
Human Centric Recognition of 3D Ear Models
- DOI
- 10.1080/18756891.2016.1150002How to use a DOI?
- Keywords
- Ear photograph recognition; computational intelligence; bipolarity; aggregation
- Abstract
Comparing ear photographs is considered to be an important aspect of disaster victim identification and other forensic and security applications. An interesting approach concerns the construction of 3D ear models by fitting the parameters of a ‘standard’ ear shape, in order to transform it into an optimal approximation of a 3D ear image. A feature list is then extracted from each 3D ear model and used in the recognition process. In this paper, we study how the quality and usability of a recognition process can be improved by computational intelligence techniques. More specifically, we study and illustrate how bipolar data modelling and aggregation techniques can be used for improving the representation and handling of data imperfections. A novel bipolar measure for computing the similarity between corresponding feature lists is proposed. This measure is based on the Minkowski distance, but explicitly deals with hesitation that is caused by bad image quality. Moreover, we investigate how forensic expert knowledge can be adequately reflected in the recognition process. For that reason, a hierarchically structured comparison technique for feature sets and other characteristics is proposed. Comparison results are expressed by bipolar satisfaction degrees and properly aggregated to an overall result. The benefits and added value of the novel technique are discussed and demonstrated by an illustrative example.
- Copyright
- © 2016. the authors. Co-published by Atlantis Press and Taylor & Francis
- Open Access
- This is an open access article under the CC BY-NC license (http://creativecommons.org/licences/by-nc/4.0/).
1. Introduction
Background. In case of disasters, it is of utmost importance that the deadly victims are identified as accurate and as fast as possible, preferably in a way which is humane for their relatives. For that reason the Disaster Victim Identification (DVI) unit of the Belgian Federal Police involved the Medical Imaging Research Centre of the Catholic University of Leuven and the Database, Document and Content Management research group of Ghent University in a project that aimed at supporting ante mortem and post mortem ear photograph comparison. This paper reports on some results of this project.
Relevancy. Although still not officially recognized as a legal way to identify persons, ear biometrics can be used as a reliable and interesting component of a more complex person identification process, which by law always needs to be done by a team of forensic experts. Indeed, there is currently no hard evidence that ear shapes are unique, but there is neither evidence that they are not. Studies comparing more than ten thousand ear photographs of different persons revealed that no two ear shapes are indistinguishable1,2. Other studies, including ear shapes of fraternal and identical twins, concluded that the external ear anatomy constitutes characteristic features that are quite unique for each individual3. More research is definitely needed to prove uniqueness, but this does not imply that ear shape comparison cannot be used in victim identification tasks. On the contrary, matching or mismatching ear shapes provide forensic experts with useful, extra information that supports their identification tasks. The motivation for using ear shape comparison is moreover strengthened by the following observations:
- •
Ears are relatively immune to variations caused by ageing as the ear shape remains unchanged between the ages of eight and seventy years4.
- •
Ears are often among the intact parts of found bodies.
- •
Collecting ante mortem (ear) photographs is considered to be a humane process for relatives.
- •
(Semi-)automated comparison of photographs is in general faster and cheaper than DNA analysis.
Problem description. Consider the situation where a set of ear photos of a victim has to be compared with a set of ear photos of a missing person. This is one of the tasks forensic experts might have to deal with when trying to identify a victim’s body. Ear pictures of a victim are taken in post mortem conditions and henceforth referred to as post mortem (PM) pictures, whereas pictures of a missing person are always taken ante mortem and therefore called ante mortem (AM) pictures. PM pictures are assumed to be of good quality, because they are usually taken by forensic experts under controlled conditions: high resolution, correct angle, uniform lighting, with the ear exposed as best as possible. AM photos are often of lower, unprofessional quality. They are not taken with the purpose of ear identification and are usually provided by relatives or social media. Because there is no control over the conditions in which these pictures were taken, we can only hope retrieving the best we can. Moreover, parts of the ear might be obscured by hair, headgear or other objects, or can be deformed by glasses, earrings or piercings. This is illustrated in Fig. 1.
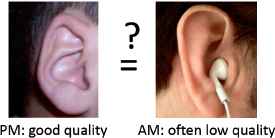
Data quality issues in PM and AM photographs.
Efficiently coping, in a (semi-)automated way, with the different aspects of the comparison of imperfect ear photographs, as taken into account by forensic experts, is a research challenge.
Contribution. Research in medical image processing revealed that working with 3D ear models helps to overcome problems caused by differences in orientation, scaling and resolution of 2D ear pictures. In this paper, we investigate if and how computational intelligence techniques can be used and combined for comparing 3D ear models. More specifically we investigate ear recognition techniques which allow to explicitly reflect forensic expert knowledge on ear identification, and moreover provide semantically richer information on the quality of retrieved results.
The presented work is the further development and integration of two techniques that we separately introduced5,6. The first technique handles the bipolarity that will arise when distinguishing feature points that are of sufficient (positive pool) or of insufficient quality (negative pool). All the results of comparisons of feature points are expressed using bipolar satisfaction degrees (BSDs)7. A BSD quantifies how well two feature points match (or do not match), and additionally assesses the hesitation about that comparison result, which is, e.g., caused by a lower quality of the AM photographs. The second technique is used to split off and compare subsets of feature points that correspond to specific areas of the ear shape. Results of elementary comparisons results are then combined using a hierarchic logic scoring of preferences (LSP)8 aggregation structure. This provides us with facilities to adequately model and incorporate (forensic) expert knowledge on ear comparison issues. LSP based comparison as presented in5 does not cope with bipolarity at all. Combining both techniques requires that the bipolarity in the data is properly reflected in the aggregation. Handling this is the main novel contribution of this paper.
Structure of the paper. The remainder of the paper is organized as follows. Related work is briefly described and discussed in Section 2. In Section 3, some preliminaries are given. First, some general issues on ear comparison are explained. Second, some basic concepts and definitions of bipolar satisfaction degrees are given. In Section 4, the 3D ear model that is used in our research is introduced. Section 5 deals with ear recognition and comprises the main contribution of the paper. It describes how corresponding (groups of) feature points from two ear models can be compared, using a novel bipolar similarity measure. Furthermore, it describes how this bipolar similarity measure can be used for comparing two 3D ear models. Finally, it explains the interpretation of comparison results in a bipolar setting. The benefits and added value of the novel ear recognition approach are discussed and demonstrated by an illustrative example in Section 6. Finally, some conclusions and plans for further research are reported in Section 7.
2. Related Work
Aspects of ear photograph comparison have been studied in several works9,10,11,12. An important aspect of an ear comparison process is ear recognition. During ear recognition corresponding features, which are extracted from two ear models, are compared in order to decide whether the associated ears match or not. Most related work on ear recognition is based on machine learning techniques. The considered feature extraction methodology can be used to categorize it.
Intensity based recognition methods use techniques like principal component analysis, independent component analysis and linear discriminant analysis for the comparison13,14,15. Other categories of recognition methods are based on force field transformations16, 2D ear curves geometry17, Fourier descriptors18, wavelet transformation19, Gabor filters20 or scale-invariant feature transformation21.
A last category of recognition techniques is based on 3D shape features. Most approaches use an iterative closest point algorithm for ear recognition22,23,24,25,26,27. In28 both point-to-point and point-to-surface matching schemes are used, whereas the method in29 is based on the extraction and comparison of a compact biometric signature.
An elaborate survey on ear recognition is contained in30. Another work covering the main aspects of automatic recognition of human ears is31.
Only a few recognition approaches11,12 consider to select specific areas on ear models and compare them in a pairwise fashion. Comparison results are then aggregated to obtain an overall matching score. Weighted aggregation allows assigning a different importance to specific ear parts, which in its turn can be interesting when some parts can be less trusted than others (due to, e.g., data quality issues). Explicitly considering separate ear parts in recognition also supports the reflection of forensic expert knowledge. For example, it is generally known that ears are relatively immune to variation due to ageing4. This holds true for the full ear shape, with the exception of the ear lobule which is known to elongate for elderly people. So, when the PM photograph is of a person who is more than seventy years old and the AM photograph is of a person who is much younger, a mismatch of the ear lobule shape should not have a significant impact on the overall ear comparison result. Likewise, some variations of the ear shape are known to be extremely rare. A match for such parts should give a significantly higher indication that the full ear shapes should match too.
To the best of our knowledge, none of the existing ear recognition techniques adequately assess and handle data quality issues. However, assessing data quality and reflecting its impact on the results of ear comparisons is important. Indeed, extra information expressing the quality of the data on which the comparisons are based enriches the comparison results. Forensic experts can use this extra information to improve their decision making. For example, the case where an AM photograph A and a PM photograph P only partially match, while both having sufficient quality, clearly differs from the case where A and P partially match to the same extent, but where A is of (much) lower quality.
3. Preliminaries
3.1. General Issues on Ear Comparison
Deploying ear biometrics for victim identification can be seen as a pattern recognition process. In this process, ear photographs of a victim and ear photographs of a missing person are respectively reduced to a PM and an AM feature set, which are then consecutively compared with each other. By doing so for all registered, missing persons the process aims to help identify the victim on the basis of the best match. The following main steps are hereby distinguished31:
- 1.
Ear detection. The ear shape is located and the ear is extracted from the photographs.
- 2.
Ear normalisation and enhancement. Detected ears from different photographs of the same person are transformed to a consistent ear model using, e.g., geometric and photometric corrections.
- 3.
Feature extraction. Representative features are extracted from the ear model.
- 4.
Ear recognition. Feature sets of AM and PM ear models are compared. A matching score indicating the similarity between both models is computed.
- 5.
Decision. The matching scores are ranked and used to render an answer that supports forensic experts in their decision making.
Errors in the first three steps can undermine the utility of the process. So, features that are obtained from low quality data should be handled with care, and forensic expert knowledge on data quality aspects in ear comparison should be reflected as adequately as possible. It is considered that forensic experts provide us with heterogeneous bipolar information regarding the quality of (features located in) different parts of the AM and PM ear models. This means that some features are obtained from reliable data and usefully contribute to the recognition process. Other features definitely stem from unreliable data and should be avoided, while for other features still there can be hesitation about their quality. The latter should be handled with special care. In order to do that, we consider that a feature set can be subdivided into subsets to which different importances can be assigned in view of the recognition process. Corresponding feature subsets of PM and AM ear models are then evaluated separately, after which their resulting matching scores are aggregated in accordance to the predetermined preferences of forensic experts.
3.2. Bipolar Satisfaction Degrees
Bipolar satisfaction degrees (BSDs)7 are used for handling the heterogeneous bipolar information on the data quality in a proper way. Only the features for which the quality is considered to be ‘good enough’ should contribute to the comparison process. However, features for which there is hesitation about their quality should not be discarded, but used for assessing the hesitation on the outcome of the comparison. A BSD allows modelling to which extent a (comparison) criterion is satisfied (or not), but differs from a regular satisfaction degree in that it additionally provides information on the hesitation about the satisfaction of the criterion. A BSD is a couple
Three cases are distinguished:
- 1.
If s + d = 1, then the BSD is fully specified. This situation corresponds to traditional involutive reasoning.
- 2.
If s + d < 1, then the BSD is underspecified. In this case, the difference h = 1 − s − d reflects the hesitation about the accomplishment of the comparison. This situation corresponds to membership and non-membership degrees in Atanassov intuitionistic fuzzy sets32.
- 3.
If s + d > 1, then the BSD is overspecified. In this case, the difference c = s + d − 1 reflects the conflict in the comparison results.
Consider that i denotes a t-norm (e.g., min) and u denotes its associated t-conorm (e.g., max). The basic logical operations for conjunction, disjunction and negation of BSDs (s1, d1) and (s2, d2) are respectively defined by7:
4. 3D Ear Model
In previous work, we tried to accomplish ear recognition by using 2D ear images33. However, imperfect geometric and photometric transformations of 2D AM photos put a limit on the quality of comparison results. To improve upon our previous work we currently work with a 3D ear shape model that captures the three dimensional details of the ear surface, as shown in the left and middle parts of Fig. 2.
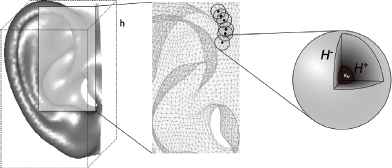
An illustration of our 3D ear model (with hesitation spheres).
4.1. Construction
A 3D ear model is obtained by estimating the parameters of a mathematical shape function. The values for these parameters should be chosen in such a way that the resulting shape optimally fits the available images of the ear. More details on this fitting technique can be found in34. Other, related work includes35,36,37. Fitting of 3D ear shapes can be done within a 3D box frame with fixed height h, as shown in the figure. This allows to normalize a set of 3D ear models to a set of models that all have the same height and resolution.
For the part of our research that is presented in this paper we assume that for each victim, we have a 3D PM ear model at our disposal. This model is obtained from fitting a 3D camera image of the victim’s right ear. We also assume there is a 3D AM model of the right ear of each missing person. The AM ear models, used for the reported research, are also obtained from 3D camera images. Ongoing research in medical image processing aims to develop advanced techniques for constructing a 3D AM ear model by fitting fragments, which are extracted from a set of 2D photos of the same missing person.
4.2. Assessing Data Quality
Denote that a 3D ear model is an artificial representation of a real ear shape, which is constructed based on the available information. If data about the shape of some parts of the ear are missing or of lower quality, this will result in a quality decrease of (some parts of) the fitted 3D ear model. Unavailability of data while constructing a PM ear model might be due to ear damage incurred during the disaster. In a realistic setting, unreliability of data in AM ear modelling can be caused by obstructed ear parts, strange ear shape deformations, lower 2D photograph quality, etc. In this study, we rely on forensic experts to manually point out (if applicable) which parts of the 3D ear model are less reliable than others.
Properly assessing and handling data quality in an ear recognition process is important because it offers forensic decision makers extra information about the reliability of the recognition results. We propose to use computational intelligence techniques to accomplish this. Unreliable parts of 3D ear models will be denoted by socalled hesitation spheres. As illustrated in the right part of Fig. 2, a hesitation sphere H is defined by two concentric spheres H+, H− and a maximal hesitation value νH ∈ ]0,1].
All points p that are located inside or on the surface of the inner sphere H+ are considered to have fixed associated hesitation value hH(p), which equals to νH. By default, νH can be set to 1, representing full hesitation. For points on the surface or outside the outer sphere H− the hesitation level is considered to be 0, whereas for points between both spheres the hesitation is gradually decreasing from νH to 0, depending on their distance to H+, i.e.,
4.3. Feature Extraction
When working with a 3D ear model, feature extraction boils down to selecting n representative points of the model’s surface. The more points that are considered, the more computation time will be needed during ear recognition. Considering more points increases matching quality at the cost of computation time. Choosing too little points will result in worse recognition results.
The shape fitting approach, introduced above, allows for a rather simple feature extraction method. It is sufficient to choose a 3D ear model of a ‘standard’ ear and choose n representative points on its surface. As such, a standard feature set
For constructing a 3D ear model F of a given 3D ear image, the fitting algorithm is initialised with the parameter values of the ‘standard’ 3D ear model S. The fitting algorithm34 will transform each point on the surface of the ‘standard’ model S to a point on the surface of the fitted ear model F. Hence, each feature
If an AM ear model A and a PM ear model P are constructed, the feature set
5. Ear Recognition
In ear recognition, the feature sets of two right (or two left) ear models are compared. If used for victim identification, the feature set FP of the PM ear model P of the victim’s right (or left) ear has to be compared with the feature set FA of the AM ear model A of a missing person’s right (or left) ear.
In this section we propose a novel method for improving the quality of an ear recognition process. In Subsection 5.1, a basic technique for comparing corresponding features of AM and PM feature sets is described. This technique is improved in Subsection 5.2 to explicitly cope with the hesitation that might exist about the data quality. In Subsection 5.3, we study how two 3D ear models and their metadata can be compared. Special attention goes to the adequate modelling of forensic expert knowledge. The interpretation of the results and the added value of our novel approach are discussed in Subsection 5.4.
5.1. Similarity of Corresponding Features
A commonly used technique for comparing corresponding points of two feature sets is to use the Minkowski distance. In the 3D Euclidean space ℝ3 defined by the three orthogonal axes X1, X2 and X3, the Minkowski distance between a point pA of FA and its corresponding point pP in FP is given by:
The similarity between two points is then obtained by applying a similarity function μSim to their distance. This function can generally be defined as the membership function of a fuzzy set38 Sim over the domain [0, +∞[ of preferred distances. A practical function is the following:
Hence, the obtained similarity measure fSim for the comparison of two features pA and pP is:
5.2. Bipolar Similarity
The computation of the similarity between two corresponding features pA and pP as defined by Eq. (9) does not cope with data quality issues. In order to do so, we propose to explicitly take into account the hesitation values h(pA) and h(pP) of both features, obtained by Eq. (6). For that purpose, a novel, socalled bipolar similarity measure fBSim is proposed:
The similarity measure fBSim returns a BSD (s,d), which expresses the result of the comparison of pA and pP as described in Subsection 3.2, i.e., s (resp. d) denotes to which extent pA and pP are similar (resp. not similar), and is defined by:
5.3. Comparing 3D Ear Models
Eq. (10) yields a BSD (s, d), expressing the degree of satisfaction s and the degree of dissatisfaction d about the matching of two corresponding features pA and pP. As extra information, the degree of hesitation h = 1 − s − d about the matching can be derived. In order to come to a comparison of two 3D ear models A and P, their feature sets
The comparison of two feature sets FA and FP is done piecewise. Different subsets of the feature sets can be compared separately, after which the resulting BSDs are aggregated using a hierarchical aggregation structure. The BSDs resulting from the evaluation of criteria on the metadata can also be incorporated in the aggregation structure. Moreover, BSDs can be assigned different weights reflecting the relative importance of their associated criteria in the ear recognition process. This approach allows us to reflect and handle forensic knowledge on how to compare ears, in the matching process.
5.3.1. Comparing Corresponding Subsets of Features
The separate treatment of different subsets of feature sets FA and FP in the comparison process is motivated by the fact that forensic experts have considerable knowledge about the typicality of specific shapes of different parts of the outer ear. Fig. 3 contains an overview of the most important distinguished ear parts. Also, knowledge about which parts are sensitive to deformations due to ageing, earrings, objects or other phenomenons might be relevant for fine-tuning the ear recognition process.
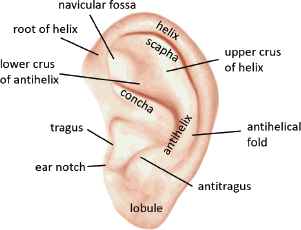
Different parts of an outer ear.
Hence, there is a need for a facility to group all features that belong to an identified part of the ear in a subset and compare corresponding subsets stemming from two 3D ear models. Such comparisons can then later be combined with other comparisons and criteria on the metadata. Feature point selection will in general be guided by the need to distinguish among specific parts of the ear.
Consider a subset
5.3.2. Aggregation Trees for Ear Recognition
At the basis of the comparison of an AM ear model A and a PM ear model P are the comparison(s) of (subsets of) their respective feature sets FA and FP — as described above — and the evaluation of meta-data criteria. Metadata criteria can, among others, be used for checking the age, gender or race of two persons, or for checking the presence of characteristics like birthmarks, tattoos and perforations by earrings or piercings.
The result of a metadata criterion evaluation can also be expressed by means of a BSD. Indeed, verifying whether the metadata for A and P match (or not) can yield in a full satisfaction s = 1 (or full dissatisfaction d = 1), which corresponds to the BSD (1, 0) (or (0, 1)). It can also result in a partial (dis)satisfaction caused by some hesitation 0 < h ⩽ 1 which can, e.g., be reflected by the BSD ((1 − h)/2, (1 − h)/2) (cf. Eq. (10)). For example, if A and P are both ear models of a person belonging to the Caucasian race, the comparison criterion for race will yield (1, 0), denoting full satisfaction. However, if there is a hesitation h about the race of P it will result in a partial satisfaction. More details on the specification and evaluation of metadata criteria are not given in this paper.
The next step in the 3D ear model comparison, is the aggregation of the BSDs that are obtained from subset comparisons and metadata criteria evaluations. Aggregation should result in an overall BSD that adequately reflects the similarity between the AM and PM ear models and the hesitation that might exist about this similarity. In order to obtain this, a hierarchic aggregation structure is proposed. An aggregation tree8 allows to adequately reflect human decision making and hence can also be configured to model ear comparison strategies that are used by forensic experts8.
Aggregation tree structures are constructed as follows. Each leaf node either corresponds to a subset comparison or to a metadata criterion. The evaluation of a leaf node results in a BSD. Each internal node corresponds to an aggregator. Such an aggregator groups (the results of) related subset comparisons and/or metadata criteria. It also supports the modelling of higher abstraction levels that might exist in the decision making. For example, one aggregator can group criteria that check the presence of piercings and earrings. Another aggregator can group criteria that relate to the central parts of the ear (ear notch, tragus, antitragus and antihelix). And yet another aggregator can be used to reflect that similarity of the ear lobules should rather be considered as a bonus (not a requirement) in those cases where the estimated age of the victim is older than seventy and the difference in time of the AM ear photo shoots is significant. We will further develop some of these examples in Section 6.
The evaluation of an internal node involves the aggregation of the BSDs that result from the evaluations of its child nodes and results in a new BSD. This BSD reflects the overall satisfaction and hesitation, considering all subset comparisons and meta-data criteria, which are specified in the subtree that has the internal node as root. Ear model comparison then boils down to (recursively) evaluating the root node of the aggregation tree.
An example of an aggregation tree is depicted in Fig. 4. The solid rectangles at the left side of the figure represent the subset comparisons and metadata criteria. Each comparison and criterion is evaluated, which yields a BSD. These BSDs are the leaf nodes of the tree and form the inputs for the evaluation of the other nodes. Each internal node represents an aggregator and is characterized by a parameter α, which will be introduced next. The inputs of an aggregator have a weight w, as explained below.
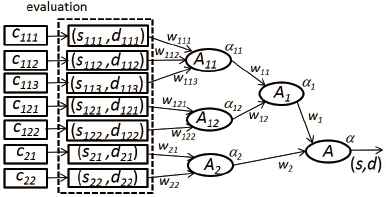
Example of an aggregation tree.
The aggregators of the aggregation tree are all defined based on the generalized conjunction/disjunction (GCD) function8,5, which is adapted here to cope with BSDs. Both basic aggregators and partial absorption aggregators are considered.
Basic Aggregators. For each basic aggregator
A weight wi ∈ [0, 1] is assigned with each input (si, di), 1 ⩽ i ⩽ n of the aggregator. The weights have to sum up to one, i.e., if we have an aggregator with n BSDs as input,
The andness parameter α ∈ [0, 1] determines the logical behaviour of the aggregator. It acts as an index expressing how ‘close’ the logical behaviour of the aggregator
The semantics of the aggregators that are defined by Eq. (17) are completely in line with the semantics of the logical operators that were introduced in Eq. (2)–(4). For α < 0.5 we have disjunction. When α = 0 the disjunction is called full disjunction (D). For 0 < α < 0.25 a hard partial disjunction (HPD) operator is obtained, whereas 0.25 < α < 0.5 yields a soft partial disjunction (SPD) operator. Hence, α = 0.25 can be considered as corresponding to a neutral partial disjunction (PD) operator. Likewise, for α > 0.5 we have conjunction and α = 1 is called full conjunction (C). For 0.75 < α < 1, a hard partial conjunction (HPC) operator is obtained, whereas 0.5 < α < 0.75 yields a soft partial conjunction (SPC) operator. The andness α = 0.75 can be considered as corresponding with a neutral partial conjunction (PC) operator. If α = ω = 0.5, the neutral (weighted) arithmetic mean operator (A) is obtained. In this case
Partial Absorption Aggregators. A partial absorption aggregator
5.4. Interpreting the Results
The evaluation of the aggregation tree yields a single BSD (s, d) ∈ [0, 1]2. This BSD expresses how well two 3D ear models A and P match (s) and do not match (d) with respect to the forensic expert knowledge that is modelled by the criteria and aggregators of the tree. Moreover, h = 1 − s − d provides an assessment of the overall hesitation that exists about the comparison result (due to imperfect data quality).
In a typical victim identification search, a PM 3D ear model is compared with a set of m AM 3D ear models taken from a database containing information about missing persons. Each of these comparisons results in a BSD (si, di), i = 1, . . . , m. In practice, forensic experts will be interested in the top-k matches for a given PM 3D ear model. For that purpose, the resulting BSDs (si, di), i = 1, . . . , m, have to be ranked. In the given context, the best ear matches are those where si is as high as possible and hi is as low as possible. Therefore, considering that hi = 1 − si − di, the ranking function
Compared to existing comparison methods, the presented approach has two main advantages, which together reflect the novelty of this work and contribute in making ear comparison more human centric. First, BSDs allow to assess data quality and hence provide the decision makers with extra information that is not available with regular approaches. Second, the advanced aggregation technique allows to better reflect existing expert knowledge in the decision making process.
However, configuring the similarity measure and aggregation structure can be time consuming and requires some specific user skills. More research on how to make the approach more user-friendly is needed and subject to future work.
6. Illustrative example
The benefits and enriched expressibility of our proposed approach are discussed and demonstrated by the following illustrative example. Consider the simplified comparison scenario, presented in Fig. 5. An AM ear model A is compared with a PM ear model P. There are two metadata attributes ‘gender’ and ‘race’, whose values, if available, should match. The other six attributes denote subsets of feature points. Attributes ‘antihelix’, ‘tragus’, ‘ear notch’, ‘antitragus’ and ‘lobule’ correspond to specific parts of the ear as depicted in Fig. 3, whereas attribute ‘other parts’ denotes the subset of all other feature points (not included in the subsets of the five previous attributes). The attribute values for A and P are resp. presented in the first and second column next to the attribute name.
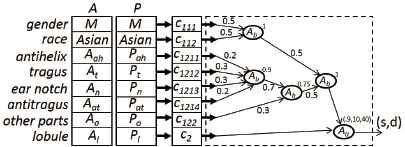
Illustrative example.
For each attribute there is a corresponding elementary criterion. Criteria c111 and c112 respectively check whether the gender and race of A and P possibly match or not, whereas the other criteria c1211, c1212, c1213, c1214, c122 and c2 compare corresponding subsets of feature points by applying Eq. (13). Each elementary criterion is evaluated with its corresponding attribute values for A and P. The resulting BSDs enter the aggregation structure (dotted box) via their corresponding arrows. (For the sake of clarity, the BSDs are not represented in the figure.)
The aggregation structure reflects (part of) the forensic expert knowledge. The following knowledge rules are reflected:
- •
Both criteria on the metadata (c111 and c112) are mandatory and should be fully satisfied in order to conclude a match. This is modelled by a pure conjunctive basic aggregator (α = 1). Weights do not have any impact on this aggregation and are by default set to 0.5.
- •
Parts of the inner ear are considered to be more important for the matching process. The inner ear parts under consideration are the tragus, ear notch, antitragus and antihelix where the tragus and ear notch are slightly more important than the other two. This is modelled by two basic aggregators. The first aggregator aggregates all results stemming from the comparison of inner ear parts. The results that stem from the tragus (c1212) and ear notch (c1213) comparisons are assigned a slightly higher weight (0.3) than those stemming from the antitragus (c1214) and antihelix (c1211) comparisons (0.2). A hard partial conjunction (α = 0.9) with an andness of 90% is considered. This reflects that all criteria should be satisfied to some extent, but some relaxation of 10% satisfaction is allowed to conclude a match. The second aggregator combines the inner ear comparison result with the result of comparing the other feature points (c122), excluding those that belong to the lobule. Respective weights of 0.7 and 0.3 reflect the importance of the inner ear over the other parts. A neutral partial conjunction (α = 0.75) is considered to allow for some relaxation in the matching results.
- •
The shape of the lobule of elder persons can elongate over time. A solution for coping with this rule is to consider ear lobule matching optional. If the ear lobules (partially) match, a corresponding reward is assigned to the matching score, otherwise a penalty is assigned. This is modelled by a conjunctive partial absorption aggregator (α = 0.9) with mean penalty P = 10% and mean reward R = 40%. Because the partial absorption aggregator is a binary operator, the results of the meta-data comparison and other feature point comparisons first have to be aggregated to obtain a single mandatory input. A pure conjunctive basic aggregator (α = 1) is used. The result of the lobule comparison (c2) is the optional input.
The above example illustrates the added-value of our proposal. With traditional aggregation techniques the given knowledge rules would be much more difficult to model. Moreover, the aggregation structure takes BSDs as input and generates an over-all BSD (s, d), which also reflects the overall hesitation about the data quality. Such extra information helps the forensic experts to correctly interpret the worth of the comparison results, revealing hints in cases where no adequate matches are found. A more complex aggregation structure is needed for comparing real cases, where more knowledge rules are involved in the comparison process.
A main advantage of the proposed framework is that it offers novel facilities for tackling the challenging problem of comparing a 3D PM ear model obtained from a good 3D image with a 3D AM model obtained from lower quality 2D AM photographs. To the best of our knowledge, this problem has not been studied yet. More research is definitely needed here, but it is already clear that potential solutions would benefit from data quality assessment and configurable representations of forensic expert knowledge.
Current approaches for 3D ear image recognition, as described in Section 2, already yield good comparison results when applied to high quality images. If applied to high quality 3D images (full visibility, no deformations, no difference in age), the recognition approach described above is accurate enough to generate comparable results. Small differences, caused by imperfections in the fitting process, are compensated by the flexibility of the proposed similarity measure (parameters ε1 and ε0 in Eq. (9)).
However, adequately dealing with low quality AM photos requires more flexibility for guiding the comparison process in accordance to preferences that are set by forensic experts. Indeed, in these cases, the fitting process will yield larger differences so that untrusted parts should be excluded from the comparison process. (Else, the required compensations would be so large, that a large number of false positives will be inevitable.) The techniques presented in this paper are meant to contribute in offering such a flexibility.
Also, experiments with representative, real-life data sets are required for fine-tuning all the parameters that occur and for validating the approach. Constructing such data sets is time consuming and subject to ongoing work. For example, a representative number of 3D AM ear models containing unreliable parts, representing information from old photos, etc. should be included, as well as ear models of relatives like parents, siblings, twins, etc. In a later stage, 3D ear models obtained from 2D AM photos should also be included.
7. Conclusions and Future Work
The purpose of this paper is proposing a theoretical framework for novel techniques, which make ear comparison more human centric. More specifically, the paper first presents a framework for assessing data quality and reflecting the hesitation caused by bad data quality in the comparison results. This provides decision makers with useful extra information. Another novelty in the paper is the integration of an advanced, configurable aggregation structure, supporting the incorporation of forensic expert knowledge in the comparison process. Configuring the relative weights of the inputs and the andness parameters of the basic aggregators and configuring the penalty, reward and andness parameters of the partial absorption aggregators in the aggregation structure supports decision makers in performing different comparisons for investigating multiple circumstances and scenarios.
The paper focuses on the semantic aspects of the ear comparison problem and demonstrates how computational intelligence techniques help to make ear comparison more human centric. In our future work we plan to focus on the fine-tuning of the similarity measure and the configuration of the aggregation structure. We also plan extensive tests with real-life cases once a database with enough data, obtained from 2D AM photographs, is available. As well the impact on execution time, as the impact on the recognition results of different parameter settings and configurations will be studied.
References
Cite this article
TY - JOUR AU - Guy De Tré AU - Robin De Mol AU - Dirk Vandermeulen AU - Peter Claes AU - Jeroen Hermans AU - Joachim Nielandt PY - 2016 DA - 2016/04/01 TI - Human Centric Recognition of 3D Ear Models JO - International Journal of Computational Intelligence Systems SP - 296 EP - 310 VL - 9 IS - 2 SN - 1875-6883 UR - https://doi.org/10.1080/18756891.2016.1150002 DO - 10.1080/18756891.2016.1150002 ID - DeTré2016 ER -