3.2. An Advanced Activation Function
The networks across the levels can differ in their architecture and can use different activation functions to help extracting different features. This raises the inducement of finding additional effective activation functions other than ReLU. We propose here a customizable new activation function. Viewing neural networks as a structure that is inspired from the human nervous system, the signal that stimulates the neurons coming from neighboring neurons is an electrochemical stimulus that can be measured, and its strength defines if a neurons will be activated or inhibited [39]. The strength of this signal is usually small [40]. This fact is a motivation to find an activation function that has a small range, yet, overcomes the problem of vanishing gradient that other functions suffered from [3]. Thus, the function in Equation (1) evolved.
When using CNN for feature extraction, the proposed activation function, when set to different parameters, can serve in extracting a variety of features. So as to put this function under experiment, known architectures like Googlenet, Resnet, and Densenet were used after modifying the ReLU activation layer to the proposed function. The obtained results led to some modifications in the proposed function, conducting to the function in Equation (3)
The function in Equation (3) still could not attain the starting goal of smaller activation values similar to the human nervous system, and hence, further research can be conducted in this point.
4. RESULTS AND DISCUSSION
4.1. Results of the Advanced Activation Function
So as to scrutinize the use of the proposed activation function and its impact on the performance, the function in Equation (3) was set to different parameters (see Table 2). Note that the proposed function can be viewed as a generalized ReLU as setting
| Parameters |
||||||
|---|---|---|---|---|---|---|
| Function | a | b | c | n | Avg. Acc. (%) | Variance |
| ReLU | – | – | – | – | 95.34 | 1.45 |
| F1 | −10 | 0.01 | 1 | 3 | 95.25 | 1.68 |
| F2 | −10 | 0.1 | 1 | 3 | 94.15 | 1.88 |
| F3 | −3 | 0.1 | 1 | 2 | 93.98 | 2.16 |
| F4 | −2 | 0.1 | 1 | 2 | 93.93 | 2.64 |
| F5 | −2 | 0.1 | 1 | 93.08 | 3.11 | |
| F6 | −10 | 0.1 | 1 | 93.16 | 4.16 | |
Results of rectified linear unit (ReLU) and the proposed activation function using different parameters.
From Table 2, ReLU and F1 show the highest performance with an accuracy of 95.34% and 95.25% respectively. These two functions also have the lowest variance across the ten-fold cross validations' accuracies. F5 and F6, that have
4.2. Results of MADL
The experiments of MADL are carried out on CIFAR-10 dataset [44,45]. This dataset consists of 60,000 colored 32x32 pixel images. The training set is 50,000 images and the test set is 10,000 images. The baseline model comprises an Inception-v3 and a Resnet-50 trained on CIFAR-10. MADL is then built using these two networks. MADL was experimented using approach 1 illustrated in Figure 2 and approach 2 illustrated in Figure 3.
4.2.1. Baseline model results
As a baseline model, Inception-v3 [46], that has a depth of 48 layers and a width of three, and Resnet50 that is 50 layers deep were used. Note that these two architectures (Inception-v3 and Resnet50) have nearly 3 times fewer parameters than Alexnet that is only 8 layers deep. For the training details, Inception-v3 and Resnet-50 were trained with ReLU as an activation function and using SGD for 25 epochs. Transfer learning from pretrained network on ImageNet dataset is performed by conserving the weights of the three first layers to speed up the convergence of the model. The batch size is limited to 10 and the initial learning rate is set to
| Network | Level 1 | Level 2 | Accuracy (%) |
|---|---|---|---|
| Inception-v3 | – | – | 97.2 |
| Resnet-50 | – | – | 96.8 |
| MADL approach 1 | Inception-v3 + Resnet-50 | 5layers CNN | 97.3 |
| MADL approach 2 | Inception-v3 + Resnet-50 | 5layers CNN | 98.04 |
Summary of results of Inception-v3, Resnet-50, MADL approach 1, and MADL approach 2.
4.2.2. Proposed model results
The inception-v3 and Resnet-50 in the baseline model are used to build MADL approach 1 by taking the 10 features of the output layer without Softmax. The 10 features from each network are combined to a 20 features vector for each input image that is fed as input to a simple network that contains 5 convolutional layers and one fully connected layer that is trained for 1 epoch. Combining these two networks with 97.2% and 96.8% accuracies resulted in 97.3% that is an improvement of 0.1% over the highest accuracy in the first level. Figure 7 shows the confusion matrix of MADL. With a horizontal read, comparing the MADL results with Inception-v3 and Resnet-50, we notice that only one class (truck class) has improved over the two previous networks.
For MADL approach 2, the first level consists of the inception-v3 and the Resnet-50 with an additional fully connected layer. The same training details of the baseline model are conserved. The second level is a simple CNN with 5 convolutional layers and one fully connected layer that is trained using SGD for 1 epoch and an initial learning rate of 0.01. Figure 4 illustrates the used architecture.
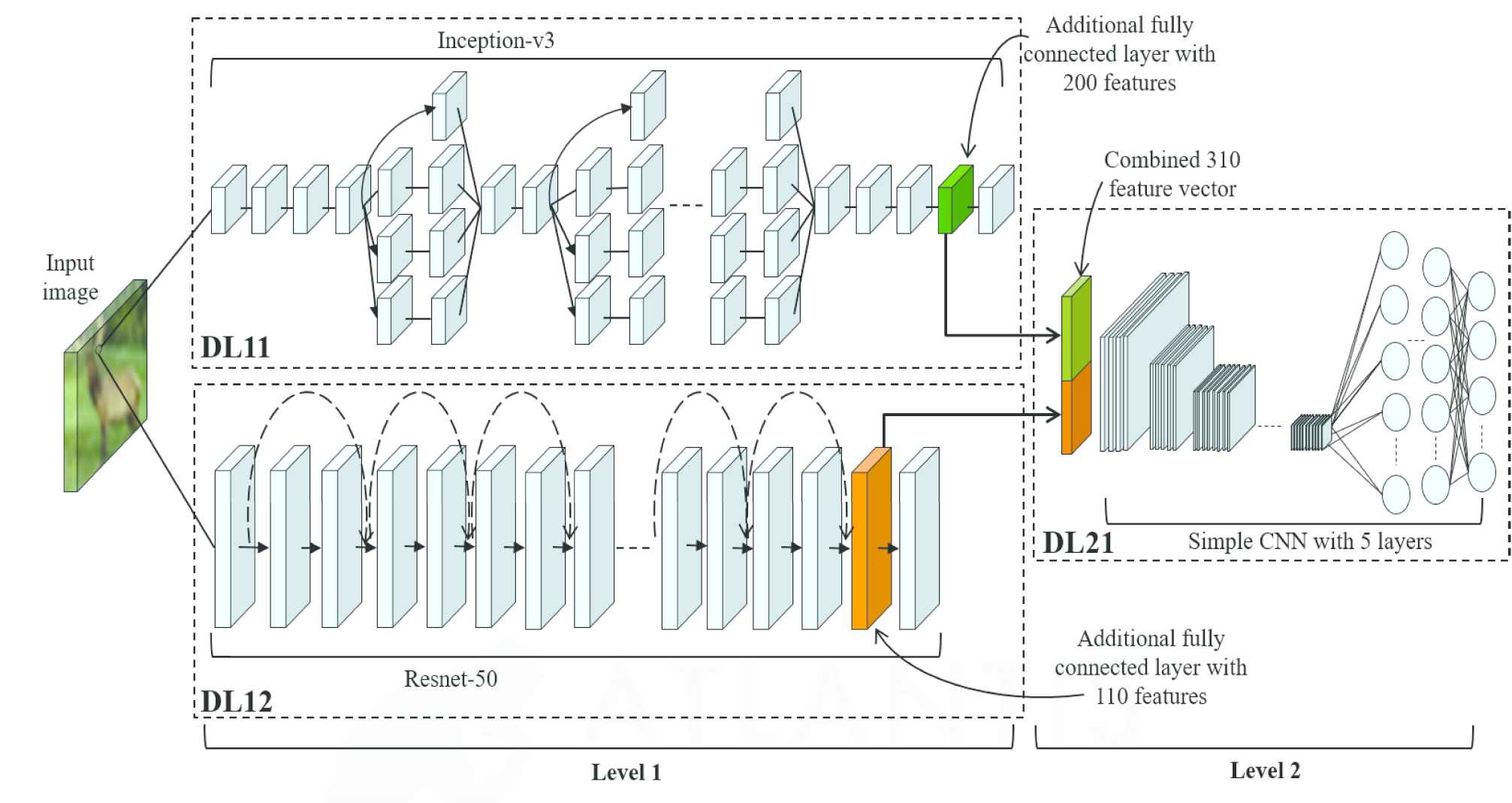
Improved two-level architecture with additional fully connected layer. Inception-v3 as DL11, Resnet-50 as DL12 connected to simple convolutional neural network (CNN) as DL21.
The figure shows that each input image is trained using the two networks in the first level. Next, the two feature vectors of the image are taken from the additional fully connected layer and concatenated to form the input to the second level with 310 features. The proposed architecture has shown an accuracy improvement from 97.2% using Inception-v3 and 96.8% using Resnet-50 to 98.04% that is a significant improvement. Figure 8 presents the confusion matrix that shows an improvement in most classes compared to the confusion matrices of the first level (see Figures 5 and 6). Table 3 summarizes the obtained results.
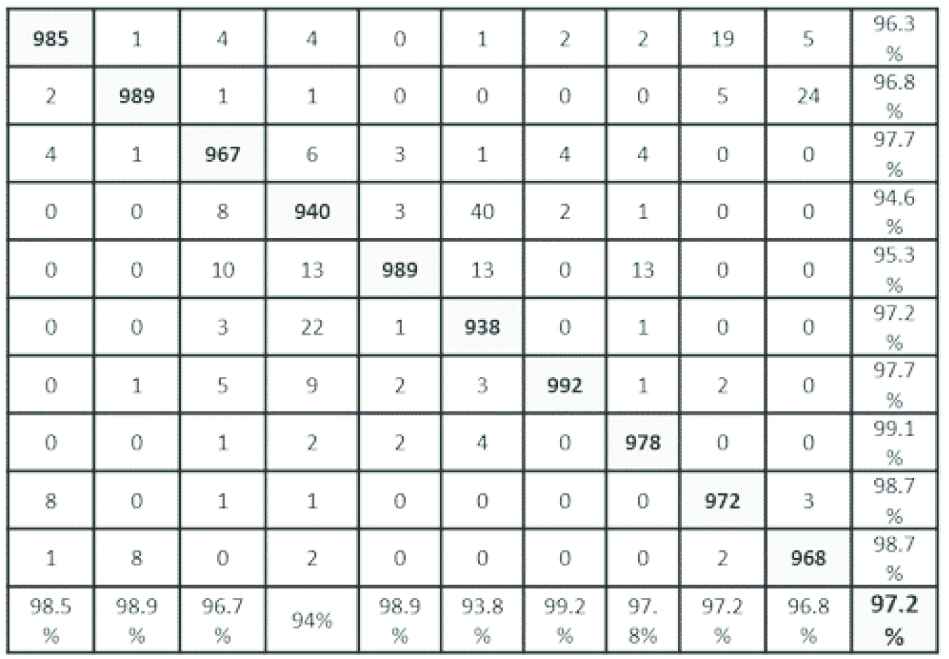
Confusion matrix of the Inception-v3 using CIFAR-10 dataset.
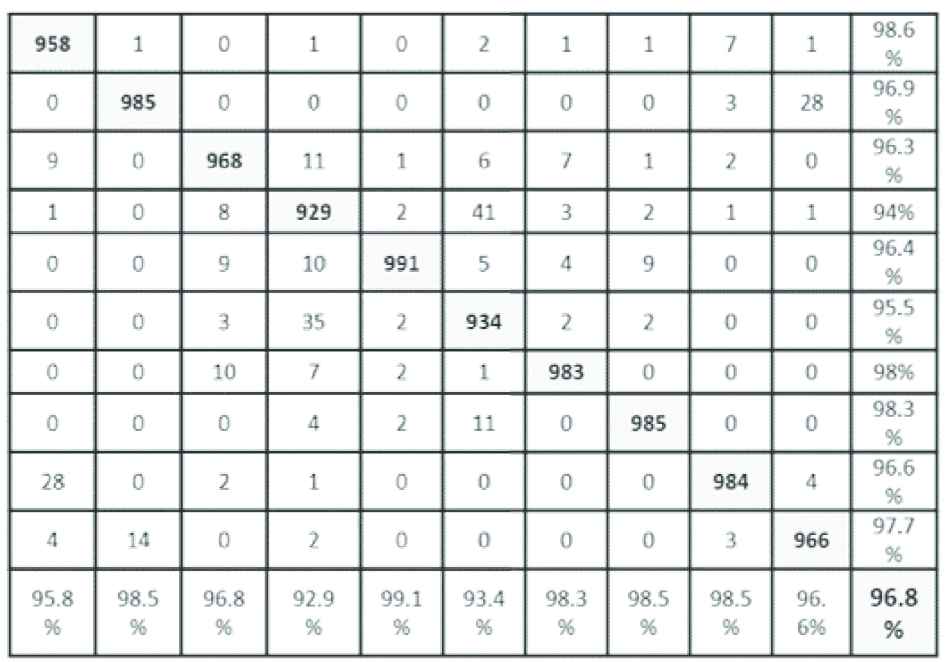
Confusion matrix of the Resnet-50 using CIFAR-10 dataset.
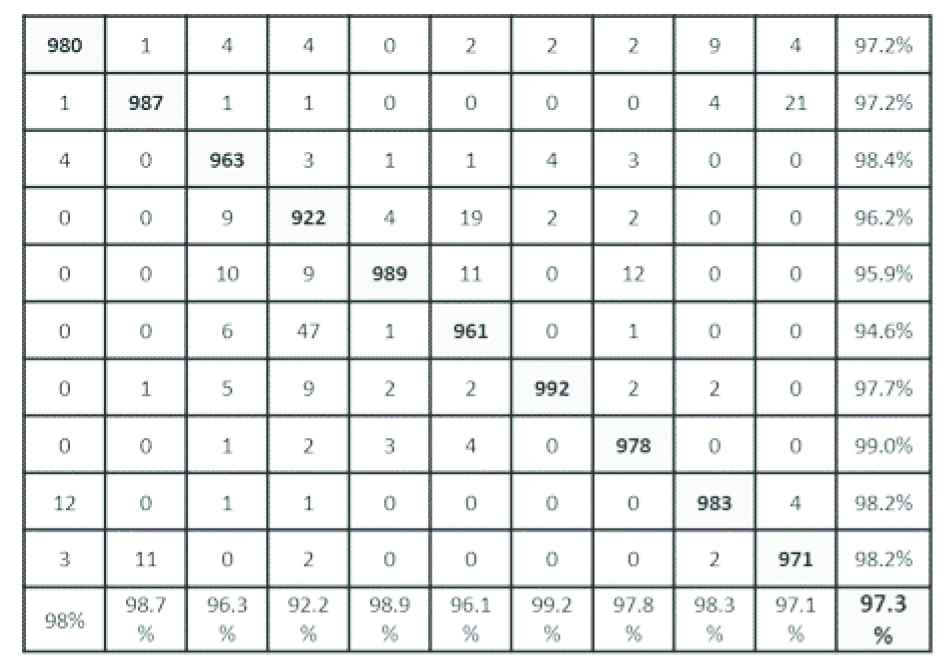
Confusion matrix of the multilevel architecture of deep learning (MADL) approach 1 using CIFAR-10 dataset.
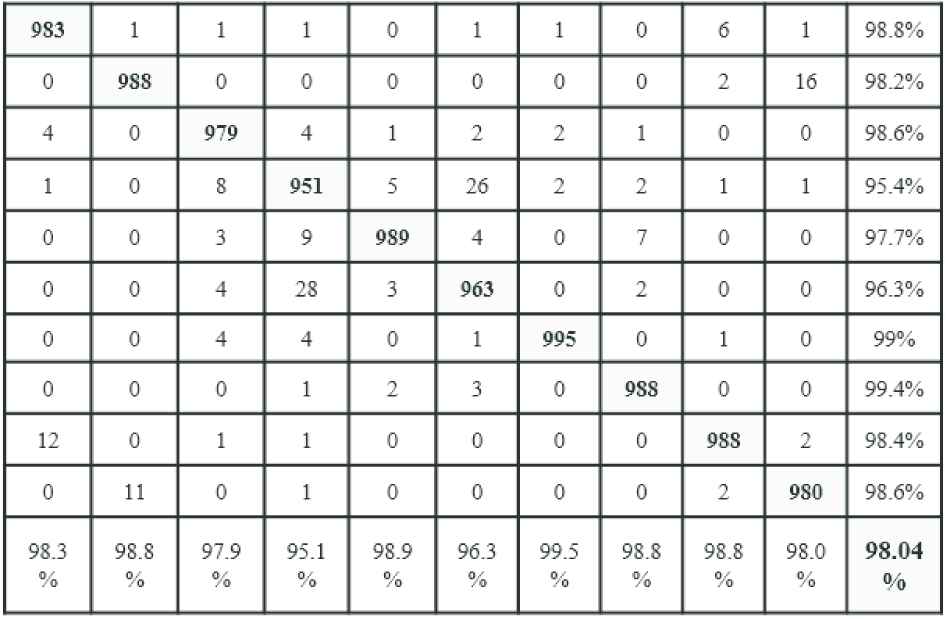
Confusion matrix of multilevel architecture of deep learning (MADL) approach 2 using CIFAR-10 dataset.
As the results suggest, MADL approach 2 outperforms MADL approach 1. Using MADL approach 1, the output of the first level that is 10 neurons, in the case of CIFAR-10 with 10 classes, is combined and passed to the second level. This approach dramatically reduces the number of features from level 1 to level 2. The high number of the useful features in level 1 is summarized in a vector of
With a view to further experiment MADL on different datasets, skin lesions ISIC dataset and three classes of food-101 dataset were used. The same structure represented in Figure 4 was used with the same network parameters indicated for CIFAR-10 except the number of epochs of the first level that is set to 10 epochs only. Table 4 presents the obtained results. For the skin lesions dataset, the accuracy obtained with Resnet is 77.2% and with Inception-v3 77.3%. The features extracted from the additional fully connected layer are concatenated and used to train the CNN in level two leading to an accuracy of 80.8% that is an improvement of 3.5%. For Food-101 dataset, Resnet and Inception-v3 gave an accuracy of 96.1% and 96.5%, respectively. The combination of the two networks gave an accuracy of 97.1%
| Dataset | Level 1 Acc. (%) | Level 2 Acc. (%) | Improvement |
|---|---|---|---|
| CIFAR-10 | 96.8 | 98.04 | 0.84 |
| 97.2 | |||
| Skin Lesion | 77.2 | 80.8 | 3.5 |
| 77.3 | |||
| Food-101 (3 classes) | 96.1 | 97.1 | 0.6 |
| 96.5 |
Results of the datasets experimeted with MADL.
As the results in Table 4 manifest, for all the datasets experimented, we notice a significant improvement from level 1 to level 2. The improvement using MADL for CIFAR-10 is 1.24% compared to Resnet-50 and 0.84% compared to inception-v3. For skin lesion dataset, the improvement is 3.5%. For Food-101 the improvement is 0.6%.
5. CONCLUSION AND FUTURE WORK
This paper presents a DNN ensembling approach, namely, MADL. MADL is based on building several networks in levels where each network is trained and optimized separately. This approach breaks down the optimization of the networks to levels instead of optimizing one larger network. The proposed ensembling method also improves the accuracy compared to one single network. The paper also proposes an advanced customizable activation function that is comparable in its results to ReLU. MADL was experimented with CNN using two levels where the first level has Resnet-50 and inception-v3 and the second level has one simple CNN. Two fusion approaches were discussed, the first approach is taking the output layers of the networks in level 1 and feeding them to the network in level 2, while the second approach is introducing an additional fully connected layer to the networks in level 1 and passing the features from the additional fully connected layer to level 2. The experimentations showed that the second approach preserves more features and gives a higher improvement from level 1 to level 2. The experiments conducted on CIFAR-10 showed that the accuracy improved from 96.8% and 97.2% using Resnet-50 and inception-v3 respectively to 98.04%. Additional experiments were conducted using skin lesion dataset and 3 classes of Food-101 dataset. The improvement from level 1 to level 2 was 3.5% for skin lesion dataset and 0.6% for Food-101 dataset.
As a future work, more improvement can be done on the proposed advanced customizable activation function. The later can be experimented with MADL by training each separate network in MADL with a different activation function. This may lead to extracting diverse features.
ACKNOWLEDGMENT
The authors would like to thank Qatar National Library, QNL, for supporting in publishing the paper.
REFERENCES
Cite this article
TY - JOUR AU - Samir Brahim Belhaouari AU - Hafsa Raissouli PY - 2021 DA - 2021/02/08 TI - MADL: A Multilevel Architecture of Deep Learning JO - International Journal of Computational Intelligence Systems SP - 693 EP - 700 VL - 14 IS - 1 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.201216.003 DO - 10.2991/ijcis.d.201216.003 ID - Belhaouari2021 ER -