
Matrix-Based Approaches for Updating Approximations in Multigranulation Rough Set While Adding and Deleting Attributes
- DOI
- 10.2991/ijcis.d.190718.001How to use a DOI?
- Keywords
- Approximation computation; Multigranulation rough set; Knowledge acquisition; Decision-making
- Abstract
With advanced technology in medicine and biology, data sets containing information could be huge and complex that sometimes are difficult to handle. Dynamic computing is an efficient approach to solve some problems. Since multigranulation rough sets were proposed, many algorithms have been designed for updating approximations in multigranulation rough sets, but they are not efficient enough in terms of computational time. The purpose of this study is to further reduce the computational time of updating approximations in multigranulation rough sets. First, searching regions in data sets for updating approximations in multigranulation rough sets are shrunk. Second, matrix-based approaches for updating approximations in multigranulation rough set are proposed. The incremental algorithms for updating approximations in multigranulation rough sets are then designed. Finally, the efficiency and validity of the designed algorithms are verified by experiments.
- Copyright
- © 2019 The Authors. Published by Atlantis Press SARL.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
Since the rough set [1,2] was proposed by Pawlak in 1982, it has been widely used in various fields such as pattern recognition [3–10], machine learning [11,12], image processing [11,13–19], decision-making [20–22], data mining, and so on. A lot of extensions have been proposed to extend its application including covering based rough sets [23], variable precision rough sets [24], probabilistic rough sets [18], fuzzy rough sets [9,13,25,26], fuzzy variable precision rough sets [27], and so on.
Qian et al. proposed multigranulation rough sets (MGRSs) based on multiple equivalence relation in 2010, which include optimistic MGRSs and pessimistic MGRSs. In recent years, many models have been proposed based on two decision strategies: “Seeking common ground while reserving differences” and “Seeking common ground with eliminating differences.” For example, by popularizing the binary relation from equivalence relation to neighborhood relation, Lin et al. proposed neighborhood MGRSs. Lots of studies focus on deriving models by the same decision strategy. Huang et al. proposed intuitionistic fuzzy MGRSs [28]. Feng et al. proposed variable precision multigranulation decision-theoretic fuzzy rough sets [29]. Li et al. proposed three-way cognitive concept learning via multi-granularity [30]. There are research on MGRSs and their relative models, such as MGRSs theory over two universe [31], a comparative study of MGRSs and concept lattices via rule acquisition [32], and so on.
In an information explosion era, approximation computing becomes more and more difficult: the size of the data sometimes is too huge to handle, the structure of the data becomes more complex, and the granular structures often increase or decrease. The issue of computing and updating approximations in MGRSs and their derived models attracts much research interest. These studies are often categorized into four classes by scholars, namely, how to update approximations while varying attributes [33,34], how to update approximations while varying attribute values [35,36], how to update approximations while varying decision attribute values [33,37], and how to update approximations while varying object set [38,39].
No matter what variation is, there always exist two means to determine the relation between two sets: set operation or matrix product. By this viewpoint, we can classify those studies into two categories. One is based on set operation. Scholars use set operation to determine whether a set is contained in another set or not, or whether their intersection is empty or not (see Chuan Luo [20,21], Wenhao Shu [40], Guangming Lang [41], Mingjie Cai [42], Wei Wei [43], Xin Yang [44], etc.). When granules sizes are generally big, set operation is a time-consuming way because of its searching strategy: when we compute the intersection of two sets, we must confirm whether every object in a set is in another set or not. In the extreme case, when the two sets are both U (all samples are in one data set), then the time complexity of computing the intersection of them is
We attempt to combine the two approaches to derive new approaches to overcome their defect. In other words, we concentrate on which part of the universe does not need to be considered while computing and updating approximations in MGRS. At the same time, we determine the relation between two sets by matrix product. Why we try to propose the approaches? Because in real life application, it is common to add and delete attributes when there is some new information and some expired information. Different granular structures have a great influence on approximations in MGRS, thus different granular structures induce different decision-making processes. Moreover, adding and deleting attributes exists in the whole attribute reduction process. In decision-making and attribute reduction process, calculating approximations of decisions is an important and necessary step, so it is important to compute approximations based on approximations we have computed, that is, updating approximations. We need to proposed approaches for updating approximations because that updating approximations could be more efficient than compute the approximations again.
The purpose of this paper is to derive algorithms for updating approximations while adding and deleting attributes. First, searching region while updating approximations in MGRS need to be shrunk. A shrunk searching region can reduce the executing time of the algorithms. Second, matrix-based approaches for updating approximations need to be proposed to make algorithms more efficient.
The rest of this paper is organized as follows: Some basic concepts of rough set and MGRS are introduced in Section 2, and so is matrix-based static algorithm to calculate approximation in MGRS. In Section 3, dynamic approaches for updating approximations in MGRS while adding and deleting attributes are proposed. Several algorithms are proposed in Section 4. Experimental evaluations are conducted in Section 5 to verify the efficiency and validity of the algorithms that we designed. Finally, some conclusions and future work are given in Section 6.
2. PRELIMINARIES
In this section, we review some main concepts in MGRSs as well as static algorithm for computing approximations in MGRS.
2.1. Multigranulation Rough Sets
In the past few years, many extensions of MGRSs [49] have been proposed. Since MGRS are our basic model, we review the main results in this subsection.
Definition 1.
[1] Let
Definition 2.
[49] Let
Theorem 1.
[50] Let
Theorem 2.
[49] Let
Definition 3.
[49] Let
Theorem 3.
[50] Let
Theorem 4.
[49] Let
2.2. Matrix-Based Algorithm for Computing Approximations in MGRSs
Definition 4.
[51] Let
Lemma 5.
[52] Let
“T” denotes the transpose operation, and “.” is matrix product.
Example 1.
Let
| U | a1 | a2 | a3 | d |
|---|---|---|---|---|
| 1 | 1 | 2 | 3 | |
| 2 | 3 | 3 | 3 | |
| 1 | 1 | 2 | 2 | |
| 2 | 2 | 3 | 2 | |
| 1 | 2 | 1 | 2 | |
| 1 | 1 | 1 | 3 |
A decision information system.
Definition 5.
[53] Let
Lemma 6.
[53] Let
Example 2.
(Continuation of Example 1) Suppose
By Lemma 6,
By Definition 4,
By Definition 4,
Definition 6.
[53] Let
Lemma 7.
[53] Let
Example 3.
Continuation of Example 2. From Table 1, we have
By Definition 6,
By Lemma 7,
By Definition 4,
By Definition 4,
Algorithm 1 [53] is a matrix-based algorithm for computing approximations in MGRS. The total time complexity of the algorithm is
Algorithm 1: Matrix-based algorithm for computing approximations in MGRS
Require: (1) An information system
Ensure: Approximations in MGRS.
1:
2:
3: for
4: for
5: for
6: if
7: end if
8: if
9: end if
10: end for
11: end for
12: end for
13:
14:
15:
16:
17: for
18:
19:
20:
21:
22: end for
23: Return
3. MATRIX-BASED DYNAMIC APPROACHES FOR UPDATING APPROXIMATIONS IN MGRS WHILE ADDING AND DELETING ATTRIBUTES
3.1. Matrix-Based Dynamic Approaches for Updating Approximations While Adding Attributes
In this subsection, we present matrix-based dynamic approaches for updating approximations in MGRS, while adding attributes, let
Lemma 8.
[46] Let
Lemma 9.
[46] Let
Lemmas 8 and 9 indicate the relations of lower and upper approximations in MGRS between time
Theorem 10.
Let
If
If
If
If
Proof.
If
If
If
From the above, we have
If
If
If
From the above, we have
It is similar to i.
It is similar to ii.
Example 4.
(Continuation of Example 1) Suppose
From Definitions 2 and 3 we have
By Theorem 10, we have
Since
Thus we have
Definition 7.
Let
Definition 8.
Let
Example 5.
(Continuation of Example 4)
Theorem 11.
Let
Proof.
This theorem can be easily obtained by Theorem 10 and Definitions 7 and 8.
By Theorem 11 we can easily obtain a matrix-based approach for updating approximations in MGRS while adding attributes.
Corollary 12.
Let
Proof.
This corollary is the matrix representation of Theorem 10.
Example 6.
(Continuation of Example 5)
From Definition 4 we have that
3.2. Matrix-Based Dynamic Approaches for Updating Approximations While Deleting Attributes
In this section, we present matrix-based dynamic approaches for updating approximations in MGRS, while deleting attributes, let
Lemma 13.
[46] Let
Lemma 14.
[46] Let
Lemmas 13 and 14 indicate the relation of lower and upper approximations in MGRS between time
Theorem 15.
Let
If
If
If
Proof.
By Lemma 13 we have
By Lemma 13 we have
It is similar to i.
It is similar to ii.
Example 7.
(Continuation of Example 1) Suppose
From Definitions 2 and 3 we have
By Theorem 15, we have
Since
Thus we have
Definition 9.
Let
Definition 10.
Let
Example 8.
(Continuation of Example 7)
Theorem 16.
Let
Proof.
This theorem can be easily obtained by Theorem 15 and Definitions 9 and 10.
By Theorem 16 we can easily obtain matrix-based approaches for updating approximations in MGRS while adding attributes.
Corollary 17.
Let
Proof.
This corollary is the matrix representation of Theorem 15.
Example 9.
(Continuation of Example 8)
From Definition 4 we have that
Algorithm 2: Matrix-based algorithm for updating approximations in MGRS while adding attributes.
Require: (1)
Ensure:
1:
2:
3: for
4: for
5: if
6: end if
7: if
8: end if
9: end for
10: end for
11:
12:
13:
14:
15: for
16:
17:
18:
19:
20: end for
21:
22:
23:
24:
25:
26: Return
4. MATRIX-BASED DYNAMIC ALGORITHMS FOR UPDATING APPROXIMATIONS WHILE ADDING AND DELETING ATTRIBUTES
Based on Corollary 12, we propose matrix-based Algorithm 2 for updating approximations in MGRS while adding attributes. The total time complexity of Algorithm 2 is
Since the time complexity of Algorithm 1 is
Algorithm 3: Ensure total time complexity of updating approximations in MGRS while adding attributes is no more than O | X | | U |
Require: (1)
Ensure:
1: if
2: end if
3: if
4: end if
5: Return
Based on Corollary 17, we propose matrix-based Algorithm 4 for updating approximations in MGRS while deleting attributes. The total time complexity of Algorithm 4 is
Algorithm 4: Matrix-based algorithm for updating approximations in MGRS while decreasing attributes
Require: (1)
Ensure:
1:
2:
3: for
4: for
5: if
6: end if
7: if
8: end if
9: end for
10: end for
11:
12:
13:
14:
15: for
16:
17:
18:
19:
20: end for
21:
22:
23:
24:
25:
26: Return
Since the time complexity of Algorithm 1 is
5. EXPERIMENTAL EVALUATIONS
In this section, several experiments were conducted to evaluate the effectiveness and the efficiency of Algorithm 3 (DMB) and Algorithm 5 (DMB). Three algorithms were chosen to compare, namely, matrix-based static algorithm (MB) [53], relation matrix-based static algorithm (RMB) [46], and relation matrix-based dynamic algorithm (DRMB) [46]. Six data sets were chosen from UCI machine learning repository. The details of the data sets are listed in Table 2. We can see that the sizes of data sets range from 194 to 1000, the attribute numbers range from 5 to 59. All the experiments were carried out on a personal computer with 64-bit windows 10, Inter(R) Core(TM) i7 6700HQ CPU @2.60 GHz, and 16GB memory. The program language was Matlab r2015b.
Algorithm 5: Ensure total time complexity of updating approximations in MGRS while deleting attributes is no more than O | X | | U |
Require: (1)
Ensure:
1: if
2: end if
3: if
4: end if
5: Return
| No. | Data Sets | Samples | Attributes |
|---|---|---|---|
| 1 | Blood Transfusion | 748 | 5 |
| 2 | Dermatology | 366 | 20 |
| 3 | Extention of ZAlizadehsani | 303 | 59 |
| 4 | Facebookmetrics | 500 | 19 |
| 5 | Flags | 194 | 30 |
| 6 | German Credit Data | 1000 | 21 |
Details of data sets.
5.1. Comparison of Computational Time Using Data Sets with Different Size
The computational time were compared among the four algorithms in MGRSs while adding and deleting attributes when the size of data sets increases. First of all, we construct three granular structures. We randomly chose an attribute set
When the size of data sets increases, results of the four algorithms while adding and deleting attributes in MGRS are shown in Figures 1 and 2. We can see that DMB is the most efficient algorithm when the size of data set increases gradually. From Figure 1 we can see that DMB is effective and it reduces the computational time.
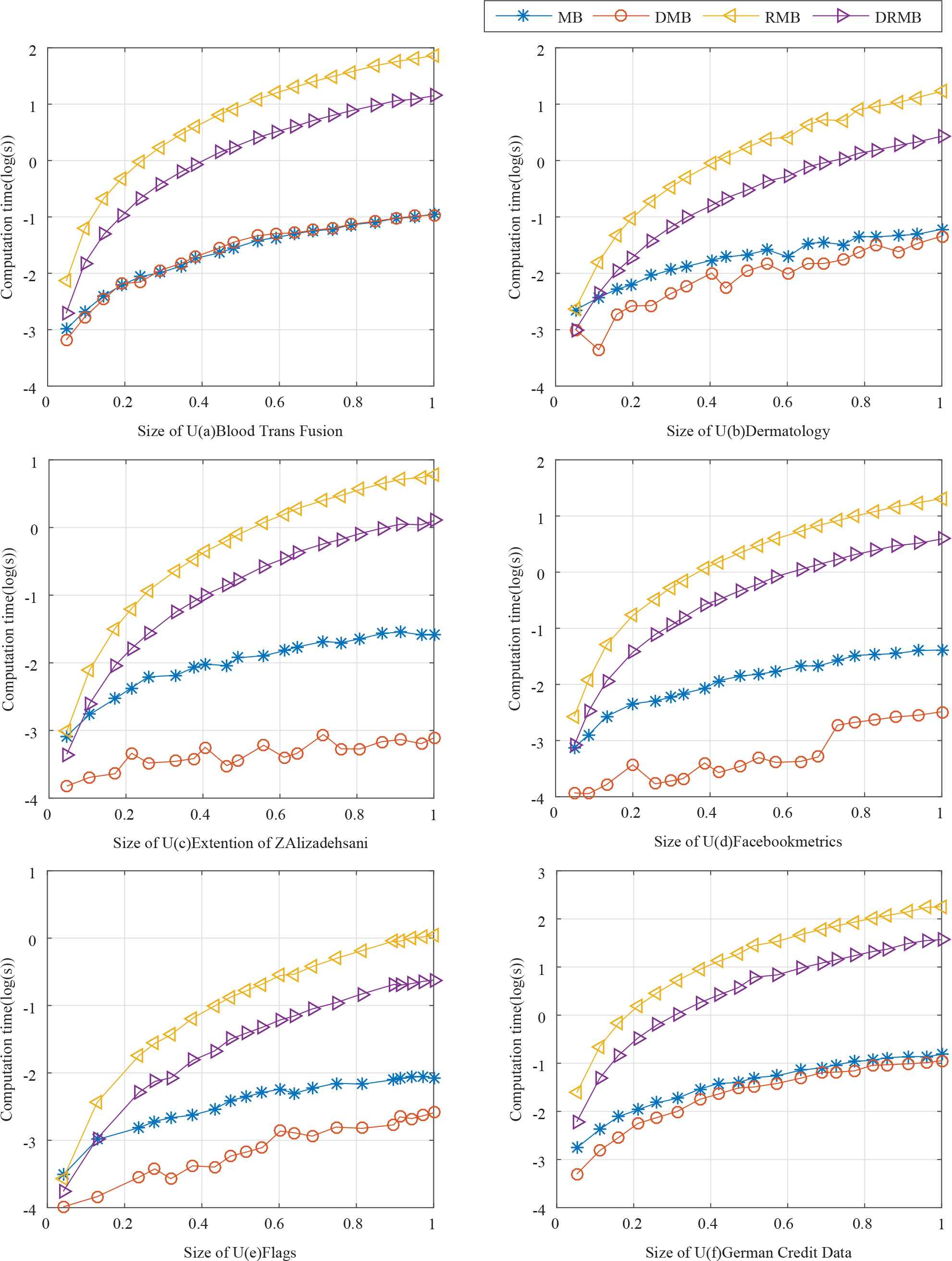
Computational time of Algorithm 3 when the size of U increasing gradually (adding attributes).
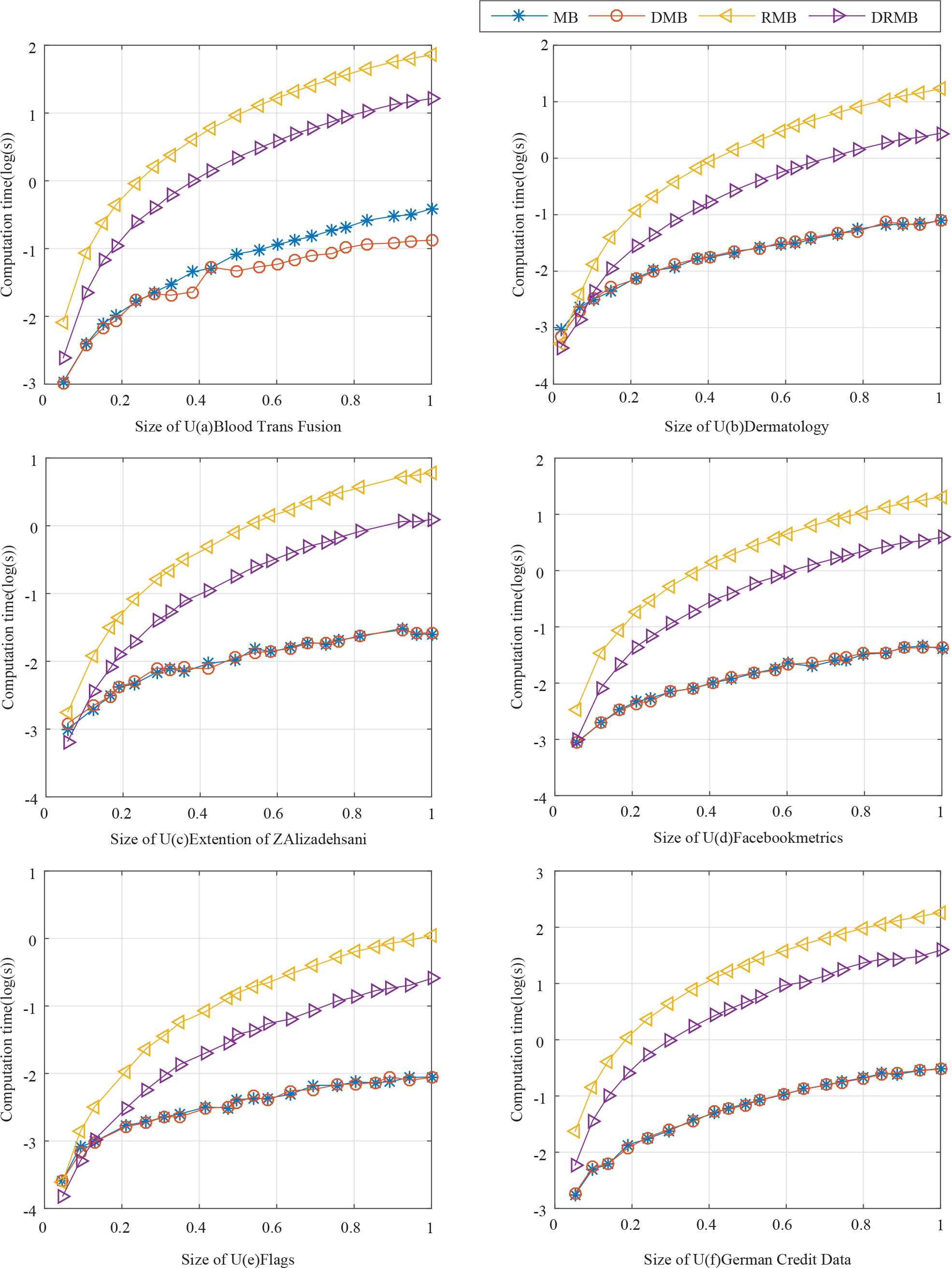
Computational time of Algorithm 5 when the size of U increasing gradually (deleting attributes).
5.2. Comparison of Computational Time Using Target Concept with Different Size
Similarly, instead of construct temporary data sets, we construct temporary target concepts. The process of constructing and varying the three granular structures is similar to Section 5.1. We randomly divided each data set into ten subsets
When the size of target concept increases, results of MB, DMB, RMB, DRMB are shown in Figures 3 and 4. When the size of target concept increasing gradually, RMB is always the most time-consuming algorithmn the four algorithms. DMB and MB are more efficient than RMB and DRMB. The computational time of DMB is always less than or equal to MB, so DMB is more efficient than any other algorithms. Sometimes the computational time of DMB is a little more than the MB while deleting attributes, which is due to additional computation in DMB and it is within the expected range.

Computational time of Algorithm 3 when the size of X increasing gradually (adding attributes).
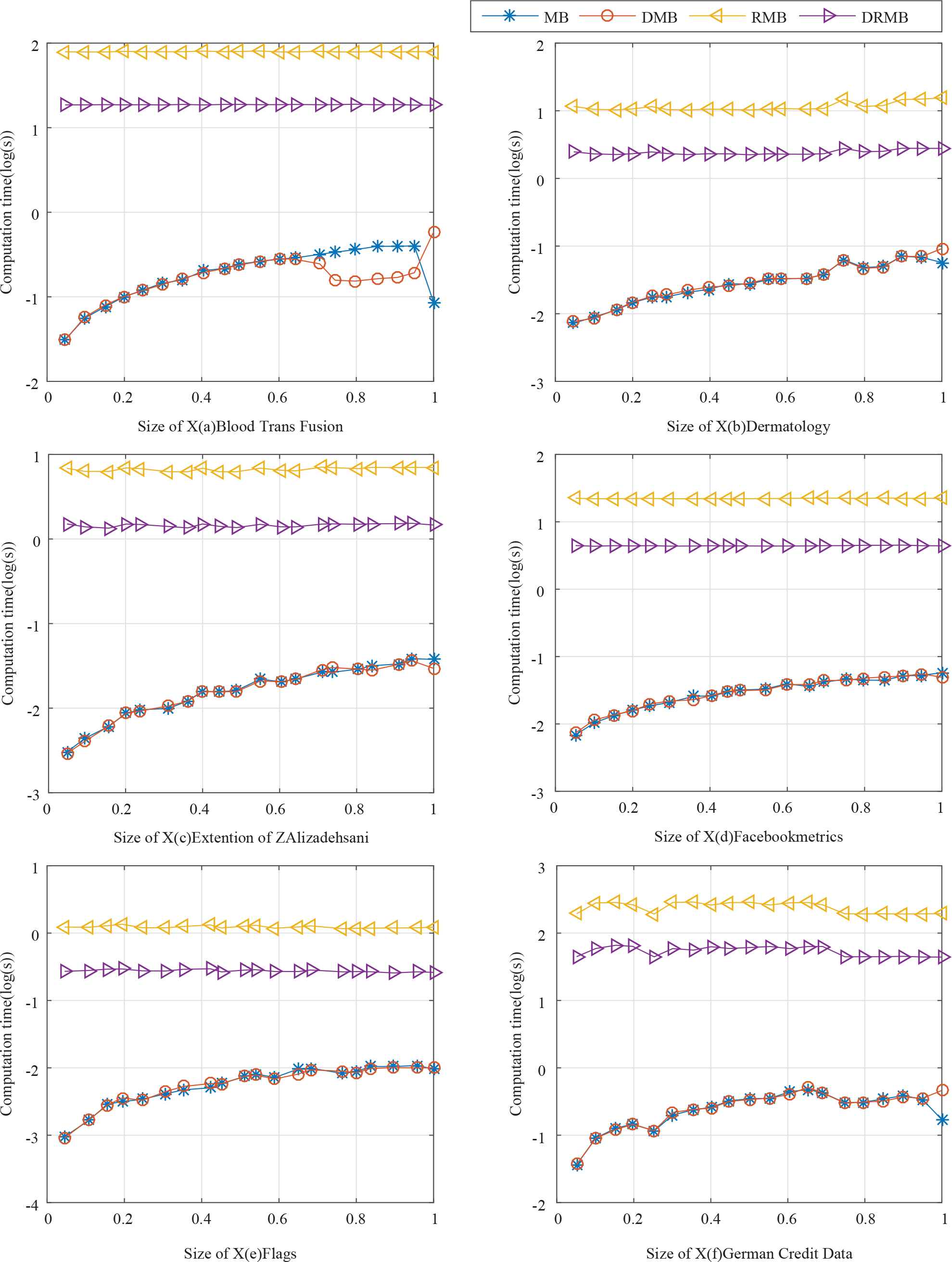
Computational time of Algorithm 5 when the size of X increasing gradually (deleting attributes).
6. CONCLUSION
Data sets in real life application sometimes are complex and huge, which is difficult to handle. In addition, the granular structures often increase and decrease in some data sets. It is important to design algorithms to update approximations in MGRS while adding and deleting attributes. In this paper, four algorithms have been proposed to ensure that the time complexity of the incremental algorithm is less than or equal to the static algorithm. Experimental results show that the computational time of the DMB is no more than the other algorithms in most of the situations.
Approximation computation is a basic process of attribute reduction. In the future, we will further investigate attribute reduction algorithm using the approaches we proposed.
CONFLICT OF INTEREST
There are no conflicts of interest.
AUTHORS' CONTRIBUTIONS
Jinjin Li and Peqiu Yu conceived and designed the study. Peiqiu Yu performed the experiments. Peiqiu Yu wrote the paper. Peiqiu Yu and Hongkun Wang reviewed and edited the manuscript. All authors read and approved the manuscript.
Funding Statement
This work is supported by National Natural Science Foundation of China (No.11871259), National Natural Science Foundation of China (No.61379021), National Youth Science Foundation of China (No.61603173), Fujian Natural Science Foundation of China (No.2019J01748).
ACKNOWLEDGEMENT
This work is supported by National Natural Science Foundation of China (No.11871259), National Natural Science Foundation of China (No.61379021), National Youth Science Foundation of China (No.61603173), Fujian Natural Science Foundation of China (No.2019J01748).
REFERENCES
Cite this article
TY - JOUR AU - Peiqiu Yu AU - Jinjin Li AU - Hongkun Wang AU - Guoping Lin PY - 2019 DA - 2019/07/05 TI - Matrix-Based Approaches for Updating Approximations in Multigranulation Rough Set While Adding and Deleting Attributes JO - International Journal of Computational Intelligence Systems SP - 855 EP - 872 VL - 12 IS - 2 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.190718.001 DO - 10.2991/ijcis.d.190718.001 ID - Yu2019 ER -