
An Integer Cat Swarm Optimization Approach for Energy and Throughput Efficient MPSoC Design
 , Nadia N. Qadri2, , Majed Alhaisoni4, Sajid Baloch5
, Nadia N. Qadri2, , Majed Alhaisoni4, Sajid Baloch5- DOI
- 10.2991/ijcis.d.200617.001How to use a DOI?
- Keywords
- Design space exploration (DSE); Multicore architecture; Integer cat swarm optimization
- Abstract
Modern multicore architectures have an ability to allocate optimum system resources for a specific application to have improved energy and throughput balance. The system resources can be optimized automatically by using optimization algorithms. State-of-the-art using optimization algorithm in the field of such architectures has shown promising results in terms of minimized energy consumption through configuration of number of CPU cores, limited cache sizes and operating frequency. We propose, in this work, a Cat Swarm Optimization (CSO) algorithm-based technique, Integer CSO (ICSO) for the design space exploration (DSE) of multicore computer architectures to find improved energy and throughput balance. The proposed integer variant of CSO algorithm demonstrates convergent behavior for all of design space parameters variations. The Pareto front proposed by ICSO is explored by using various SPLASH-2 benchmarks. Results show significant decrease in energy consumption without affecting throughput severely. Simulation results also validate the use of ICSO in DSE for multicore architectures.
- Copyright
- © 2020 The Authors. Published by Atlantis Press SARL.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
Most of the recent research in multicore architectures now focuses on optimum resource allocation according to the workload. This kind of architectures provide better application-specific performance/power ratio due to their ability to adapt as per application requirements. However at design time a designer has to explore a number of configurable parameters in order to strike a balance between energy and throughput of the system. This process is termed as design space exploration (DSE).
Many researchers have used different set of system parameters to tune against different figure of merits in this area of research. Commonly reported parameters used in literature are number of cores, frequency, cache sizes,
The size of problem search space can be reduced in some cases when there is a possibility to reduce the number of parameters by eliminating the less important parameters. But by reducing number of parameters, there is a chance to compromise on configurability of the system. On simulation side, we can reduce simulation time to some extent by different techniques of simulations i.e. statistical, sampling and parallel simulation [8]. Even if we reduce the simulation time by different techniques, evaluating all the possible configurations is an NP-hard problem i.e. a lot of time is required to investigate all. Therefore, exhaustive simulation is not possible in most cases. Hence there exists a need of some optimization algorithm to automatically explore a large design space and propose the designer a small set of optimal configurations to be simulated or tested.
Many researchers have used different approaches to obtain improved energy/throughput performance. A number of multicore systems support run-time configuration of voltage and frequency that is termed as Dynamic Voltage/Frequency Scaling (DVFS). To efficiently manage the temperature and energy consumption, various task scheduling, task migration and core consolidation policies can be applied using DVFS. A large body of research is available on DVFS but frequency scaling is not so efficient in many cases as with this technique large unused portions of the chip still dissipate leakage power. In this work, we use the concept of cache re-sizing and core switching along with frequency scaling for better optimization of energy and throughput.
For multicore processors, researcher must consider to best fit the trade-offs in energy consumption, throughput and area which makes it a multiobjective optimization (MOO) problem. The system parameter values in the design space are in integers which renders the problem as a combinatorial optimization problem. Therefore, we need some integer optimization techniques to explore the design space of such type of problems. Therefore, overall the problem becomes Multiobjective Integer Optimization Problem (MIOP). For the DSE in this field, Bio-inspired Algorithms are an important paradigm for consideration. These algorithms are very commonly used to find best and optimum solutions of complex problem in short time. Such algorithms present a shortest way to solve large and time sensitive complex design spaces. Researchers have used many extensions of Bio-inspired Algorithms in the area of DSE e.g. Ant Colony Optimization (ACO) [9,10], Particle Swarm Optimization (PSO) [3], etc.
In this paper, we propose Integer Cat Swarm Optimization (ICSO) algorithm for DSE of a multicore processor architecture. To the best of our knowledge, CSO has not been used with integer optimization specifically in the area of computer design and architecture. We have used the Integer Multiobjective CSO due to its good performance. It has been shown in the literature that the continuous as well as the integer version of CSO has superior performance compared to the well-known and widely used meta-heuristic algorithms such as multiobjective particle swarm optimization (MOPSO) and an improved version of nondominated sorting genetic algorithm (NSGA-II) [11,12]. More specifically, the superior performance of Continuous Multiobjective CSO Algorithm is reported in [12 Section 6.3], whereas the benefits of Integer Multiobjective CSO Algorithm can be witnessed from the results in [11]. The superior performance of the proposed Integer Multiobjective CSO is also clear from the results obtained in this paper. The main difference between the CSO and ICSO is that the parameters in ICSO take integer values and the updating of cats for next iteration is subject to some probability, which makes the ICSO suitable for the DSE problem in hand. In this paper, the ICSO algorithm is intended to support the dynamic configuration of a multicore platform as per work load requirements while maximizing the throughput and minimizing the energy. The algorithm takes number of cores, operating frequency and caches size as design space and searches for an optimal balance between throughput and energy consumption as objective. The algorithm generates a Pareto front between the two objectives i.e. throughput and energy consumption. The best configurations from the generated Pareto front set are evaluated for various benchmark applications using a cycle accurate simulator i.e. Micro Architectural and System Simulator for x86 (MARSSx86) [13]. Results obtained using MARSSx86 show significant reduction in energy consumption without a much impact over throughput.
The remaining paper is organized as follows: Related research in the field of Multicore Processor Architectures is discussed in Section 2. The design space representation is described in Section 3, followed by the implementation of ICSO on the given DSE problem in Section 4. Sections 5 describes the simulation setup and results are provided in Section 6. Finally, conclusion is presented in Section 7.
2. RELATED WORK
Recent research has produced various DSE techniques in the field of Multiprocessor System on Chip (MPSoC) [14,15]. In the following, we provide an account of some of the state-of-the-art approaches in this area.
Calborean et al. [6], proposed a framework called Framework for Automatic Design Space Exploration (FADSE). This tool solves single and MOO problems but is unable to handle large design spaces. Mariani et al. [1] presented a DSE scheme and an operating system (OS) layer for resource management which targets hardware and software configuration on a multicore platform. However, in this work, the authors took only two configurable parameters i.e. the number of cores and their operating frequency for a particular application. Moreover, their design space comprised of 8-cores whereas our proposed platform is generic because it can solve for any number of cores. Monchiero et al. [2], performed DSE for multicore architectures for parameters such as number of cores,
Givargis et al. [16], presented an optimization tool called Platune, which uses parameter independence for characterizing approximate Pareto sets without performing the exhaustive search over the complete design space. Their proposed approach require the specification of parameter independence through a dependency graph. Moreover, the framework supports the exploration of a MIPS based system only.
Researchers have also proposed evolutionary and bio-inspired based algorithms for exploring the design space of MPSoCs [3,4,10,17]. Palermo et al. [3], proposed a Discrete Particle Swarm Optimization (DPSO) scheme to perform DSE for hardware of a computing platform. The suggested scheme is aimed to efficiently analyze the workload and to produce an approximated Pareto set of system configurations for selected performance metrics. Although author claimed an 80% reduction in exploration timing as compared to exhaustive search. The effectiveness of the proposed methodology greatly depend on the large population size [18]. Though the efficiency of the algorithm increases with large population size but simulation time still remains a major challenge for complex applications. The exploration scheme considers only caches and CPU as their targeted design space also it lack validation of the proposed solution on any industrial benchmarks. Sheikh et al. [4], proposed combined optimization of performance, energy, and temperature i.e. termed as PET optimization. To find optimal solutions, the authors employed multiobjective evolutionary algorithm (MOEA) and Strength Pareto Evolutionary Algorithm (SPEA). The authors explored number of cores and switching frequency, however, and did not consider the cache size.
For multiprocessor platforms, Beltrame et al. [18], proposed design-time analysis strategies that provide multiple mappings for a target application. The authors optimized the energy and delay by decreasing the number of simulations required to find the mappings which provide optimal energy/delay trade-offs. Their proposed scheme takes only two parameters i.e. number of processor cores and size of cache. Singh et al. [19], presented a comprehensive survey on mapping methodologies focusing multicore systems. In their paper, the authors discussed various run-time and design-time mapping methodologies along with their advantages and disadvantages in details. Gordon-Ross et al. [5], performed DSE on system with a unified
Firstly, the DSE of multicore reconfigurable architecture is an integer multiobjective problem, while the algorithm proposed in the literature are either presented for single objective with a constraint or they are not suited for integer multiobjective problem as demonstrated in [11].
Secondly, we have also compared the proposed methodology with the previously presented nondominated Sorting Genetic algorithm-based DSE methodology and it is being shown that our proposed methodology dominates the NSGA-2 based method.
Lastly, we have use cycle accurate simulator, the MARSSx86 Splach-2 benchmark applications for the evaluation of the methodology. The obtained results show a significant reduction in energy consumption without a major impact on throughput.
3. REPRESENTATION OF DESIGN SPACE AND MULTIOBJECTIVE PROBLEM
As the complexity of SoC is increasing for multicore processors, one must consider a wide range of issues to best fit the trade-offs in energy consumption, throughput and area. This process is known as DSE involving a MOO problem. Theoretically, multicore architectures can contain many configurable parameters which makes the design space for the search space algorithm very large [5,20,21]. Our design space consists of those configurable system parameters which greatly affect the overall energy consumption and throughput. Our design space includes the cache size, number of cores and operating frequency as described below:
We take
Number of cores can be any integer ranging from 1 to N where N is the highest number of cores with which the architecture is considered to be equipped.
The set of operating frequencies of the MPSoC can be represented as
Our design space is purely integer where some of the decision variables do not take all integer values between their corresponding lower and upper limits. For the search space algorithm, we use integer index mapping from index based search space to actual search/design space. Here, actual search/design space consists of actual values of the system parameters while index-based search space consists of the corresponding indexes of the set of values in actual design space. In other words, the search space algorithm takes integer indexes of corresponding values in the design space. The corresponding indexes are internally mapped and demapped to actual values in the objective function, as shown in the following example.
For example, if we take our design space as number of cores, 1 to 16, cache sizes
3.1. Multiobjective Problem Representation
The objective we have chosen against these configurable parameters, is to have an optimal balance between energy consumption and throughput of the proposed architecture. The objective function being optimized is presented as follows:
In Equation (1),
4. CAT SWARM OPTIMIZATION
4.1. History
In 2006, Chu and Tsai [24] introduced a new optimization algorithm i.e. CSO, by modeling the behavior of cats. The authors investigated that cats take rest indolently most of the time when they are awake, move speedily when they are tracing some targets and they are curious about all kinds of moving things. Based upon their investigations, they modeled cats' useful behavior into two modes: Seeking mode (SM) (Resting state) and Tracing mode (TM) (Prey state). Originally, they tested their algorithm for single objective continuous optimization problems. Later on, Pradhan and Panda [25] extended this algorithm to multiobjective continuous optimization problems. Many researchers have also applied CSO in discrete and mixed integer problems involving single objective and multiobjective problems [26–28].
4.2. Proposed Approach
Engineering problems such as MPSoC have their design space in purely integer form and the problem is of combinatorial nature. We propose a new approach, ICSO, to solve this problem. Unlike continuous version of CSO, in proposed ICSO the position vector can take only integer values in each dimension. This approach uses the concept of Asynchronous Updating (AU) proposed for AU-PSO by Zhao et al. [29] for mutation. By using this approach, the integer variables in some of the dimensions have a probability to hold the previous values. This kind of treatment provides more chances to find a better solution by better exploring the solution space [29]. These changes make ICSO algorithm different from conventional continuous CSO algorithm. Similar to the continuous version of CSO, proposed ICSO also has two modes: SM and TM.
The ICSO algorithm uses two sets of cats i.e. one set of cats for SM and other for TM to find the optimal solutions. SM gives a global search option while TM provides local search. These two sets of cats jointly solve the optimization problem. For the ratio of cats in the two sets, a parameter called mixture/MR is used which is the ratio of the number of cats in TM to that of the cats in SM. A new parameter
Each artificial cat has its position, velocity, flag and fitness value. Position of each cat represents a candidate solution and its dimensions indicate the variables of the problem space which are cache size, number of cores (CPU cores) and operating frequency. In other words, position of any cat is the configuration consisting of the combination of
The pseudo code of the ICSO is listed in Algorithm 1 and the steps of the algorithm are discussed as following:
4.2.1. Parameters of algorithm
List of general parameters of ICSO algorithm includes swarm size (SwarmSize), dimensions of problem (D), mixing/mixture ratio (MR), maximum iterations to run algorithm (MI) and
| Swarmsize | MR | SMR | SRD | CDC | |
|---|---|---|---|---|---|
| 50 | 0.3 | 3 | 0.2 | 0.2 | 4 |
ICSO, Integer Cat Swarm Optimization; CDC, Counts of the Dimension to Change; SRD, Range of the Selected Dimension.
Parameters of ICSO algorithm.
SM has four special parameters: Seeking Memory Pool (SMP), Self Position Consideration (SPC), Counts of the Dimension to Change (CDC) and Range of the Selected Dimension (SRD). SMP is the number copies to be made of current configuration and SPC is a flag that indicates whether current configuration will be one of the configurations to be selected again or not. CDC indicates how many of the inputs from number of cores, cache size and frequency are to be varied. SRD defines the mutation ratio for the selected input.
TM has two parameters
The pseudo code of the ICSO is shown in Algorithm 1 and the detail, and steps of the algorithm are as following:
4.3. Algorithm
Following are the main steps in the ICSO algorithm.
Step 1. Initialize the algorithm parameters and Cats positions.
The algorithm parameters of ICSO are specified in first step i.e. the number of initial solutions (SwarmSize), MR, maximum number of iterations to run the algorithm (MI), asynchronous probability (

Step 2. Initialize the velocity and flag.
In Algorithm 1, lines 4 to 5 represent the second step. This step involves the initial settings of algorithm mechanism variables i.e. velocity and flags. Movements of cats are modeled by their velocities and their positions are defied based upon the values of velocities. Initially, random velocities (
Step 3. Evaluate objective function and find Pareto front.
In Algorithm 1, line 6 represents this step. Initially created cats are evaluated for the objective function at their position (
Step 4. Applying cats into corresponding mode.
After the initial/latest Pareto front is obtained, the cats are iterated through a loop and based upon their flag they are set into SM process (Section 4.3.2) and TM process (Section 4.3.1). In Algorithm 1, lines 9 to 21 represent TM and lines 22 to 34 represent SM. The overall step is implemented from line number 8 to 34.
Step 5. Repeat step 4 and so on, until the termination criterion is met.
In the last step, the termination criteria that may be specific number of iterations completed or ideal solution is examined, if it is satisfied
4.3.1. Tracing mode
In Algorithm 1, lines 9 to 21 represent the TM. This mode gives a local search option in exploring the design/search space. In this mode, a cat chases the target with high speeds which is mathematically modeled as large changes in the cat's position i.e. cat takes larger steps towards convergence. In the D-dimensional space, the position of the
Update the velocity of
whereCheck velocity for
Update the position of
whereEvaluate objective function at
Update
4.3.2. Seeking mode
In Algorithm 1, lines 22 to 34 represent the SM also known as resting mode of cats. This step in proposed integer variant of CSO differs from conventional CSO in updating technique (refer Section 4.2) for positions of cats. The steps involved in this mode are given below:
Make
Apply mutation operator to each copy.
Check for bounds of each dimension of all copies and update using the following equation.
whereEvaluate objective function at all mutated copies.
Update
Select a candidate randomly from j copies which replaces the older position (
5. SIMULATION SETUP
This section discusses the multicore configurable processor architecture and the simulation setup that is used to evaluate the proposed scheme. Our multicore architecture platform takes
We used Intel 486 GX embedded processor data sheet [38] for energy consumption calculations and frequency range. We evaluated the optimal solution, suggested by ICSO, using SPLASH-2 benchmark applications. All the applications were executed for the complete run and then design space parameters were modified based on results obtained using ICSO algorithm.
As the suggested architecture consists of a multicore platform, a set of SPLASH-2 [39] benchmark applications is chosen in order to perform the objective evaluation. A summary of the benchmark applications used for this purpose is given in Table 2.
| Sr. | Application | Description | Problem Size |
|---|---|---|---|
| 1 | Barnes | Employs Barnes-Hut algorithm to solve N-body problems [31]. | 16,384 particles |
| 2 | FMM | Uses a parallel adaptive Fast Multipole Method (FMM) to simulate the N-body problems [32]. | 16,384 particles |
| 3 | Ocean | Simulate large-scale ocean motility based on eddy currents and boundary currents [33]. | 258x258 grid |
| 4 | Water-NSquared | An improvised version of the original Water code in SPLASH [34,35]. | 512 molecules |
| 5 | Water-Spatial | Simulates the same molecular dynamics N-body problem as in the original Water-NSquared code in SPLASH [34]. | 512 molecules |
Benchmark applications used in this work.
6. RESULTS
6.1. Algorithm Results
As the main objective of the proposed approach is to achieve a balance between throughput and energy consumption of the SoC. In order to achieve this, the ICSO algorithm-based technique takes the configurations consisting of system parameters i.e. number of cores,
| Cache sizes(KB) | No. of cores | Frequency(MHz) | Throughput | Energy(J) |
|---|---|---|---|---|
| 2 | 1 | 10 | 1.02986 | 0.05486 |
| 2 | 1 | 25 | 2.57466 | 0.05487 |
| 4 | 1 | 33 | 3.39006 | 0.08506 |
| 2 | 2 | 33 | 3.99855 | 0.10973 |
| 1 | 3 | 33 | 4.40376 | 0.11688 |
| 1 | 5 | 33 | 4.90376 | 0.19480 |
| 1 | 6 | 33 | 5.07043 | 0.23376 |
| 1 | 7 | 33 | 5.20376 | 0.27272 |
| 1 | 8 | 33 | 5.31285 | 0.31168 |
| 1 | 9 | 33 | 5.40376 | 0.35064 |
| 1 | 10 | 33 | 5.48069 | 0.38960 |
| 1 | 11 | 33 | 5.54662 | 0.42856 |
| 1 | 12 | 33 | 5.60376 | 0.46752 |
| 1 | 13 | 33 | 5.65376 | 0.50648 |
| 1 | 14 | 33 | 5.69788 | 0.54544 |
| 1 | 15 | 33 | 5.73710 | 0.58440 |
| 1 | 16 | 33 | 5.77218 | 0.62336 |
| 32 | 16 | 33 | 5.78840 | 5.26334 |
| 64 | 15 | 33 | 5.79334 | 5.61560 |
| 64 | 16 | 33 | 5.82842 | 5.98998 |
ICSO, Integer Cat Swarm Optimization.
Pareto front (ICSO).
| NSGA-II Pareto-front | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Throughput | 6.188 | 5.775 | 5.389 | 5.363 | 5.050 | 5.046 | 4.950 | 4.570 | 4.554 | 4.541 | 4.537 |
| Energy consumption | 4.125 | 3.300 | 3.045 | 2.888 | 0.570 | 0.568 | 0.413 | 0.078 | 0.026 | 0.011 | 0.0108 |
| EDA Pareto-front | |||||||||||
| Energy | 0.13 | 0.47 | 1.26 | 2.36 | 2.52 | 3.4 | 4.36 | 6.24 | 8.3 | 10.58 | 10.84 |
| Throughput | 2.41 | 3.17 | 5.37 | 5.42 | 5.74 | 5.91 | 6.06 | 7.06 | 7.18 | 8.84 | 10.37 |
| True Pareto-front | |||||||||||
| Throughput | 5.828 | 5.793 | 5.772 | 5.204 | 5.070 | 4.404 | 4.004 | 3.404 | 2.579 | 1.650 | 1.031445 |
| Energy consumption | 5.990 | 5.616 | 0.623 | 0.273 | 0.234 | 0.117 | 0.078 | 0.039 | 0.039 | 0.039 | 0.038 |
NSGA-II, nondominated sorting genetic algorithm.
Pareto front energy consumption and throughput values for NSGA-2II and True Pareto-front.
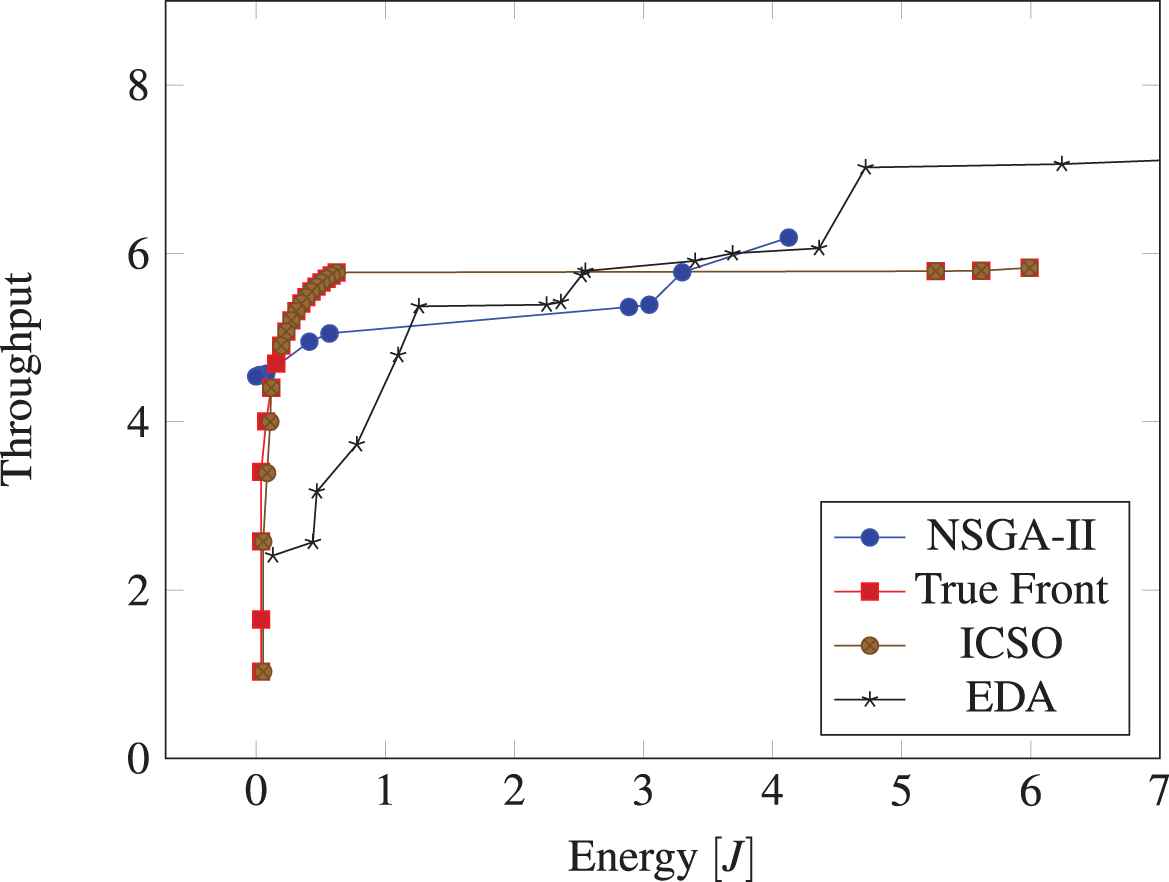
Pareto-front (set of nondominated solutions).
6.2. Evaluation of Pareto Set
To evaluate the Pareto set obtained using ICSO algorithm, we have selected two configurations from the set of twenty configurations shown in Table 3 for detailed simulations i.e. one configuration with minimum energy consumption, we call it energy efficient configuration and second configuration with maximum throughput, we call it throughput efficient configuration. Then, we have a default system configuration, which uses maximum available system resources, as a reference to compare the effect of system parameter variations in energy efficient and throughput efficient configurations. The default, throughput efficient and energy efficient configurations are shown in Table 5. The configurations given in this table are simulated with different SPLASH-2 benchmark applications (Barnes, Cholesky, LU, FMM, Water-Spatial and Water-NSquared) on MARSSx86 simulator. It should be noted that the default system configuration has maximum throughput but at the same time maximum energy consumption. The results of other two configurations, throughput efficient and energy efficient, are discussed with reference to this default configuration as following.
| Configuration Name | Cache Size(KB) | Core | Frequency(MHz) |
|---|---|---|---|
| Default system | 256 | 16 | 33 |
| Throughput efficient | 64 | 16 | 33 |
| Energy efficient | 2 | 1 | 10 |
MARSSx86; Micro Architectural and System Simulator for x86.
Selected configurations for MARSSx86 simulation.
A. L1 Cache
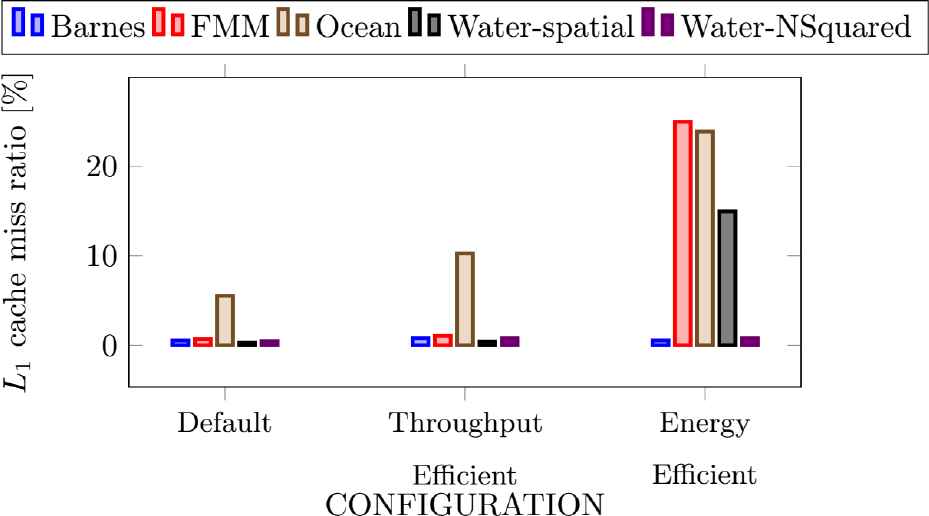
L1 cache miss ratio.
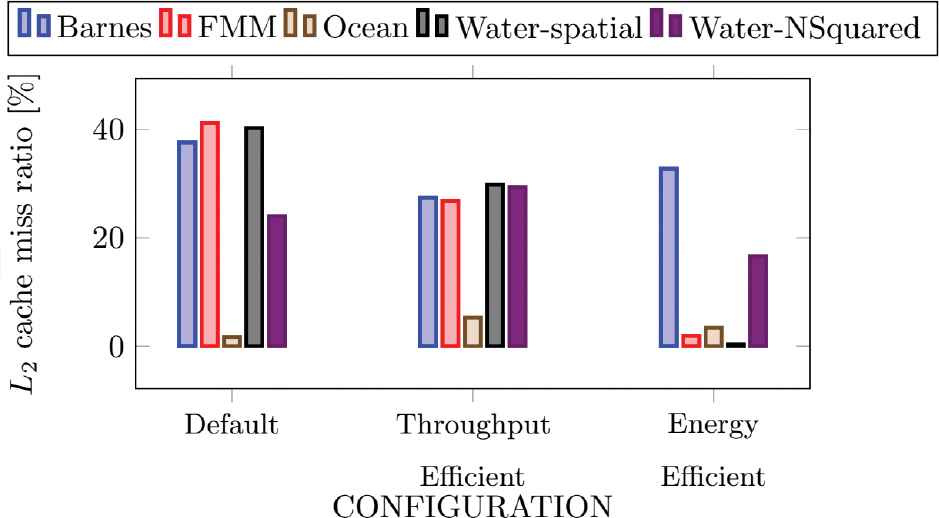
L2 cache miss ratio.
B. Number of Cores and CPU Frequency
Number of cores and CPU frequency has a significant impact on throughput and energy consumption. Increase in CPU frequency increases throughput greatly along with increase in energy consumption. Since for increased operating frequency, a system takes less time to complete a task and the overall average energy consumption can be more or less same. While on the other hand, throughput is not increased linearly by increasing the number of cores rather relationship between throughput and number of cores is governed by Amdhal's Law [41]. Throughput saturates for the most of the applications after scaling the number of cores beyond a certain limit [42]. Energy consumption is also increased with the increase of number of cores, which can be reduced by turning off of excess cores [43]. In selected pareto set, number of cores for default and throughput efficient configurations is 16, and for energy efficient it is 1. The frequency for these configurations is set to 33MHz, 33MHz and 10MHz for default, throughput efficient and energy efficient configuration respectively. These values of frequency and number of core are shown in Table 5, and are suggested by ICSO algorithm.
Results for normalized throughput and energy are shown in Figures 4 and 5 respectively. The figures clearly show that the default configuration has maximum throughput and at the same time maximum energy consumption. Throughput efficient configuration has reduced throughput and it also has reduced energy consumption. The minimum throughput is observed for Ocean benchmark i.e. 75% of the default value (see Figure 4). Whereas for all other applications less than 5% throughput reduction. The throughput efficient configuration shows decrease in energy consumption for all the applications (see Figure 5). Barnes application has shown least energy consumption i.e. around 10% of the default configuration. Whereas Ocean shows energy savings of up to 40% and for all other applications it is around 50%. The energy efficient configuration showed throughput reduction of more than 90% for all applications that is not desirable for most cases however this has resulted in highest energy savings of 90% or more (see Figures 4 and 5). Thus, results show that the throughput efficient configuration has desirable improvements in terms of both throughput and energy consumption.
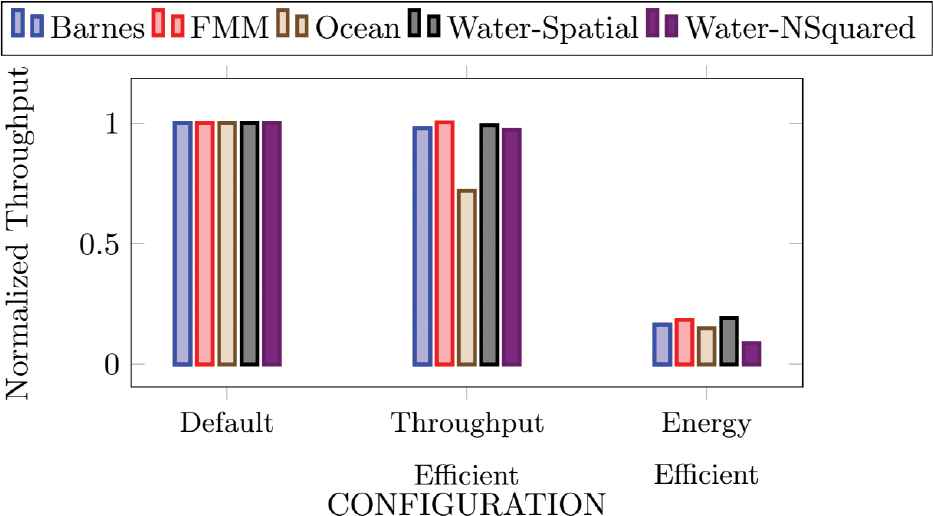
Results for normalized throughput.
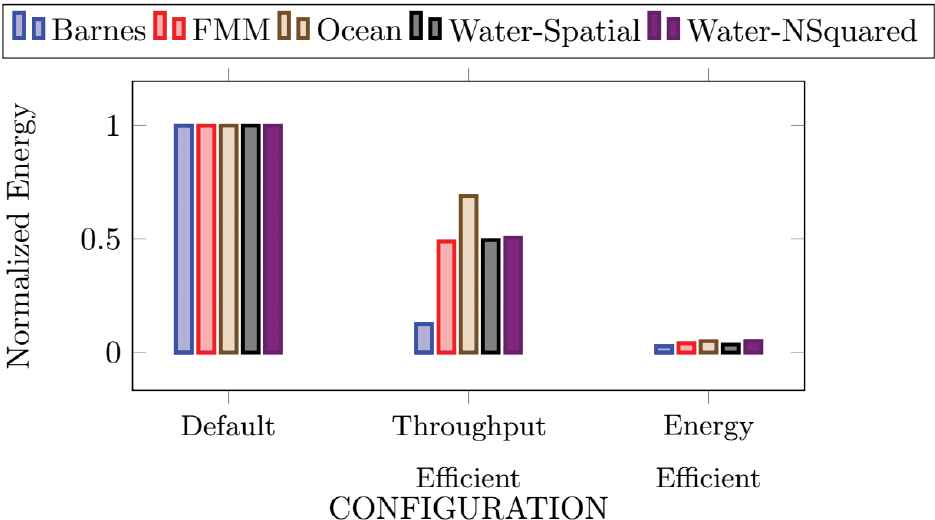
Results for normalized energy.
Figure 6 shows the normalized Energy Delay Product (EDP) of the three configurations. The figure shows that the EDP of throughput efficient configuration is 53% of the default value and of energy efficient configurations 55% of the default value on average (see Figure 6). The minimum EDP is observed for Barnes application for throughput efficient configuration i.e. 13% of the default value. For this configuration, FMM, Water Spatial and Water-NSquared show about 50% reduction in EDP. For energy efficient configuration, Barnes achieves 19% EDP and FMM, Ocean, Water Spatial and Water-NSquared achieve about 65% of the default EDP. Overall EDP is reduced significantly in all applications except Ocean application which improved least with 98% and 87% of the default EDPs for throughput efficient and energy efficient configurations respectively.
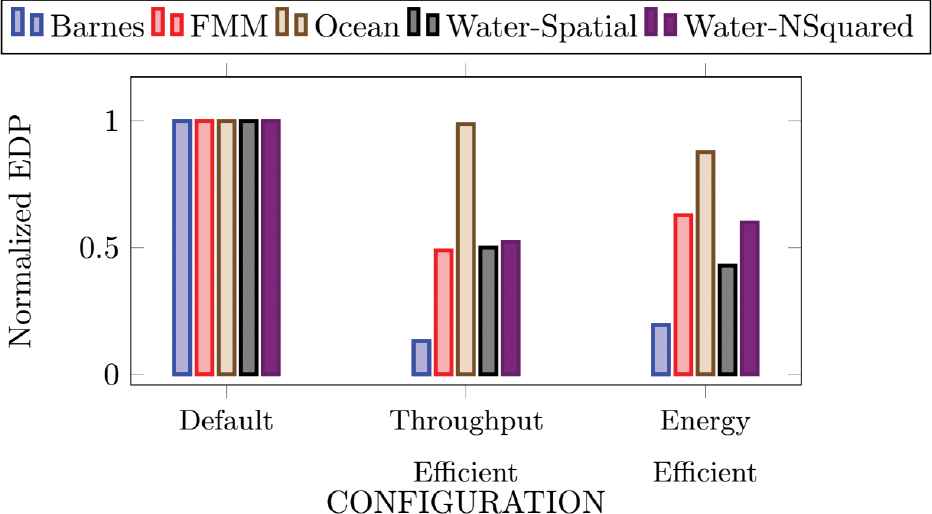
Results for energy delay product.
Since lower EDP is desired one, thus the results show a significant overall improvement in performance of these configurations suggested by the proposed ICSO algorithm.
7. CONCLUSION
In this paper, ICSO-based multiobjective DSE methodology was presented for multicore reconfigurable architectures. The objective of proposed methodology was to find an optimal trade-off between energy consumption and throughput. The pareto curve obtained by the proposed methodology was compared with the other state of the art exploration methodology which demonstrate the dominance of our proposed ICSO-based exploration method. The results were evaluated using extensive simulation which includes cycle accurate simulator MARSSx86, SPLASH-2 benchmark applications and CACTI for L1 cache energy consumption and timing data. The results demonstrate significant reduction in energy consumption without a major impact on the throughput. The proposed ICSO-based exploration technique is demonstrated for MPSoC reconfiguration but it is extendable for many core processors with more design space parameters.
CONFLICT OF INTEREST
The authors declare no conflict of interest.
AUTHORS' CONTRIBUTIONS
Shahid Ali Murtza Algorithm development, Writing Original Draft, Simulations, Results presentation; Ayaz Ahmad Algorithm development, Supervision in simulations, Results analysis; Muhammad Yasir Qadri Multicore modelling, target platform parametrization, final result evaluation, Final draft preparation, Project supervision (Project Co-PI), ICT R&D Funding; Nadia N. Qadri Data analysis, Development of Methodology; Majed Alhaisoni Project supervision, data analysis, Manuscript finalization, University of Ha’il Funding; Sajid Baloch Project supervision, team management and administration, validation and verification of results
ACKNOWLEDGMENTS
This work was part supported by the National ICT R&D Fund Pakistan, through grant number: ICTRDF/TR&D/2012/65 and by Deanship of Scientific Research at University of Ha'il, Ha'il, Kingdom of Saudi Arabia.
REFERENCES
Cite this article
TY - JOUR AU - Shahid Ali Murtza AU - Ayaz Ahmad AU - Muhammad Yasir Qadri AU - Nadia N. Qadri AU - Majed Alhaisoni AU - Sajid Baloch PY - 2020 DA - 2020/07/01 TI - An Integer Cat Swarm Optimization Approach for Energy and Throughput Efficient MPSoC Design JO - International Journal of Computational Intelligence Systems SP - 864 EP - 874 VL - 13 IS - 1 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.200617.001 DO - 10.2991/ijcis.d.200617.001 ID - Murtza2020 ER -