
Coreference Resolution Using Neural MCDM and Fuzzy Weighting Technique
- DOI
- 10.2991/ijcis.d.200121.001How to use a DOI?
- Keywords
- Coreference resolution; Fuzzy weighting; Text mining; Mention extraction; Kohonen neural network
- Abstract
Coreference resolution has been an active field of research in the past several decades and plays a vital role in many areas such as information extraction, document summarization, machine translation, and question answering systems. This paper presents a new coreference resolution approach by incorporating RoBERTa embedding with a neural multi-criteria decision making (MCDM) method. The proposed model does not use any syntactic and dependency parser. Mentions were extracted from the text with an unhand engineered mention detector and features were extracted from a deep neural network. Next, the problem is modeled in the form of effective parameters of the performance such as error rate reduction and enhances the F1 by Kohonen MCDM neural network. The weights assigned to the features represent their importance and suggests the best reference for a mention where such weights are computed using a fuzzy weighting method. Comparing to state-of-the-art coreference resolution models, the simulation results show significant improvements for the proposed approach on different datasets in terms of precision and recall and achieving marginal improvements on the following datasets: English CoNLL-2012 shared task (+3.1 F1), Yahoo's news site (+6.6 F1), and English Gigaword (+7.04).
- Copyright
- © 2020 The Authors. Published by Atlantis Press SARL.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
The process of finding co-referent mentions (mentions that refer to the same entity in real-world) in a document is called coreference resolution which is considered as one of the most important challenges in the field of text processing. The process humans use to identify co-referent mentions in conversations or texts is still not clear. Also, it is still difficult to examine the knowledge of this procedure. Hence, coreference resolution, an effective process in dealing with subjects such as information extraction, machine translation, text summarization, and Q & A systems, is considered as an important issue in the field of natural text and language processing. Coreference resolution has been an active research topic over the past four decades, but its complete solution has not yet been presented. The presented solutions have at least three important drawbacks. Firstly, the accurate computational model is not provided to solve this problem. New approaches [1–3] for coreference resolution generally use deep learning and reinforcement learning, but they did not present an accurate computational model. Secondary, most of the coreference resolution problems can only be resolved using various knowledge resources including lexical knowledge, syntactic knowledge, world knowledge, and semantic knowledge. Currently, most of the coreference resolution systems [3–6] are not equipped with these knowledge resources. Thirdly, most of the machine learning methods in this field has been done in the English language and apply them to other languages leads to challenging in the time-consuming task of creating annotation documents.
In the proposed approach, we tried to improve the accuracy of the coreference resolution by extracting better features and providing a better architecture than previous approaches [1–3,7]. For this purpose, the RoBERTa [8] method has been used for considering the syntactic and semantic knowledge and extracting correct mentions with different length from the text. Better contextual information compared to existing works is provided to the mention detection system using this idea. Then, candidate antecedents are ranked accurately for the intended mention by multi-criteria decision making (MCDM) structure, based on the Kohonen neural network. MCDM is designed to deal-with problems of different number of choices. This approach includes multiple stages such as, identifying the goal of the decision-making process, selection criteria, selection of alternatives, selection of the weighing methods, and aggregation [9]. First step involves the correct identification of the goal or the final output of the decision-making process. In the second step, independent and consistent criteria are selected which should have a miserable and similar scale and should be inter related with the alternatives. In the third step, available and comparable alternatives were selected. In the fourth step, the importance of each criteria is identify which can be determined using weighting methods. In final step, the best alternative is selected from available options by desired ranking method. The neural MCDM model is an accurate computational model that improve F1 on the test set of the English CoNLL-2012 shared task by 3.1. On one hand, using the neural network for decision making has the advantage of parallel execution. Therefore, it has a great effect on reducing execution time. On the other hand, considering all features and their degree of importance lead to accurate ranking alternatives. Also, we directly consider all spans in a document as potential mentions and the mention detection accuracy is improved in comparison to the newest method of mention extraction [1]. The rest of the paper is structured as follows. The related research is provided in Section 2. In Section 3, the proposed model is presented. In Section 4, the experimental results of this study are presented considering CoNLL-2012 [10], MUC6 [11], and English Gigaword [12] datasets. Finally, the conclusion is drawn in Section 5.
2. RELATED WORKS
Coreference resolution models generally divided into three categories [13]: (1) mention-pair model, mention-ranking model, entity-level model. The mention-pair model operates based on a pair of mentions in which, two mentions are either co-referent or not; then, by combining all the co-referent mentions, the coreference chains are identified in the document [14–16]. (2) In the mention-ranking model, instead of exploring whether two mentions are co-referent or not, by searching among a group of mentions, the best candidate for desirable mention is found [5,17,18]. (3) The entity-level model categorizes each mention with the previous entity instead of categorizing each mention with the previous mention. As a result, it creates a collection of mentions for each entity. This approach usually uses clustering methods [15,16,19,20].
In general, coreference resolution methods are divided into rule-based methods, machine learning-based (statistical), and deep learning-based groups. In rule-based methods [21–28], a collection of rules are handwritten by experts. These rules are implemented in an orderly manner to specify co-referents in the text. One of the advantages of the rule-based method is a high level of accuracy and simplicity in design. However, this method has low flexibility so that experts should register the system from scratch for any natural language. Machine learning methods are also classified into supervised and unsupervised categories. The former, use the educational data for learning the system that must initially be written by individuals [15,20,29,30]. On the other hand, no educational data (or at least very little data) are required in unsupervised methods [31,32]. However, the accuracy level of this method is currently too low to solve the coreference resolution problem.
New methods of coreference resolution [1,4,5,7,17,18] use deep neural networks. One of the main advantages of using deep neural networks is the use of raw text in the input of the model so that useful features are extracted from the text within the network itself and without human intervention. In addition, these methods use vectors (word embedding) to represent words and describe semantic relationships between them. Although more recent deep learning works in this area have used cluster-level information and such information is necessary to prevent the connection of non-co-referent mentions and the formation of co-referent chains, these methods have still a lot of shortcomings such as inappropriate cost functions, great dimensions, and inappropriate architecture. Accordingly, the proposed approach has tried solving these problems by using contextual, semantic and syntactic information for better representation of spans and neural MCDM method for accurate ranking candidate antecedent and better detection rate of co-referent mentions. Peng et al. [33] proposed an emergency decision-making approach based on a weighted distance-based approximation (WDBA) method which can obtain the optimal alternative without counterintuitive phenomena and possess a strong ability to differentiate the optimal alternative. They also proffered a new score function for q-rung orthopair fuzzy number (q-ROFN), which takes the hesitation information into consideration that reduce the information losses. After this idea, Peng et al. [34] proposed a new MCDM method by means of the q-rung orthopair fuzzy weighted exponential aggregation (q-ROFWEA) operator and q-rung orthopair fuzzy exponential weights which have a wide range to describe the real case. They also proffered a new score function of q-rung orthopair fuzzy number (q-ROFN) for solving the failure problems when comparing two q-ROFNs. In this paper we proposed MCDM method based on the Kohonen neural network where the weights of criteria are calculated by the fuzzy method and neural structure for decision making leads to we can accurately find appropriate candidate antecedent for the desired mention.
3. PROPOSED MODEL
In this section, the proposed model, along with the building formulation process is discussed. The proposed model consists of two parts. In the first part, mentions are extracted from the word sequence by pre-trained language models and deep neural networks. Then, in the second part, co-referent mentions are identified by the MCDM method.
3.1. Mention Detection
The first phase in coreference resolution is mention detection. In this phase, mentions in the text such as named entities [35], noun phrases and pronouns are identified and extracted. This is done through the following steps (token representation, span representation, and mention scoring). Each word or token in the input sentence is a combination of two vectors (character embedding and word embedding) to preserve semantic and syntactic information. RoBERTa [8] was used for embedding words because this method uses a pre-trained language model and considers the probabilities of a sequence of words. RoBERTa is designed to pre-train deep bidirectional representations from the unlabeled text by jointly conditioning on both left and right context in all layers. We fine-tune the pre-trained RoBERTa model to desire world knowledge in model. Consider the input document D contains T word. Assume vector representation of each word is
In Eq. (1) W's are model parameters of each unit;
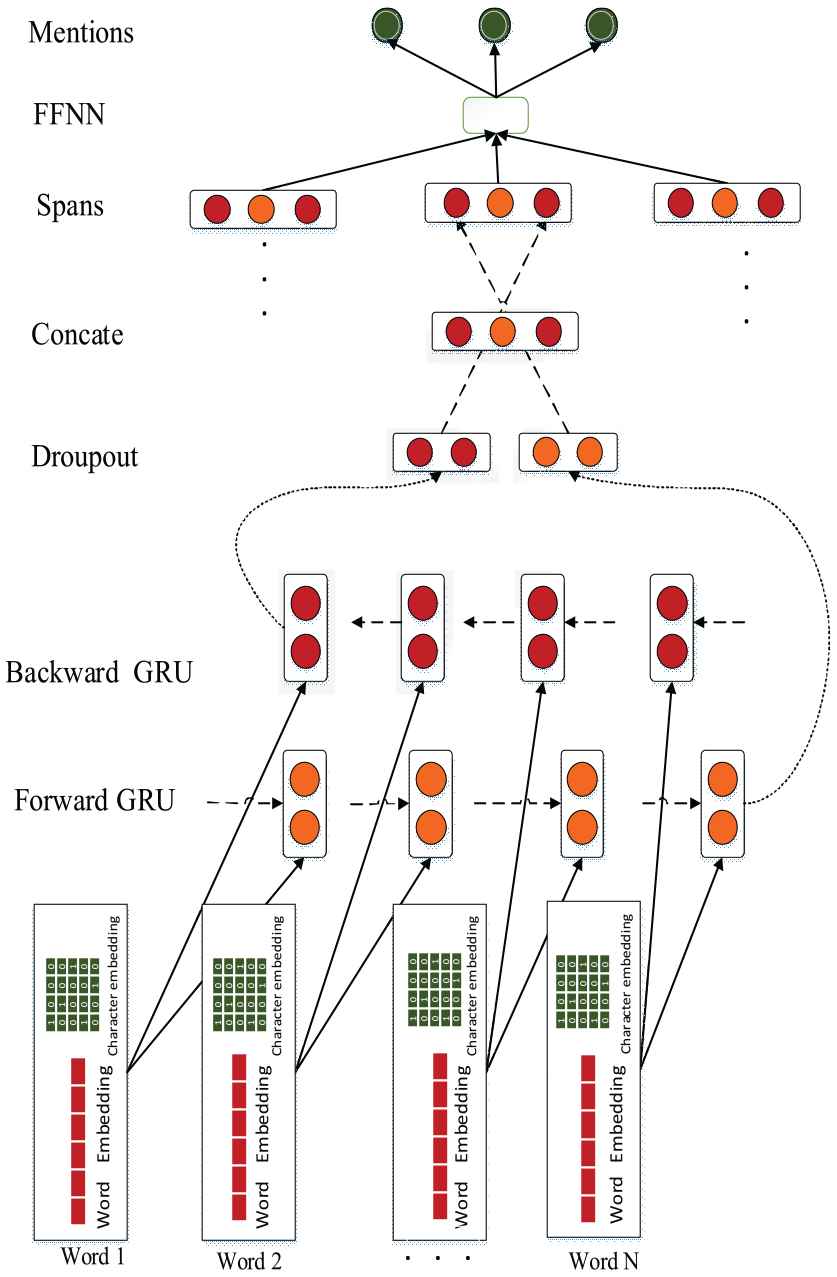
Structure of the proposed model.
We concatenate the above span information. This span information contains a feature vector
After extracting vector representations
3.2. Detecting Co-referent Mentions
After detecting mentions, to detect co-referent mentions we formulate the problem as MCDM problem. In this idea, alternatives are candidate antecedents for each mention and features are criteria. We use the following stages to detect co-referent mentions.
3.2.1. Decision matrix
To make a decision, the problem should be formulated using a matrix. For each mention
In Eq. (11),
3.2.2. Scaleness of the matrix P
The measurement scales of the quantitative features can be different. For this reason, performing basic math operations before scaling or equalizing the scales is not allowed. Therefore, considering Eq. (12), every
In this way, all columns of the matrix have an equal length unit and, therefore, their overall comparison will be easy.
3.2.3. Calculation of the weight of features
The geometric mean of each row and the weight of the i-th feature are calculated by Eq. (13) [37].
An indicator of the weight and importance of the i's feature for every mention in the text is obtained by Eq. (14).
Considering Eq. (14), to generalize the above-mentioned method into the fuzzy state, the classic operators must be replaced by other operators like fuzzy sum, fuzzy multiplication, converting numbers to trapezoid fuzzy numbers, etc. Therefore, steps A, B, and C should be followed:
In this step, the paired matrix, the elements of which are trapezoid fuzzy numbers, is identified by the decision-maker. If the preference of the i-th element is shown as
To calculate the features’ weight with the fuzzy technique, the geometric mean of each row of comparison matrices is calculated by Eq. (15).
Then, the fuzzy weight is obtained by Eq. (16) [37,38].
The final weight of features is calculated by considering the combined method for each mention.
In this step, the weights are assigned to features by considering the values of feature for each mention and candidate mentions in the text. The total weight is considered to be one. It should be mentioned that relative importance (weight) is an indicator of the feature's priority in the decision-making process. These weights are calculated by Eq. (17) and by the integration of the vector
3.2.4. Weighting the decision matrix
To consider the weight of features in the decision matrix, it is necessary to multiply each column of the matrix by the calculated weights according to Eq. (18).
3.2.5. Normalization of the matrix M
Weighting the decision matrix makes the matrix droplets have small values. For a matrix to be considered as a neural network input, a normalization step is required. The relationship is used to normalize the weighted matrix.
3.2.6. The final ranking of candidate antecedents by Kohonen neural networks
The network used in the proposed approach has n input and a fixed number of neurons in the output layer. The number of output layer neurons can be considered constant or variables. The number of samples in the training set is derived from the number of output neurons. Examples of training are representative of the alternatives and should, therefore, be selected to cover all the possible situations. As the input matrix to the network is normal, the values of the instruction samples should be such that the interval [1 and 0] is fully covered.
The neighboring function is shown in Figure 2. The value of
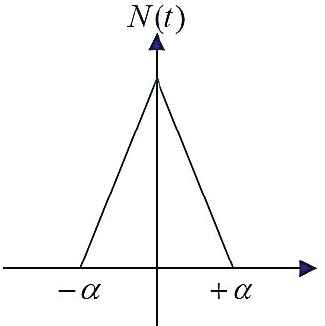
Neighborhood function employed in the Kohenon network.
In Eq. (22),
In this way, candidate antecedents for the considered mention based on their features are ranked. In this way, candidate antecedents with a higher rank (highest rank is 1) are more closely related and more similar to the intended mention, and the probability of their coreferention is higher. The block diagram of proposed approach is shown in Figure 3.
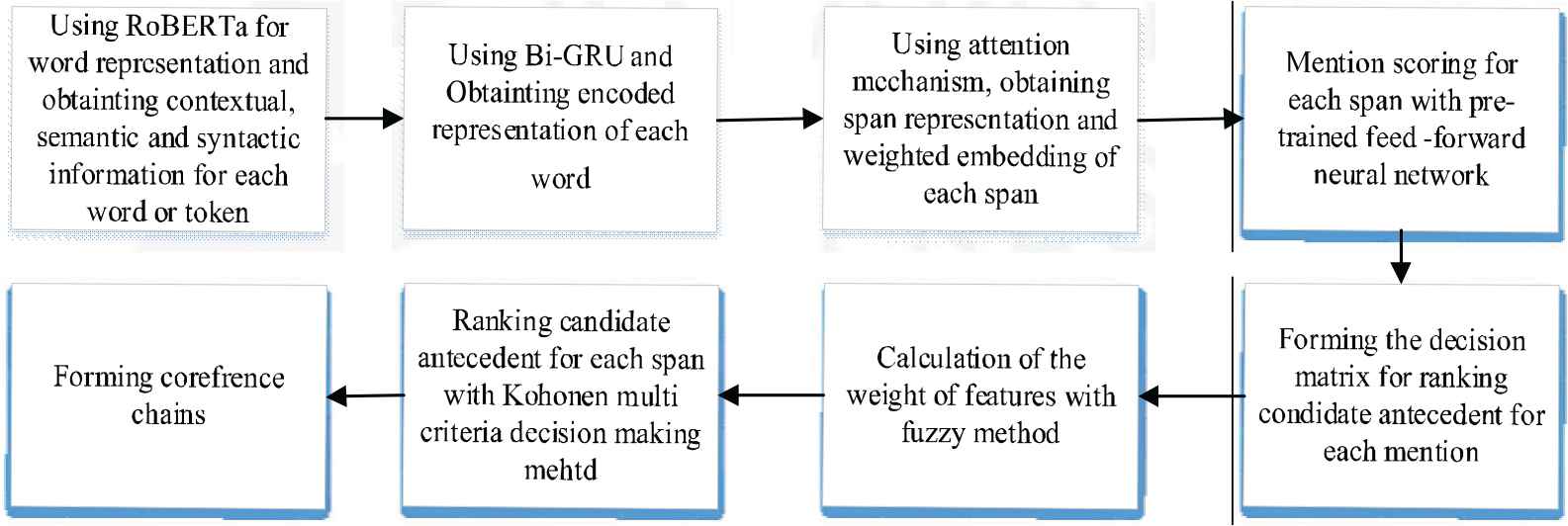
Block diagram of proposed approach.
4. EXPERIMENTAL RESULTS
4.1. Datastes
To evaluate the effectiveness of the proposed approach, we use four datasets in our experiments. The first dataset is CoNLL-2012 [10] shared task which is a standard coreference resolution corpus for multilingual languages (English, Chinese, and Arabic). We use the English coreference resolution data from the CoNLL-2012 shared task in our experiments. This dataset contains 2802 training documents, 343 development documents, and 348 test documents. The training documents contain on average 454 words and a maximum of 4009 words. The second dataset is the (Message Understanding Conference) MUC6 [11] which was produced by Linguistic Data Consortium (LDC) and contains 318 annotated Wall Street Journal articles, the scoring software and the corresponding documentation used in the MUC6 evaluation. The third dataset is English Gigaword [12] which is intended to evaluate the power of identifying the named entities. This dataset is a comprehensive archive of English news articles and has been used at Pennsylvania University for many years. The fourth dataset is Yahoo's news site which is manually annotated and contain 100 news document.
4.2. Implementation and Hyperparameters
We extend the original Tensorflow implementations of RoBERTa. We fine-tune all models on the CoNLL-2012 English data for 19 epochs using a dropout of 0.4, and learning rates of 1 × 10−4 and 2 × 10−3 with linear decay for the RoBERTa parameters and the task parameters respectively. We found that this made a sizable impact of 2%–3% overusing the same learning rate for all parameters. The hidden states in the GRUs have 200 dimensions. Each feedforward neural network consists of two hidden layers with 150 dimensions and rectified linear units.
4.3. Results
Average F1 in comparison with other methods: Table 1 compares the results of our system with state-of-the-art approaches [1,3–7]. The reported results are either adopted from their papers or reproduced from their code.1 The comparison is on the CoNLL-2012 test set, according to MUC (mention based) [40],
| Method | MUC | B3 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Prec. | Rec. | F1 | Prec. | Rec. | F1 | Prec. | Rec. | F1 | Avg.F1 | |
| [5] | 73.6 | 65.6 | 69.4 | 67.4 | 56.9 | 61.7 | 62.4 | 58.6 | 60.4 | 63.8 |
| [4] | 81.2 | 73.6 | 77.2 | 72.3 | 61.7 | 66.6 | 65.2 | 60.2 | 62.6 | 68.8 |
| [6] | 79.4 | 73.8 | 76.5 | 69.0 | 62.3 | 65.5 | 64.9 | 58.3 | 61.4 | 67.8 |
| [1] | 81.4 | 79.5 | 80.4 | 72.2 | 69.5 | 70.8 | 68.2 | 67.1 | 67.6 | 73.0 |
| [7] | 85.4 | 77.9 | 81.4 | 77.9 | 66.4 | 77.7 | 70.6 | 66.3 | 68.4 | 73.8 |
| [3] | 82.6 | 83.4 | 83.0 | 73.3 | 76.1 | 74.7 | 72.3 | 71.1 | 71.7 | 76.6 |
| [2] | 84.7 | 82.4 | 83.5 | 76.5 | 74.0 | 75.3 | 74.1 | 69.8 | 71.9 | 76.9 |
| Our method | 84.1 | 88.2 | 86.1 | 77.5 | 80.9 | 79.2 | 74.3 | 75.3 | 74.8 | 80.0 |
Results on the test set on the English data from the CoNLL-2012 shared task (test set).
To better investigate the process of ranking candidate antecedents for mentions, we also compared Kohonen and perceptron networks as follows:
Candidate antecedents ranking with perceptron network: To better investigate the process of ranking candidate antecedents for mentions, we also trained a perceptron network for decision making and compared its performance with that of the Kohonen. In order to use the perceptron network [42], it is essential to identify a series of input samples and their corresponding outputs for training. In supervised networks, the main issue is to determine the number of samples for training. In order to solve decision problems, the samples of the training set should be so that all the different modes of alternatives are included. The perceptron network outputs correspond to the sorted list of alternatives, so the number of neurons in the network output layer is equal to the number of states where the alternatives are relative to each other. The proposed network includes m alternative and n criterion, a network with m × n input and m! output. The learning parameter is set to η = 1. The output function is competitive so the neuron with the highest value would be set to one while the rest change to zero. The output function
Samples of training were obtained according to Eqs. (25–28).
By relocating the rows of the
Comparison of Kohonen and perceptron network for mention ranking: using the neural network for ranking candidate antecedents has the advantage of parallel execution. Therefore, it has a great effect on reducing computation. As shown in Table 2, the use of a perceptron network has increased run time and F1 on CoNLL-2012 development set to 76.7. When using supervised networks such as the perceptron network, the main problem is determining samples of the training set. The results of these types of networks are dependent on the variety of training samples. If the training samples are selected with enough diversity, the network can predict correctly in response to unseen data. In order to provide such examples of training in supervised networks, the rule of thumb is the more information we use, the better the results will be. Note that due to the intrinsic nature of unsupervised networks, such as that of the Kohonen, the characteristics of such networks are independent of the problem, and a fixed number of neurons should be considered in the output layer. Also, fixed samples are used to train the network. This is independent of the problem and does not depend on the number of alternatives. Therefore, a trained network can be used several times for different problems.
| Avg.F1 | ∆ | |
|---|---|---|
| – Our model (Kohonen network) | 79.9 | |
| – Our model (perceptron network) | 76.7 | −3.2 |
| – Glove | 77 | −2.9 |
| – ELMo | 75.9 | −4 |
| – RoBERTa | 75.2 | −4.7 |
| – Distance and width features | 75.6 | −4.3 |
| – Speaker and genre metadata | 76.6 | −3.3 |
| – String structure matching | 76.3 | −3.6 |
F1 reduction with delete or change the features, word embeddings, and ranking methods on the CoNLL-2012 development set.
Mention detection rate: As described in Section 3.1, we used bidirectional GRU for extracting spans from sentence and mention detection. We also used Recurrent neural network (RNN), long short-term memory network (LSTM), Bidirectional LSTM and GRU for this purpose. Table 3 compares the strength points of all RNN-based networks. as can be seen, bidirectional-GRU has a better performance than other types of RNNs, as GRU networks have better performance in long dependency modeling and clearly outperform simple RNNs. In addition, novel GRU outperform LSTM networks. We suggest that the reason for such superiority is that GRUs combine the forget and input gates into one update gate which makes it faster to compute. Moreover, bidirectional GPUs improve the performance of RNN in dependency modeling. Therefore, by using RoBERTa word embedding as the input of the network and considering the semantic information of words; mention detection and coreference resolution process are done significantly better than the previous methods.
| Prec. | Rec. | F1 | |
|---|---|---|---|
| RNN | 79.21 | 83.12 | 81.11 |
| LSTM | 81.39 | 85.98 | 83.62 |
| Bidirectional LSTM | 84.19 | 90.81 | 87.37 |
| GRU | 85.32 | 93.91 | 89.40 |
| Bidirectional GRU | 88.93 | 97.95 | 93.22 |
Mention detection power in all types of RNN-based networks.
Figure 4 compares the accuracy of detect mentions from spans in word sequences with that of other methods. as can be seen, in previous methods, the recognition accuracy of the mentions is significantly reduced with an increase in the length of the word sequence. However, in the proposed approach, this reduction is small. Also, for spans with more than five words, the accuracy reduction is negligible. The important advantage of the proposed model is the ability to detect unknown mentions which are not in the training set. As outlined in Liang and Wu [21], there is a large overlap between gold mentions and the development set. The proposed model can correctly identify 1059 mentions (394 mentions in the training set and 665 mentions that had not been seen in the training set) which were not recognized previously such as Lee et al. approach [1].
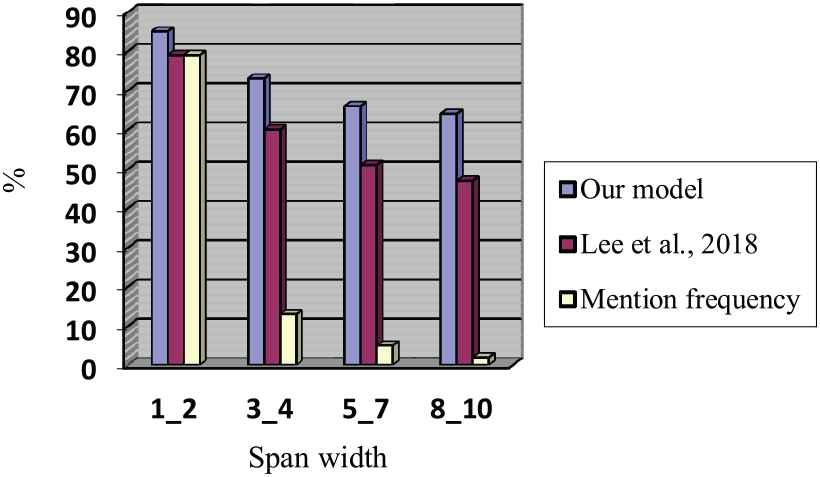
Mention detection rate based on span width in comparison with Lee [1] model.
Named entity detection rate: As mentioned in the mention detection section, named entities are also a part of the mentions in the text. In Figures 5 and 6 we evaluate and compare the performance of the proposed approach in terms of identifying named entities with the available methods in this field (Stanford-NLP,2 OpenNLP,3 LingPipe,4 SupersenseTagger,5 AFNER,6 AlchemyAPI7) on the English Gigaword dataset. The proposed approach uses a pre-trained neural network structure to identify the mentions, and this type of network is capable of automatically extracting features from entities and thus, this method has a better performance than all the ones compared. The precision and recall values for named entity detection rate were computed respectively by Eqs. (29) and (30).
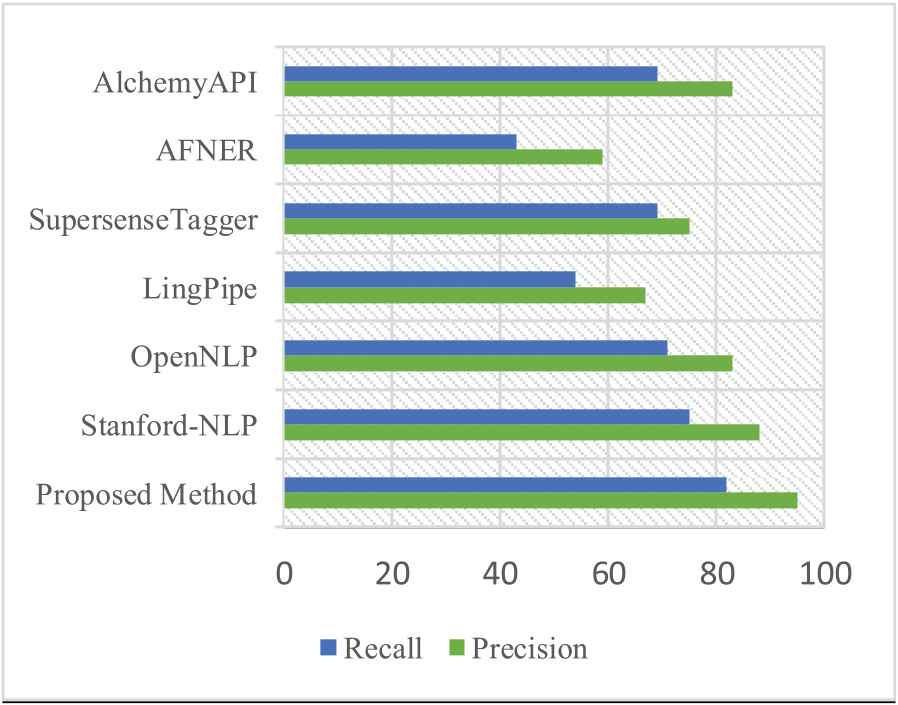
Precision and recall comparison for named entity recognition.
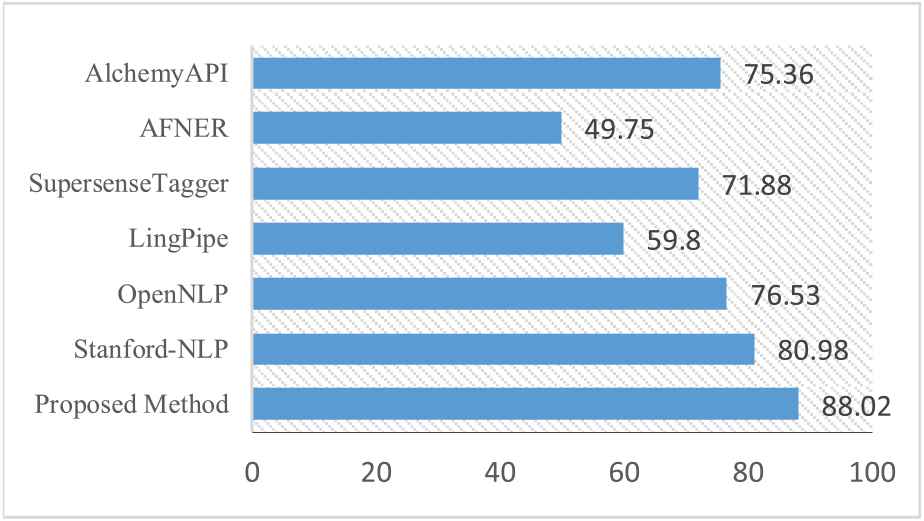
F1 comparison for named entity recognition.
As shown in Figure 6, the Avg.F1 for the proposed approach has improved up to 7.04, compared with previous methods. This is due to using RoBERTa method which provides morphological information and a solution to backoff for out of vocabulary words. The proposed approach can also identify rare named entities. Therefore, the combination of these two methods can be a suitable approach to identifying entities, in which the precision and readability values for each entity (such as persons, locations, and organizations) should be calculated separately.
Ablations: To show the importance of each component in our proposed model, we ablate various parts of the architecture and report the average F1 on the development set of the data.
Word embedding: In Table 2 GloVe [43], ELMo [44], and RoBERTa embedding methods have been compared in terms of impact on average F1. As the results show, the ELMo has a greater improvement on the F1 value, due to deep contextualized word representation, consideration of syntactic and semantic characteristics of words, and use of pre-trained language models. RoBERTa also performs better than both of these methods. As a result, in our approach, more useful semantic information is available to the system.
Features: The effect of the deletion of features from the proposed system is also reviewed. Eliminating the essential features of the coreference resolution, such as the distance between the spans and the lengths of spans has more effect on the reduction of F1 than the removal of the string structure matching feature. Also, performance degrades by 3.3 F1 without speaker and genre features.
Comparison with based coreference resolution systems: In Table 4, the proposed approach is compared with two base coreference resolution systems, Illinois [45] and Stanford [15] on Yahoo's news site. as can be seen, the results show significant improvement than base systems. Illinois system is only well-suited to the English language. This reason is that similar features are used for all languages, and hence, this system does not properly function for some languages like Chinese.
| MUC | B3 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Prec. | Rec. | F1 | Prec. | Rec. | F1 | Prec. | Rec. | F1 | Avg.F1 | |
| Our model | 81.0 | 73.8 | 77.2 | 70.3 | 63.7 | 66.6 | 68.6 | 61.8 | 65.0 | 69.6 |
| Stanford system [14] | 76.1 | 69.4 | 72.6 | 65.6 | 56.0 | 60.4 | 59.4 | 53.0 | 56.0 | 63.0 |
| Illinois system [45] | 52.3 | 57.2 | 54.6 | 63.6 | 52.5 | 57.5 | 54.3 | 54.4 | 54.3 | 55.4 |
Comparison proposed model with based coreference resolution systems on Yahoo's news site.
The reason for choosing strange news is the existence of a large number of events and verbs. Therefore, the proposed approach should best be evaluated using a large number of events. The proposed approach was highly efficient in evaluating the textual documents of the second test set for two major reasons. First, these documents contain a large number of events and propositions and that means more connections between the arguments’ mentions of these propositions. Second, various features and aspects of a mention are usually used in these texts that refer to that particular mention.
For example, to understand the content of an accident caused by a person, some words and phrases such as the name of the person, the role he played in the incident, his age, etc. are used. Therefore, common features, used for identifying co-referent mentions in coreference systems were unable to identify these co-referent cases. As a result, using the decision-making and weighting system can create a semantic knowledge in the processing system. In this way, the proposed approach can correctly identify more cases of co-referent mentions, compared to those coreference systems lacking such knowledge.
5. CONCLUSION
In this paper, a coreference resolution method, based on deep learning and fuzzy weighting method, was proposed. In this algorithm, a proper reference was chosen for the mention considering all the extracted features. MCDM for ranking candidate antecedents with Kohonen neural network optimizes the performance of the model during training and results in a better F1 for the proposed model than previous coreference resolution models. Also, using a fuzzy method for weighting features leads to the functioning of coreference resolution with higher accuracy which was a shortcoming of the previous systems. Moreover, using bidirectional GRU for finding long dependencies of words in spans works better than other RNN-based networks. The paper also makes a comparison between the proposed approach and coreference resolution based systems. The proposed approach properly manages the problem of coreference resolution with the lowest error rate. Additionally, the precision and recall values of the previous approaches were lower than those of the proposed approach. Although, the previous approaches showed slightly better performance on some datasets for a particular language, the proposed approach shows better performance for different types of data approaches CoNLL-2012 dataset (+3.1 F1) and Yahoo's news site (+6.6 F1). The F1 in named entity recognition rate on the English Gigaword dataset improved by 7.04. We suggest the following future research ideas:
Examination of other word embedding methods such as XLNet [46] as the input of a bi-GRU network.
Using other new RNNs for extracting spans from input vectors.
Using knowledge resources such as medical, syntactic, semantic, and linguistic knowledge for better word representation.
Using other criteria weighting methods such as MACBETH [47], DCE [48], PAPRIKA [49], etc.
Using Fuzzy-MCDM methods for ranking candidate antecedents.
CONFLICT OF INTEREST
The authors declare they have no conflicts of interest.
AUTHORS' CONTRIBUTIONS
Samira Hourali contributed to state of the art and model design, implementation, results analysis, writing - review & editing. Morteza Zahedi contributed to review & editing. Mansour Fateh contributed to review & editing.
Funding Statement
This research received no external funding.
Footnotes
REFERENCES
Cite this article
TY - JOUR AU - Samira Hourali AU - Morteza Zahedi AU - Mansour Fateh PY - 2020 DA - 2020/01/24 TI - Coreference Resolution Using Neural MCDM and Fuzzy Weighting Technique JO - International Journal of Computational Intelligence Systems SP - 56 EP - 65 VL - 13 IS - 1 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.200121.001 DO - 10.2991/ijcis.d.200121.001 ID - Hourali2020 ER -