
Individual Heterogeneous Learning with Global Centrality in Prisoner Dilemma Evolutionary Game on Complex Network
 , Yifang Zhang3, , William Danziger4
, Yifang Zhang3, , William Danziger4The permanent address of the author.
The present address of the author.
- DOI
- 10.2991/ijcis.d.200603.002How to use a DOI?
- Keywords
- Evolution game; Individual heterogeneity; Global centrality; Cooperation rate
- Abstract
The influence of individual heterogeneity on the evolutionary game has been studied extensively in recent years. Whereas many theoretical studies have found that the heterogeneous learning ability effects cooperation rate, the individual learning ability in networks is still not well understood. It is known that an individual's learning ability is influenced not only by its first order neighbors, but also by higher order individuals, and even by the whole network. At present, existing methods to represent individual learning ability are based on degree centrality, resulting in ignoring the global centrality of nodes. In this paper, we design a method for describing the heterogeneous learning ability by taking advantage of a pre-factor
- Copyright
- © 2020 The Authors. Published by Atlantis Press SARL.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
Cooperative behaviors are widespread in a biological system and human society [1]. However, understanding and explaining the emergence of costly cooperative behaviors among selfish individuals in social dilemmas such as the prisoner's dilemma game (PDG) and the public goods game remains a conundrum [2–4]. To a certain degree, the evolutionary game theory which assumes that individuals are boundedly rational has successfully explained the evolution of cooperation from various perspectives [5]. Nowak [6] systematically summarizes five mechanisms for promoting cooperation including kin selection, direct reciprocity, indirect reciprocity, network reciprocity, and group selection. In the real world, individuals generally do not interact with all other individuals, but only interact with some other individuals, thus forming a corresponding network structure. On a network with a certain structure, collaborators can form clusters to help each other, so that the level of cooperation can be maintained, which also creates space reciprocity [7]. The Evolution of Cooperation, written by Axelrod, first focuses on the impact of spatial structure on cooperative evolution [8]. In 1992, Nowak and May studied the prisoner's dilemma game on the grid and found that the spatial structure can not only increase the cooperative frequency but also produce rich spatial patterns under certain conditions [7,9]. Later, due to the rise of complex network theory, the research on spatial evolution game was pushed to a new climax.
In recent years, extensive research has been conducted on PDG on complex networks of various spatial structures, such as on rule networks: Szabó et al. adopt a random strategy updating rule to study the prisoner's dilemma game behavior on a square lattice [10]; Perc et al. systematically studied the impact of stochastic payoff variations with different distributions on the evolution of cooperation in the spatial PDG[11]. Inspired by Wu et al. [12,13], Szolnoki and Szabó studied the effects of individual heterogeneity on cooperative behavior in the prisoner's dilemma game on Kagome lattice and grid networks [14]. Yu and Wang study the PDG on square lattice by interacting the deterministic and Data envelopment analysis efficient rule into adaptive rules [15]. For small world networks: Santos et al. compared the differences in prisoner's dilemma behaviors between WS small-world networks and random regular networks generated by random exchange edges [16]. Ren et al. investigated the effect of randomness in both the topological randomness in individual relationships and the dynamical randomness in decision makings on the evolution of cooperation on homogeneous small-world networks [17]. Fu et al. studied the influence of degree heterogeneity on cooperative behavior based on the NW small world network model, indicating that appropriate heterogeneity can effectively promote the emergence of cooperative behavior in the network [18]. Santos et al. first studied the evolution of cooperation on scale-free networks [19–21] and found that BA scale-free networks could greatly improve the level of network cooperation. As a continuation of the work of [19–21], Gomez-Gardenes et al. study the effect of clustering on the organization of cooperation by analyzing the evolutionary dynamics of the “Prisoner's Dilemma” on scale-free networks with a tunable value of clustering [22], Pusch et al. also reached a similar conclusion [23]. Ren et al. proposed the preferential learning mechanism on PD games. Compared with no preference, the addition of preference mechanism can effectively improve the cooperation frequency in BA scale-free networks [24]. Recently, Szolnoki et al. found that the diversity in the reproduction capability, related to inherently different attitudes of individuals, can enforce the emergence of cooperative behavior among selfish competitors [25]. Here, Lima and Tarik study an agent-based model of the evolution of tag-mediated cooperation on ER graphs [26].
In addition to the network structure, it is also found that when using evolutionary games on complex networks to study cooperation issues, many other mechanisms also have an impact on cooperative behavior and evolutionary dynamics [27–31]. Yang and Chen found punishment is an effective way to sustain cooperation among selfish individuals [32]. Wang and Li introduce the concept of social influence into the model to enable cooperators and extortioners to be evolutionarily stable [33]. Qin and Chen reveal that the introduction of neighborhood diversity elevates the level of cooperation in various types of social dilemmas [34]. In the real world, both biological individuals and humans exhibit rich diversity or heterogeneity, such as individual learning to teach heterogeneity [14,35], heterogeneity in the income matrix [11,36], conformity-driven reproductive ability [37], degree of heterogeneity [18], and so on. Lin and Yang propose an opinion dynamics model to study the effects of heterogeneous influence of individuals on the global consensus [38]. The evolutionary game model research on complex networks found that the heterogeneity of individuals plays an important role in the emergence and maintenance of cooperative behavior. Motivated by degree heterogeneity research, an individual's learning ability algorithm based on node degree is proposed to study cooperative behaviors in both prisoners dilemma [39] and public goods game [40]. In this algorithm, different learning abilities are designed according to the degree of the player, and the change of the cooperation level of the network is observed accordingly. Therefore, the algorithm of individual learning ability based on node degree provides insight into how cooperative behaviors emerge and evolve in social dilemmas. Using node degrees to represent individual learning ability means that the individual's learning ability is only related to its first order neighbor's information.
Actually, in reality, the connection between individuals is not limited to local, and the individual's learning ability is also affected by global information. Therefore, this paper proposes a method for describing the heterogeneous learning ability by taking advantage of a pre-factor
The remainder of the paper is organized as follows: In Section 2, we describe the particularities of the evolutionary prisoner's dilemma game and the strategy updating rule used in this study. The main simulation results and theoretical analyses are presented in Section 3. Finally, the main conclusions are summarized in Section 4.
2. EVOLUTIONARY PRISONER'S DILEMMA GAME
Game theory provides a useful framework for describing the evolution of systems consisting of selfish individuals. The PDG as a metaphor for investigating the evolution of cooperation has drawn considerable attention.
In the PDG, two players simultaneously choose whether to cooperate or defect. Mutual cooperation results in payoff
 |
The prisoner's dilemma game's (PDG) payoff matrix.
This thus gives a simply rank of four payoff values:
The individuals can follow only two simple strategies:
The probability of a player
In this paper, the effects on the evolution of cooperation are studied by considering the inhomogeneous activity of learning ability in
3. EXPERIMENTS AND RESULT ANALYSIS
3.1. Experimental Data
In this section, we focus on the influence of node betweenness centrality of complex networks on the evolution of the networked PDG. Firstly, we construct networks using four typical models—the scale-free network (

The four example networks.
Two main mechanisms for forming a scale-free network: growth and preferred attachment. Because complex systems in the real world are evolving open systems, the BA network model essentially characterizes the most important characteristics of real networks. The specific travel rules of the small world model are as follows: starting from a one-dimensional ring nearest neighbor coupling network with N nodes, and then reconnecting all edges in the network randomly with probability
Complex networks have many special properties. The average shortest path length refers to the average of the shortest path lengths among all nodes in the network. The shortest path between any two points in the network is the minimum number of edges from one node to another. The average node betweenness of a network refers to the average of the betweenness of all nodes in the network. A node betweenness refers to the proportion of the shortest path between any two nodes passing through the node to all the shortest paths. The clustering coefficient is a parameter describing the clustering characteristics of the network. The degree of a network node refers to the number of other nodes connected to it. The attributes of the four networks constructed in this article are shown in Table 2.
| Average Shortest Path Length | Average Node Betweenness | Average Clustering Coefficient | Average Node Degree | Neighborhood Connectivity | |
|---|---|---|---|---|---|
| BA network | 2.67 | 0.07 | 0.01 | 3.4 | 4.58 |
| ER network | 2.10 | 0.06 | 0.18 | 4.11 | 4.65 |
| GD network | 2.96 | 0.12 | 0 | 3.16 | 3.22 |
| SW network | 2.35 | 0.35 | 0.3 | 4.05 | 4.29 |
The Statistics of the four networks.
The Grid network (a kind regular graph) have long average paths and high clustering (as the nodes tend to be densely connected in groups). The random
3.2. Experimental Analysis
In the following, we discuss the computer simulation results of our model on the four networks. This paper consider networks with finite node number
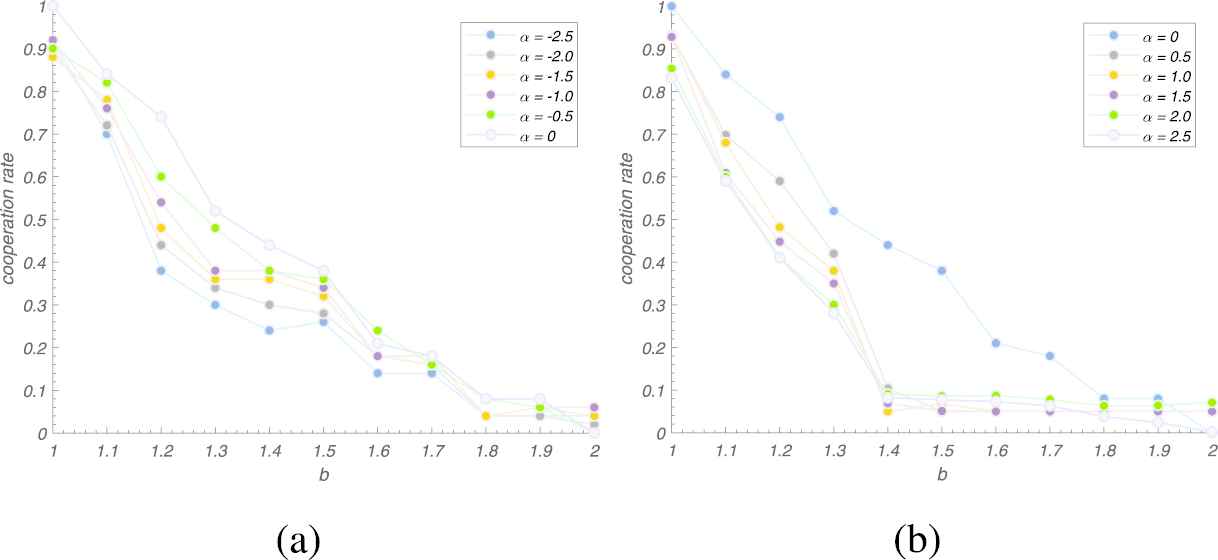
First, we investigated the overall change of the cooperation rate for different values of
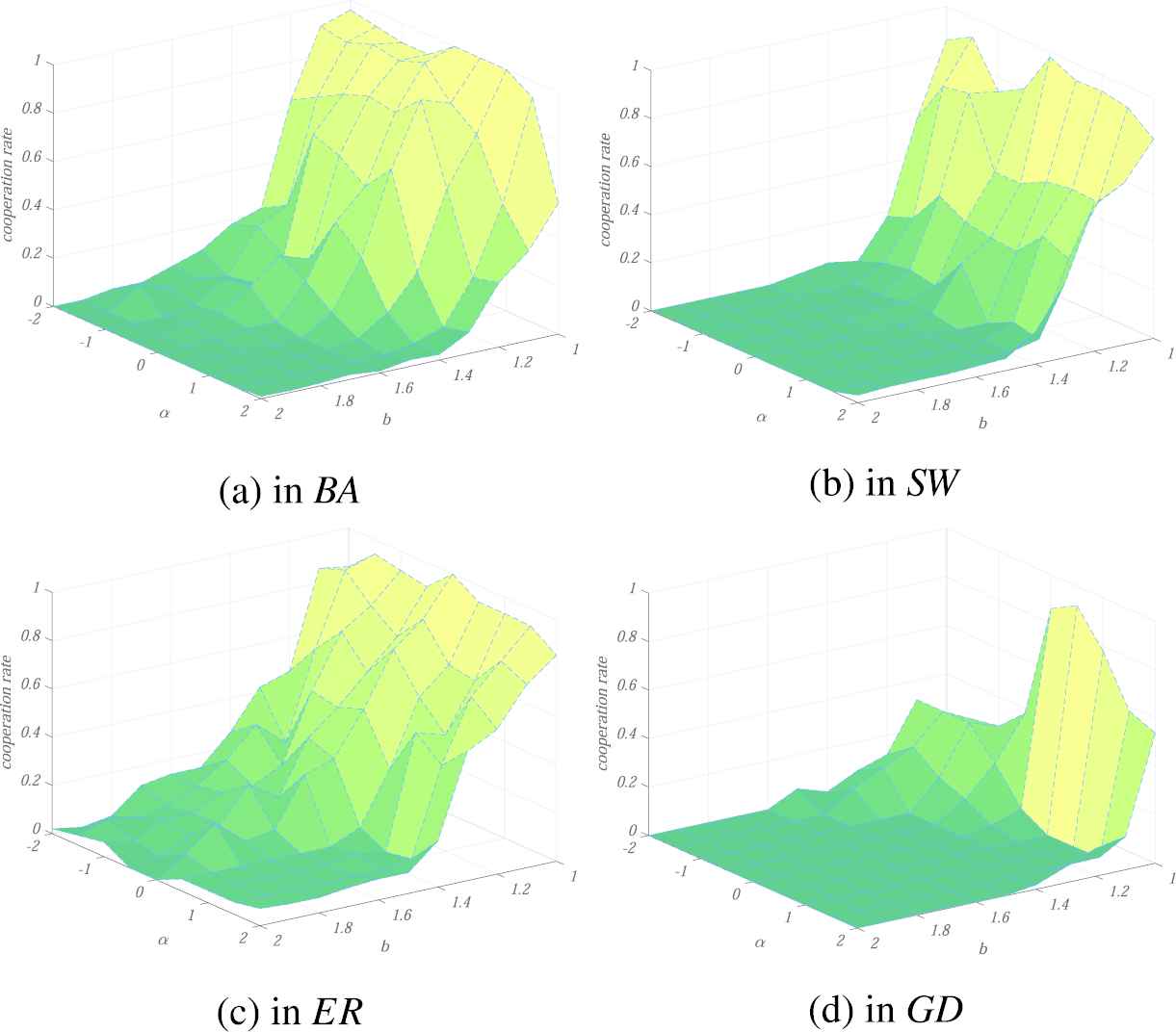
Overall change of the cooperation rate.
We can see the relationship between
The proportion of collaborators depends on the adjustment factor
For the prisoner's dilemma game on the

The change of the cooperation rate in the BA model.
In the

The change of the cooperation rate in the SW model.
For the prisoner's dilemma game on the
The change of the cooperation rate in the ER model.
In the

The change of the cooperation rate in the Grid network.
In the

The change of the cooperation rate with 10,000 iterations.
For the
In conclusion, when the network size is large enough and there are enough nodes in the network, the cooperator will get a chance to invade high-betweenness nodes. Once a node with high betweenness becomes a collaborator, its neighbors will cooperate. On the other side, once a collaborator invades a central node, its fitness will increase rapidly. And it will be difficult to be invaded by defectors. When
The advantage of our proposed method is that it introduces the pre-factor related to the betweenness to represent the heterogeneous learning ability of individuals, considers the global attributes of nodes, and provides a new perspective for understanding the important impact of global attributes of nodes on evolutionary games. The disadvantage is that due to the limited computing power of our computer, the number of nodes in the network model we construct is not enough, which may cause the obtained experimental results to be not fine enough, which can only indicate a general trend.
4. CONCLUSIONS
In summary, previous experimental analysis shows that the individual's heterogeneous learning ability can improve the level of cooperation. To have a more detailed observation about microscopic dynamical processes of diversity-promoted cooperation, we introduce the global attributes of individuals into individual learning abilities. In the paper, we design a pre-factor
Furthermore, in most cases, network cooperation is in a high level. Only in some middle values of
From the conclusions of this study, it is known that the influence of individual global attributes on game strategy is huge. It is not comprehensive to consider the global attributes of nodes only considering the local attributes of nodes. Therefore, our work may be much meaningful in understanding the evolutionary game research of heterogeneous learning ability on complex networks. Our research can be used to solve traffic network congestion problems, such as the problem of optimal control of regional signals. In the future we will make more research in this area.
CONFLICT OF INTEREST
The authors declare that they have no conflict of interest.
AUTHORS' CONTRIBUTIONS
The authors confirm contribution to the paper as follows: study conception and design: Z. Zhang, J. Ban; data collection: Y. Zhang; analysis and interpretation of results: Z. Zhang, Y. Zhang; draft manuscript preparation: Z. Zhang, Y. Zhang. All authors reviewed the results and approved the final version of the manuscript.
ACKNOWLEDGMENTS
This paper is supported by The Chinese the State 13 Five-year Scientic and Tech- nological Support Project (2016YFB1200402), the Big-Data Based Beijing Road Trac Congestion Reduction Decision Support Project (PXM2016014212000036), the Project of the Innovation and Collaboration Capital Center for World Urban Transport Improvement (PXM2016014212000030), and the Basic Research Business Fee Project of Science and Technology Innovation Service Building (110052971921/031).
REFERENCES
Cite this article
TY - JOUR AU - Zundong Zhang AU - Yifang Zhang AU - William Danziger PY - 2020 DA - 2020/06/17 TI - Individual Heterogeneous Learning with Global Centrality in Prisoner Dilemma Evolutionary Game on Complex Network JO - International Journal of Computational Intelligence Systems SP - 698 EP - 705 VL - 13 IS - 1 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.200603.002 DO - 10.2991/ijcis.d.200603.002 ID - Zhang2020 ER -