
Fine-Grained Sentiment Analysis for Measuring Customer Satisfaction Using an Extended Set of Fuzzy Linguistic Hedges
 , Nosheen Jillani2, Umair Younis2, Furqan Khan Saddozai2, , Ibrahim A. Hameed3, *,
, Nosheen Jillani2, Umair Younis2, Furqan Khan Saddozai2, , Ibrahim A. Hameed3, *, - DOI
- 10.2991/ijcis.d.200513.001How to use a DOI?
- Keywords
- Customer satisfaction; Fine-grained sentiment analysis; Fuzzy logic; Linguistic hedges; Membership function
- Abstract
In recent years, the boom in social media sites such as Facebook and Twitter has brought people together for the sharing of opinions, sentiments, emotions, and experiences about products, events, politics, and other topics. In particular, sentiment-based applications are growing in popularity among individuals and businesses for the making of purchase decisions. Fuzzy-based sentiment analysis aims at classifying customer sentiment at a fine-grained level. This study deals with the development of a fuzzy-based sentiment analysis by extending fuzzy hedges and rule-sets for a more efficient classification of customer sentiment and satisfaction. Prior studies have used a limited number of linguistic hedges and polarity classes in their rule-sets, resulting in the degraded efficiency of their fuzzy-based sentiment analysis systems. The proposed analysis of the current study classifies customer reviews using fuzzy linguistic hedges and an extended rule-set with seven sentiment analysis classes, namely extremely positive, very positive, positive, neutral, negative, very negative, and extremely negative. Then, a fuzzy logic system is applied to measure customer satisfaction at a fine-grained level. The experimental results demonstrate that the proposed analysis has an improved performance over the baseline works.
- Copyright
- © 2020 The Authors. Published by Atlantis Press SARL.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
Sentiment analysis (SA) is a challenging research area that uses natural language processing (NLP), text mining, and computational linguistics. It has a wide range of applications in different domains, such as in politics, education, business, and others fields [1]. In the business domain, customers rely on online reviews for making purchase decisions. Similarly, businesses use sentiment-based applications to analyze user feedback, brand loyalty, and customer satisfaction with their products, assisting in quality improvement to increase revenue [2,3].
Most of the most recent work on SA for customer feedback analysis has been based on the binary classification of customer reviews (i.e., positive or negative) with less focus on a fine-grained sentiment classification. With fine-grained sentiment classifications, reviews are classified into multiple sentiment classes, such as weak, moderate, strong, or very strong [4]. Fuzzy-based SA is one feasible solution for classifying customer reviews at different granularity levels. Fuzzy-based SA aims at classifying sentiments using multiple polarity values, and it can involve relative values, such as positive, very positive, negative, very negative, or neutral [5].
Fuzzy-based SA systems for the analysis of customer feedback and satisfaction are based on computing the sentiment of opinion words by using three approaches: lexicon-based, corpus-based, and manual [6]. However, the sentiment strength of opinion words can be affected by the presence of modifiers such as very, slightly, almost, never, and others. [7]. Recent studies in this area have identified that the proper formulation and incorporation of linguistic hedges can enhance the performance of fuzzy-based SA systems [8]. However, existing studies on fuzzy-based SA using linguistic hedges [9] have used only a limited set of hedges, and there is a lack of extended rule-sets using fuzzy logic for the fine-grained SA of customer feedback and satisfaction.
To address the aforementioned issues, there is a need for the development of a fuzzy-based SA system using an extended set of fuzzy linguistic hedges and a revised set of rules for the fine-grained SA of customer feedback and satisfaction. In this study, a fuzzy-based SA system has been proposed to classify user reviews in order to measure customer satisfaction at a fine-grained level by exploiting the effect of an extended set of fuzzy linguistic hedges on sentiment carrier words.
1.1. Literature Review
In this section, we present a review of selected studies conducted on the use of fuzzy logic for the fine-grained SA of customer feedback and satisfaction.
Ghani et al. [2] proposed a fuzzy-based system to quantify customer loyalty by performing the sentiment classification of online reviews. They undertook the sentiment scoring of customer reviews and then applied a fuzzy logic system to measure customer loyalty. Their experimental results were promising and a high accuracy of 94% was obtained, outperforming baseline methods.
Dalal and Zaveri [9] developed an approach to perform the sentiment classification of customer reviews by using fuzzy linguistic hedges and opinion words. Their proposed fuzzy functions operated on different linguistic hedges and opinion words for a fine-grained SA. Their sentiment mining approach can be applied successfully for both binary as well as fine-grained sentiment classifications. Moreover, for linguistic hedges, their proposed fuzzy functions provide greater accuracy, and they have the ability to be adapted in the future to make use of more intensifiers with versatile weighting.
Reshma et al. [10] designed a supervised fuzzy inference system based on hedge functions in the presence of an adverbial modifier. They applied this method to the n-gram patterns of adverbial modifiers. In addition to the identification of opinions, linguistic hedges were also identified, and fuzzy rules were applied to magnify the effect of an opinion. The system produced varying degree values to describe vague and imprecise information, providing promising results.
Katarya and Verma [11] proposed a fully web-based system to classify consumer sentiments using computational intelligence techniques that included fuzzy c-mean clustering. The user-friendly interface greatly attracted the target audience, and further enhancements can be made by focusing on privacy, accuracy, and reliability.
Srivastava and Bhatia [12] developed a supervised fuzzy inference system to quantify the strength of subjective phrases when adverbial modifiers change the intensity of opinion word force with hedges. They conducted an experiment with 50 sentences containing modifiers of unigram and bigram patterns, such as “the screen is beautiful” and “the screen is very beautiful.” They indicated that some error minimization techniques should be used in the future, such as back propagation, so opinion words will be extracted from the input statement and classified using fuzzy logic.
Nadali et al. [13] proposed a fuzzy logic model for the semantic classification of customer reviews using a holistic lexicon-based approach. The aim of the study was to increase the accuracy of classifications by combining adjectives, adverbs, and verbs. Experimental results demonstrated that the system was promising. In the future, this model can be improved by conducting parameter tuning.
Rahmath and Ahmad [14] proposed a multi-step opinion mining system that used a rule-based approach to extract features and sentiment scoring to assign polarity class. The proposed technique utilized fuzzy functions to emulate the effect of various linguistic hedges. The fuzzy linguistic hedges operated on opinion descriptors. The accuracy of this system was satisfactory. As a future development for this research, the rule-set can be refined to extract more dependency relations from datasets.
M. Haque [15] developed a fuzzy-based SA system to assist customers in having a better knowledge of the products that they are interested in. The author tried to quantify what is called “PN-polarity,” whether a point expresses an opinion that could have a positive or negative value based on SentiWordNet (SWN) and tokenization techniques. In the future, it can be extended for feature-based analysis.
Dey and Haque [16] proposed an opinion mining system for classifying customer feedback at different granularity levels. It was observed that the performance of the proposed system was better than other comparing methods for the car domain. However, the scope of the system can be extended to learn context-aware sentiments from a training data set.
Al-Miamani et al. [17] proposed a semantic fuzzy-based approach using term presence, stemming, and the K-nearest algorithm. The proposed approach dramatically enhanced improvements to presentation, summarizing, and extraction in order to resolve semantic problems in opinion mining. Future work can be extended through the help of a semantic web methodology.
Toujani and Akaichi [18] worked on the SA of user reviews in the Tunisian language using semi-supervised techniques with the help of a fuzzy support vector machine technique. The language issue was the worst limitation, causing degraded results. In future research, the authors intend to focus on ambulatory-based machine learning to depict spatiotemporal changes in sentiment categorization.
Miao et al. [19] proposed a technique for the automatic extraction and classification of product features and sentiments acquired from different sites. For this purpose, different linguistic hedges were integrated, and the performance of the proposed system was evaluated by applying different computational techniques. Further improvements can be made by introducing additional primary membership functions, such as triangular and trapezoidal functions, with approximate reasoning techniques.
1.2. Problem Statement
Existing studies on fuzzy-based SA using linguistic hedges for the analysis of customer feedback and satisfaction have used a limited set of linguistic hedges, [9] and there is a lack of extended rule-sets for fine-grained SA [4]. Therefore, it is important to develop an extended fuzzy-based SA system for the analysis of customer feedback and satisfaction that uses an extended set of fuzzy linguistic hedges for the efficient classification of customer sentiment, thus overcoming the limitations of the aforementioned prior studies. A fuzzy-based SA scheme is proposed in this study that uses an extended set of fuzzy linguistic hedges and a rule-set for the fine-grained SA of customer feedback and satisfaction.
1.3. The Aim of the Study
The aim of this study is to develop a fine-grained SA system using an extended set of fuzzy linguistic hedges for the efficient classification of user feedback and customer satisfaction by extending the work of [4,9].
1.4. Contributions
The development of an extended set of fuzzy linguistic hedges for the efficient classification of sentiment carrier words in customer feedback.
The proposal and evaluation of an extended rule-set for classifying customer opinions at multi-class levels.
The development of a fuzzy-based SA system using an extended set of fuzzy linguistic hedges for the fine-grained SA of customer feedback and satisfaction.
An evaluation of the efficiency of the proposed method was performed using state-of-the-art methods.
1.5. Research Questions
The following research questions are addressed in this study:
RQ1: What is the role of an extended set of fuzzy linguistic hedges with respect to the efficient sentiment classification of user reviews for measuring customer satisfaction?
RQ2: How can an existing SA system be improved by extending a rule-set?
RQ3: What is the efficiency of the proposed fine-grained SA system in respect to state-of-the-art methods?
The remainder of this paper is organized as follows: Section 2 describes the proposed methodology, Section 3 provides results and discussion, and finally, Section 4 presents a conclusion and ideas for future work.
2. MATERIAL AND METHODS
The proposed system is comprised of five modules (Figure 1): (i) data acquisition, (ii) preprocessing, (iii) the analysis of linguistic hedges, (iv) the output of a fine-grained SA, and (v) the use of a fuzzy logic-based system for analyzing customer feedback and satisfaction.
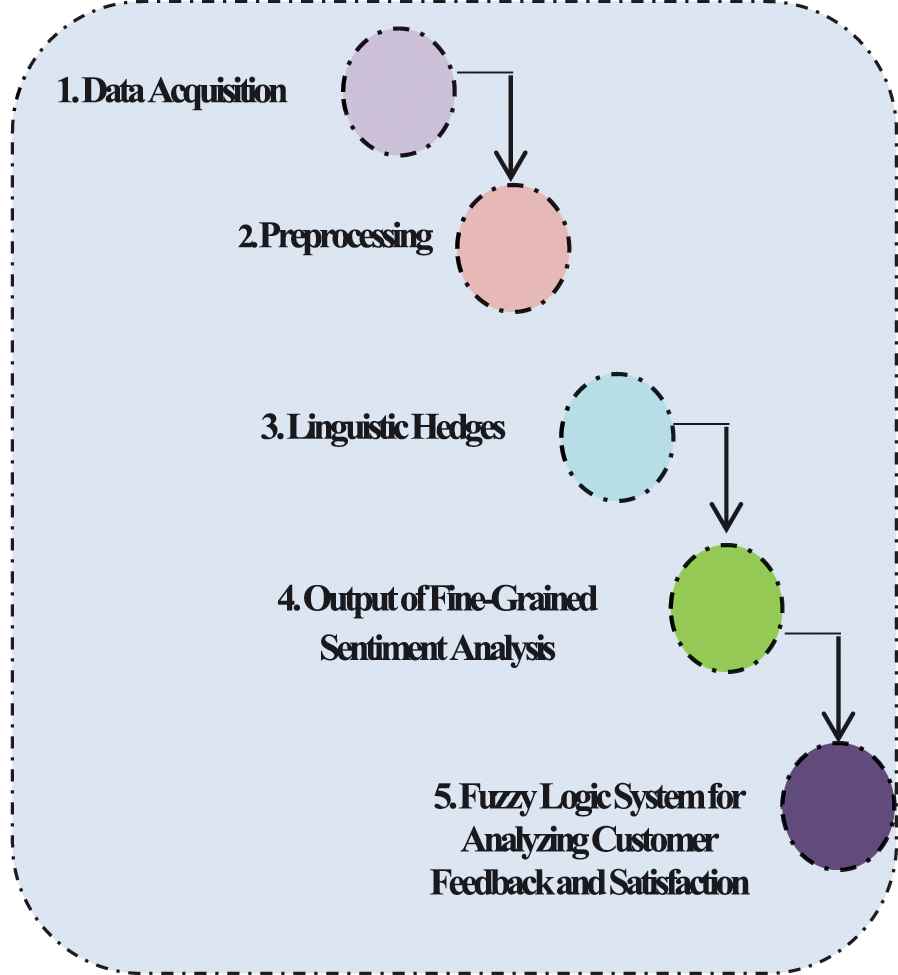
Projected flow of the system.
2.1. Data Acquisition
To conduct the experiments, we used publicly available datasets of user reviews from three domains, namely (i) drugs (D1), (ii) electronics (D2), and (iii) mobile phones (D3). Descriptions of the acquired data sets are presented in Table 1, showing that there were 1125 reviews in data set D1, 1240 reviews in D2, and 1140 reviews in D3. Furthermore, the number of sentences in each domain is also listed.
| Data Set ID | Domain | No. of Reviews | No. of Sentences |
|---|---|---|---|
| D1 | Drugs | 1125 | 4216 |
| D2 | Electronics | 1240 | 3330 |
| D3 | Mobile phones | 1140 | 3927 |
Dataset details.
2.2. Preprocessing and Text Preparation
The proposed method involves different preprocessing steps, including tweet cleansing, tokenization, stop word removal, and lemmatization [20], which are as follows:
Tweet cleansing: This step removes special symbols, such as query terms, hashtags, URLs punctuation, and special characters, from the input text.
Word tokenization: The Python-based Natural Language Toolkit (NLTK) tokenizing system is used to tokenize sentences into individual words. Examples of tokenized words include happy and very.
Stop word removal: Stop words, such as from, I, and am, are identified using a predefined list of stop words and eliminated using a text processing script written in the Python language.
Lemmatization: Lemmatization is applied to reduce the words to their stem/root form. Python NLTK-based Lemmatizer is used for this purpose. For example, computers and printers are lemmatized to computer and printer, respectively.
2.3. Opinion Words
These are the input and output variables in the form of words and sentences in any natural language. For example, in the sentence “This drug has an awfully bad taste,” drug is a linguistic variable having linguistic value: bad (opinion word). To extract opinion words from a given text, each term is searched for in the opinion lexicon [21]. A partial list of opinion words is provided in Table 2.
| Injustice | Satisfactory | Marvellous |
| Loud | Favourite | Peaceful |
| Progress | Fearless | Insensitivity |
| Regard | Efficient | Conflict |
A partial list of opinion words.
In next step, a sentiment score is assigned to each of the identified opinion words using the SWN lexicon [22], which contains more than 60,000 entries, for assigning sentiment scores to opinion words appearing in the customer feedback text.
Each word in SWN has different senses. To decide the accurate sense of a sentiment word, we consider three sentiment scores: positive, negative, and neutral multiple senses in SWN [20]. First, we aggregate the sentiment scores of the positive, negative, and neutral words (Eqs. 1–3) as follows:
In the next step, we compute the average sentiment scores for the positive, negative, and neutral words using Eqs. (4–6) as follows:
For example, in the customer review text: “This drug has an awfully bad taste and makes you vomit,” there is a negative opinion word bad with a sentiment score of −0.625 that was computed using Eq. (5) (Table 3).
| Sentence ID | Input Sentence | Opinion words |
|
|---|---|---|---|
| Opinion Word | Sentiment Score | ||
| 1 | This drug has an awfully bad taste | Bad | −0.625 |
Review text and its associated opinion words.
2.4. Linguistic Hedges
A linguistic hedge is used to modify the shape of a fuzzy set qualifier (linguistic variable). For example, adverbs such as extremely, very, quite, somewhat, and others are some of the hedges commonly used to modify a fuzzy set. In their work on fuzzy linguistic hedges, Dalal and Zaveri [9] proposed a fuzzy-based SA system with modified fuzzy concentrator scores. They used only six modifiers as linguistic hedges. Our study is an extension of this proposed method, increasing the number of enhancer and reducer terms to as many as 20, and the fuzzy functions for linguistic hedges proposed by Khan et al. [23] have also been calibrated for an increased number of power functions to address the extended set of modifiers. The additional hedges were acquired from the published literature [24]. For example, consider the following sentence: “LG AC is totally friendly to the human environment. It produces cooling with incredibly low energy consumption.” Here the words totally and incredibly are linguistic hedges (enhancers), magnifying the overall polarity of the sentence.
Table 4 shows a list of adopted [9] and newly proposed enhancing and reducing intensifiers used as linguistic hedges for the fuzzy-based, fine-grained SA along with example sentences. The implementation code of the aforementioned module is presented in Appendix A and Table 4 shows a list of linguistic hedges (enhancers and reducers) for opinion words.
| SS.No | Linguistic Hedge/Modifier | Fuzzy Function | Reference |
|---|---|---|---|
| 11 | A little, a few | 1-(1-SentiWord Score)P, P = 1.3 revised-score) = 1-(1-ow-score) modf-strength | [9] |
| 22 | Somewhat, approximately, nearly | 1-(1-SentiWordScore) P, P = 1.2 | [9] |
| 23 | Very, really | 1-(1-SentiWordScore)P, P = 2 | [10] |
| 44 | Slightly, weakly | 1-(1-SentiWordScore)P, P = 1.7 | [25] |
| 15 | Extremely, tremendously | 1-(1-SentiWordScore)P, P = 3 | [25] |
| 16 | Very very | 1-(1-SentiWordScore)P, P = 4 | [25] |
| 77 | Outrageously | 1-(1-SentiWordScore)P, P = 1/4 | Proposed |
| 88 | Strikingly | 1-(1-SentiWordScore)P, P = 1.5 | Proposed |
| 99 | Fairly | 1-(1-SentiWord Score)P, P = 0.8 | Proposed |
| 110 | Too | 1-(1-SentiWord Score)P, P = 1.6 | Proposed |
| 111 | Marginally | 1-(1-SentiWordScore)P, P = 1.7 | Proposed |
| 112 | Incredibly | 1-(1-SentiWordScore)P, P = 2.5 | Proposed |
| 113 | Exquisitely | 1-(1-SentiWordScore)P, P = 2.8 | Proposed |
| 114 | Luminously | 1-(1-SentiWordScore)P, P = 2.5 | Proposed |
| 115 | Awfully | 1-(1-SentiWordScore)P, P = 2.3 | Proposed |
| 116 | Virtually | 1-(1-SentiWordScore)P, P = 2.2 | Proposed |
| 117 | Phenomenally | 1-(1-SentiWordScore)P, P = 3.5 | Proposed |
| 118 | Totally | 1-(1-SentiWordScore)P, P = 4.5 | Proposed |
| 119 | Ravishingly | 1-(1-SentiWordScore)P, P = 3.2 | Proposed |
| 220 | Mushy | 1-(1-SentiWordScore)P, P = 3 | Proposed |
Fuzzy linguistic hedges.
2.4.1. Computing the sentiment score of the linguistic hedges
To compute the sentiment score of the linguistic hedges (enhancers and reducers) present in the input sentences, we have proposed a revised fuzzy scoring technique (Eq. 7) for linguistic hedges based on Zedah's proposition (Eq. 7). The proposed method is inspired by the work performed by [9,10]. These studies used a limited number of hedges, and accordingly, the assigned scores have also been revised based on the intensity of the linguistic hedge. The revised scoring is proposed in consultation with linguistic experts. Five human annotators are asked to assign a sentiment score to each newly proposed linguistic hedge. Some example review sentences are presented in Appendix B. After assignment of the sentiment score, the majority voting scheme is used (Eq. 7) to assign the final score.
After putting all these score in the formula we can easily derived out fuzzy sentiment score
The revised sentence-level fuzzy-based sentiment score based on the modified fuzzy-based score (Eq. 8) is computed as follows:
Here
| Linguistic Hedges |
||||
|---|---|---|---|---|
| Sentence ID | Input Sentence | Enhancer Modifier | Reducer Modifier | Negation |
| 1 | This drug has an awfully bad taste | Awfully (sentiment score: 2.3) | – | – |
| 2 | I am not really satisfied with it | Really (sentiment score: 2) | – | Not (−1) |
Review text and the associated linguistic hedges.
Table 6 shows description of Symbols associated with opinion words and linguistic hedges.
| Mathematical Symbol | Description |
|---|---|
| Average sentiment scores for the ith positive word | |
| Average sentiment scores for the ith negative word | |
| Average sentiment scores for the ith neutral word | |
| Aggregate sentiment score of the positive words | |
| Aggregate sentiment score of the negative words | |
| Aggregate sentiment score of the neutral words | |
| Total number of synsets of word |
|
| Fuzzy sentiment score | |
| Lexicon score | |
| Hedge score |
Symbols associated with opinion words and linguistic hedges.
2.4.2. Example review
We now apply the proposed technique on the input review: “This drug has an awfully bad taste and makes you vomit. I am not really satisfied with it.”
Taking the first sentence: We take the first sentence of the review as: “This drug has an awfully bad taste and makes you vomit.” In this sentence, the sentiment score retrieved from the SWN lexicon (sentiwordnet.isti) of the opinion word bad is 0.625, showing a negative sentiment class, so the score will be multiplied by −1. The modf_strentgth of the fuzzy linguistic hedge (modifier) awfully has received a value of 2.3, which was retrieved from Table 4. Therefore, the intensified sentiment strength of an opinion word is computed as follows (using Eq. 8).
Taking the second Sentence: We take the second sentence of the review as: “I am not really satisfied with it.” In this sentence, the sentiment score retrieved from the SWN lexicon of the opinion word satisfied is 0.1875, showing a positive sentiment class. The modf_strentgth of the fuzzy linguistic hedge (modifier) really is 2, which was retrieved from Table 4. Therefore, the intensified sentiment strength of the opinion word is computed as follows (using Eq. 8), and as this has a negation in the sentence, the value is multiplied with −1.
Table 7 shows sample sentences and their associated opinion words and linguistic hedges.
| Opinion Words |
Linguistic Hedges |
|||||
|---|---|---|---|---|---|---|
| S.No | Input Sentence | +ve | −ve | Enhancer | Reducer | Negation |
| 1 | This drug has an awfully bad taste | Bad (−0.625) | Awfully (sentiment score: 2.3) | – | – | |
| 2 | I am not really satisfied with it | Satisfied (0.1875) | Really (sentiment score: 2) | – | Not (−1) | |
Review text and associated opinion words and linguistic hedges
2.4.3. Computing the review-level sentiment score
To compute the sentiment score of an entire review, the average score of all sentences is computed as follows:
Since it is necessary for the value of
As an enhancement to the work proposed by Dalal and Zaveri [9], we suggest an extended set of rules. Dalal and Zaveri introduced a rule-set at five levels of granularity, whereas we extend it to seven levels (Eq. 10) for tagging the input of a customer review to a sentiment class at a fine-grained level. This is computed as follows:
2.5. Output of Fine-Grained SA
The output of the fine-grained SA is a sentiment class assigned on the basis of Eq. (10). Using the aforementioned value of
The aforementioned sentiment class (i.e., very negative) is the output of our proposed fine-grained SA system. In the next phase, we measure customer satisfaction by applying different steps of the fuzzy logic system as shown in the following section.
2.6. Fuzzy Logic-Based System for Measuring Customer Satisfaction
In this phase, we apply the fuzzy logic system (Figure 2) to quantify customer satisfaction with a product based on a given user review. For this purpose, the following steps are taken [2]:
Step 1: Define the input and output of the linguistic variables and their respective terms (fuzzy sets).
Step 2: Transform the crisp input into fuzzy values using the membership function (Fuzzification).
Step 3: Build the membership functions for the fuzzy sets
Step 4: Build the fuzzy if/then rules.
Step 5: Defuzzification: Transform the fuzzy values into crisp values (non-fuzzy values).
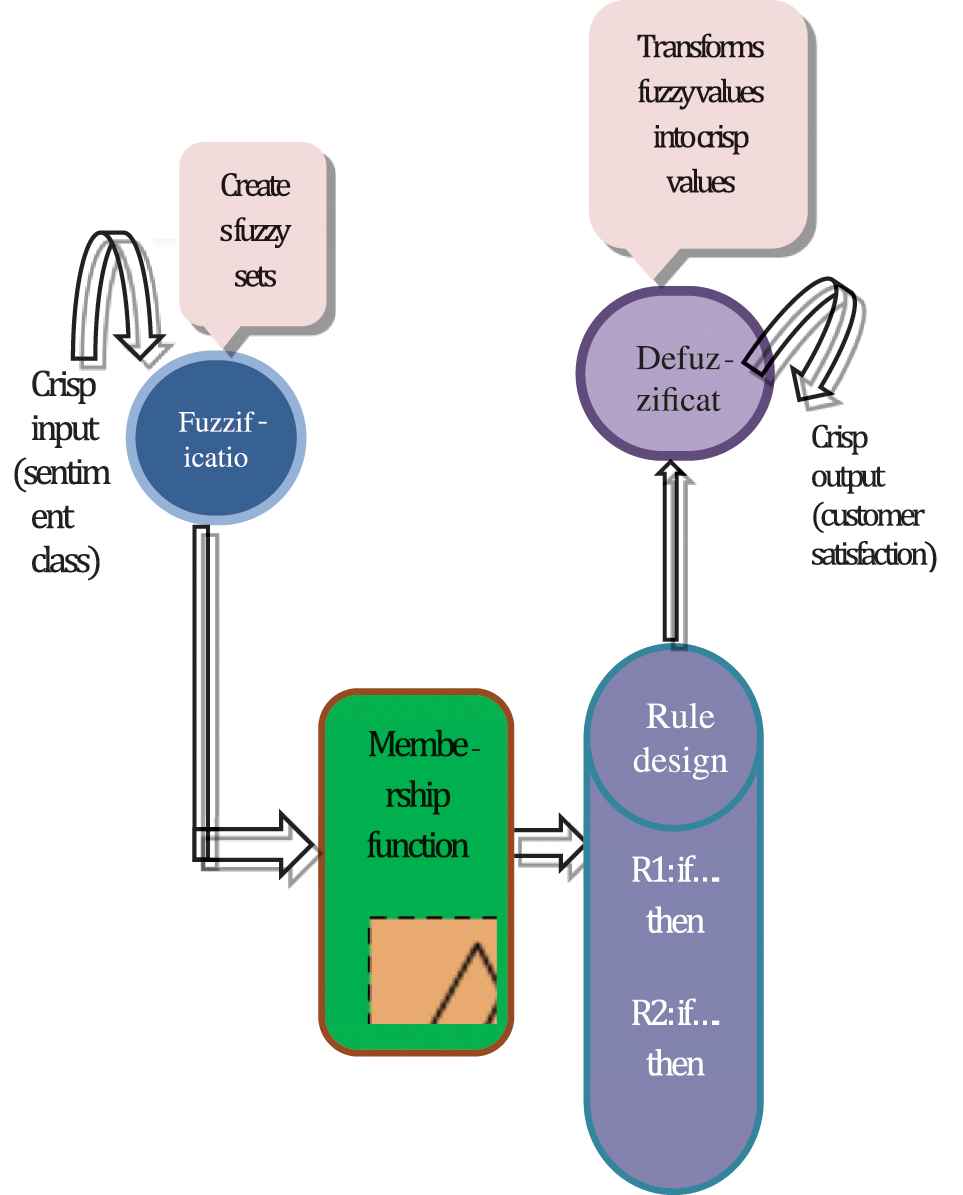
Fuzzy logic-based system.
2.6.1. Input-output linguistic variables
The input–output linguistic variables for the fuzzy system consist of a set of linguistic terms described as follows: We take sent_class(c) as an input variable and customer satisfaction(cs) as an output linguistic variable, and their respective linguistic terms are: (c) = {extremely negative, very negative, negative, neutral, positive, very positive, extremely positive} and (cs) = {extremely low, very low, low, moderate, high, very high, extremely high} [26].
2.6.2. Fuzzification
In a fuzzy logic system, the first step includes the identification of the input–output variables. In this process, a crisp set is transformed into a fuzzy set, and this process is called fuzzification. The aim of the proposed fuzzy model is to measure the satisfaction level for a customer as either extremely low, very low, moderate, high, very high, or extremely high. Mathematically, we describe the fuzzy logic system using Eq. (11) as follows [27]:
2.6.3. Fuzzy membership function
In a fuzzy logic system, the fuzzification and defuzzification steps are performed using membership functions in order to map crisp input values into fuzzy values. For instance, in Figure 3, the membership functions for the linguistic terms of the sent_class variable are plotted.
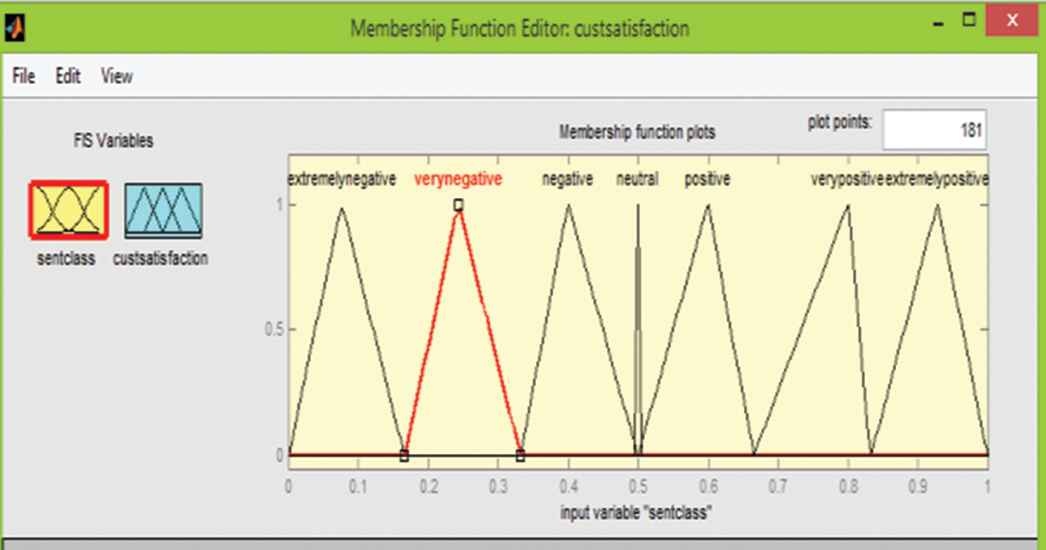
Membership functions for the linguistic variable sent class.
The fuzzy membership functions are used for making a decision on the input crisp values. These include Gaussian membership, Bell membership, triangular membership function, and others. [13]. However, in this study, we used a triangular membership function (trimf), represented as follows (Eq. 12):
The triangular membership function is defined by three parameters [a, b, c], where a represents the lower boundary, c is the upper boundary, 0 is the membership degree, and b represents the center, where the membership degree is 1. The graphical representation is given as follows (Figure 4):

The shape of trimf.
2.6.4. Fuzzy if/then rules
Now we will construct some fuzzy if/then rules to control the output variable. The general form of the fuzzy rules can be expressed as follows [28]: If x is A then y is B: where A and B are linguistic values defined by the fuzzy sets on the ranges of x and y, the If part is the antecedent while the then part is the consequent [2]. An example of such a rule is: If (sentclass is very negative) then (custsatisfaction is low). The rules included in our fuzzy-based system are listed in Table 8.
| Fuzzy Rules | |
|---|---|
| 1. | If (sentclass is extremely negative) then (customersatisfaction isextremely low) |
| 2. | If (sentclass is very negative) then (customersatisfaction is very low) |
| 3. | If (sentclass is negative) then (customersatisfaction is low) |
| 4. | If (sentclass is neutral) then (customersatisfaction is moderate) |
| 5. | If (sentclass is positive) then (customersatisfaction is high) |
| 6. | If (sentclass is very positive) then (customersatisfaction is very high) |
| 7. | If (sentclass is extremely positive) then (customersatisfaction is extremely high) |
Fuzzy rules for customer satisfaction.
2.6.5. Defuzzification
To transform the fuzzy value into a crisp value and find the final customer satisfaction value, the defuzzification function is used. The well-known Mamdani defuzzifier center of gravity operator is used in this study. It computes the center of gravity using Eq. (13) [2] as follows:
Rules for defuzzification: In this step, the fuzzy rules are defined in the form of if-then conditional statements [29] where x represents the sentiment class while Y represents customer satisfaction. The defuzzification rules are presented in Table 9.
| Rules for Defuzzification |
|---|
| → if (x ≤ 0.166) then Y = ‘extremely low’ |
| → if (x ≥ 0.166 and x ≤ 0.332) then Y = ‘very low’ |
| → if (x ≥ 0.332 and x ≤ 0.5) then Y = ‘low’ |
| → if(x = 0.5) then Y = ‘moderate’ |
| → if (x ≥ 0.5 and x ≤ 0.666) then Y = ‘extremely high’ |
| → if (x ≥ 0.666 and x ≤ 0.832) then Y = ‘very high’ |
| → if (x ≥ 0.832 and x ≤ 1) then Y = ‘high’ |
Defuzzification rules.
Figure 5 depicts a snapshot in which the membership functions of the linguistic terms for variable customer satisfaction are plotted:
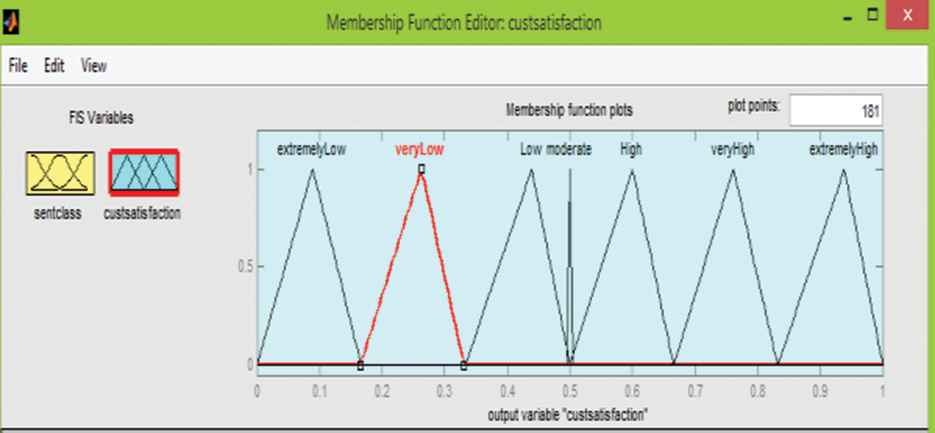
Membership functions for linguistic variable customer satisfaction.
We apply the rules that are simulated in MATLAB for evaluating customer satisfaction with sentiment scores that show the relationship between sentiment scores and customer satisfaction. For example, Figure 6 depicts that if we have a sentiment score of 0.191, it is considered more negative than a customer satisfaction score of 0.42, which is also low and very close to the value of the sentiment score.
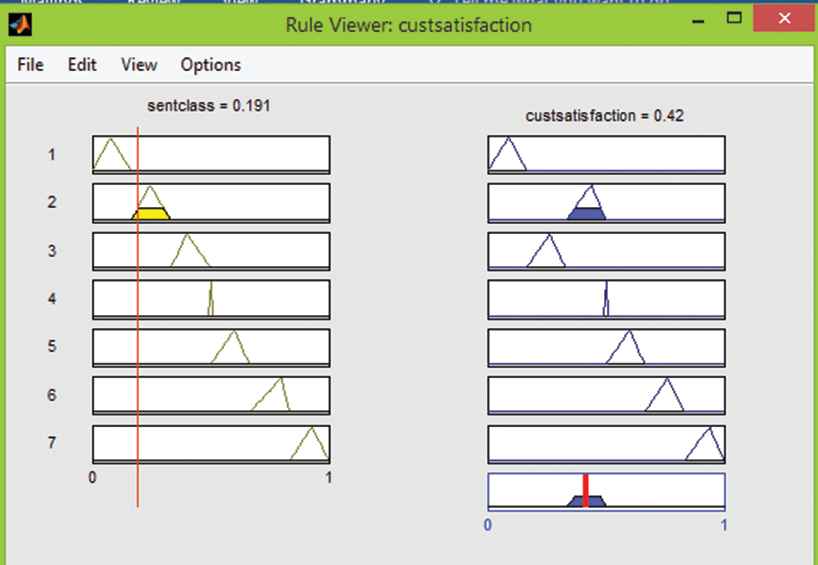
MATLAB rule viewer.
For the given input customer review (“This drug has an awfully bad taste and makes you vomit. I am not really satisfied with it”), we have reached the conclusion that customer satisfaction level is low, which means that the customer is not satisfied based on the example review presented in Section 3.3.2.
We again and again apply these rules at our different sentences and got results again that are simulated in MATLAB for evaluating customer satisfaction with sentiment scores that show the relationship between sentiment scores and customer satisfaction. For example, Figure 6 depicts that if we have a sentiment score of 0.191, it is considered more negative than a customer satisfaction score of 0.42, which is also low and very close to the value of the sentiment score.3.
Table 10 shows description of Symbols associated with Fuzzy module.
| Mathematical Symbol | Description |
|---|---|
| Degree of the membership function of x in A | |
| X | The universe of discourse or universal set. |
| Trimf | Triangular membership function |
| Y | Result of defuzzification |
| Membership function | |
| min | Lower limit for defuzzification |
| max | Maximum limit for defuzzification |
Symbols associated with fuzzy module.
3. RESULTS AND DISCUSSION
In this chapter, we present the results obtained by answering the posed research questions.
3.1. Answer to RQ1: What Is the Role of an Extended Set of Fuzzy Linguistic Hedges with Respect to the Efficient Sentiment Classification of User Reviews for Measuring Customer Satisfaction?
To answer RQ1, we extended a set of fuzzy linguistic hedges (details given in the methods section). It is evident from Table 4 that the studies conducted by [9,10,25] used 12 linguistic hedges along with their fuzzy functions. However, we have extended this with 12 additional fuzzy linguistic hedges along with their fuzzy functions. Table 11 shows a list of example sentences, along with their detected linguistic hedges and their polarity-related details. For example, in input sentence number 01, the detected hedges are awfully and exquisitely, which were not available in the baseline studies [9,10]. However, when the sentence is passed through the proposed system, the newly assigned polarity class is very positive with a sentiment score of 0.7259.
| S. No. | Input Sentence | Detected Hedge(s) | Availability in Baseline Papers [9,10] and Sentiment Scoring | Availability in Proposed Work and Sentiment Scoring | Polarity Change or no Change |
|---|---|---|---|---|---|
| 01 | Suffering from pain in my stomach gave me awfully bad problems with bloat and dizziness. I was prescribed this drug, and it has worked wonders exquisitely! | Awfully, exquisitely | Hedges not found | Yes Very positive 0.7259 |
Polarity shift |
| 02 | I had a very very bad infection that required the use of a drug. Flagyl had strikingly bad effects on my health | Very very, strikingly | Strikingly not available, Very negative 0.24549 |
Yes Extremely negative 0.09724 |
Polarity shift |
| 03 | This mushy balm helps me to relieve muscle pain. And, it makes me marginally comfortable | Mushy, marginally | Hedges not found | Yes Very positive 0.6726 |
Polarity shift |
| 04 | I have been continuously fatigued for 2 months and my sleeping routine has been ravishingly disturbed. My doctor recommended this tranquilizer to me, and it is very very effective | Ravishingly, Very very | Ravishingly, Very very Extremely positive 0.8586 |
Yes Neutral 0.50 |
Polarity shift |
| 05 | The LED light is basically colorful with a really solid aluminum wire. But with the combination of an oxidized frame, the LED comes through with an incredibly bright color | Really, incredibly | Incredibly not available 0.5586 Positive |
Yes 0.6914 Very positive |
Polarity shift |
| 06 | TV is an extremely friendly agent of socialization. It makes marginally wrong boundaries between family gatherings | Extremely, marginally | Marginally not available 0.6547 Positive |
0.4519 Negative |
Polarity shift |
| 07 | Early in her life she became almost totally blind as she used her mobile phone too dangerously, and she entered an eye care hospital when she was fourteen years old | Totally, too | Too not available 0.6333 Positive |
Yes 0.3755 Negative |
Polarity shift |
| 08 | Sometimes she tries to spell very short words with her mobile dictionary. But she is too young to remember the hard words | Very, too | Too not available 0.5860 Positive |
Yes 0.61055 Very positive |
Polarity shift |
New vs. old hedge associations.
Considering sentence number 02, the detected linguistic hedges are very very and strikingly. The linguistic hedge very very is present in the baseline studies, and therefore, the assigned sentiment class is very negative on the basis of the computed sentiment score of 0.24549. However, when the same sentence is passed through with the newly proposed classifier, then both of the aforementioned linguistic hedges (very very and strikingly) are detected and the sentiment class is accordingly revised to extremely negative on the basis of the newly computed sentiment score (0.09724).
Table 12 shows that the performance of the proposed system using linguistic hedges is better than not using linguistic hedges
| A | P | R | F | |
|---|---|---|---|---|
| With linguistic hedges (proposed) | 0.85 | 0.85 | 0.92 | 0.90 |
| Without linguistic hedges [2] | 0.79 | 0.81 | 0.82 | 0.82 |
Performance of the proposed system using.
3.2. Answer to RQ2: How Can an Existing SA System Be Improved by Extending a Rule-Set?
The baseline study conducted on the development of an SA (opinion mining) system used fuzzy linguistic hedges and five classes (VP, PO, NU, NE, and VN) in its rule-set. As an enhancement of the baseline study, we proposed two additional classes (extremely positive and extremely negative), thereby increasing the number of classes from five to seven. The results (output) presented in Table 13 depict the polarity classes, and the sentences using our proposed method produce a polarity shift. This polarity shift results in an accuracy improvement over the baseline study.
| Study | Domain | No. of Classes in Rule-set | Accuracy (%) |
|---|---|---|---|
| Dalal and Zaveri [9] | SA of customer feedback | 05 | 86.4 |
| Priyanka and Gupta [4] | SA of customer feedback | 05 | 84.88 |
| Ghani et al. [2] | SA of customer feedback | 3 | 82.38 |
| Proposed method | SA of customer feedback | 07 | 90 |
Accuracy-based comparison.
The accuracy-based comparison presented in Table 14 shows that the proposed extension in the number of classes in the rule-set has yielded better results through improved accuracy.
| S. No | Example Sentence | Polarity Score and Class Using the Rule-set Used in the Baseline Study [9,10] | Polarity Score and Class Using Revised the Rule-Set Used in the Proposed Method | Comments |
|---|---|---|---|---|
| 1 | So, this drug makes you awfully hungry and you feel like eating everything | 0.3441 Following Review is negative |
0.3441 Following review is very negative |
Polarity shift |
| 2 | My grandmother has been suffering from epilepsy, and a regular dose of this drug has been the phenomenally best treatment her of her disease | 0.8604 Following review is VERY positive |
0.8604 Following review is extremely positive |
Polarity shift |
| 3 | Traditional Chinese mobile phones sold fairly well all over the world | 0.6675 Following review is Positive |
0.6675 Following review is very positive |
Polarity shift |
| 4 | When her fingers are too tired to write messages on the mobile phone, then she should stop chatting and take a rest | 0.6413 Following review is positive |
0.6413 Following review is positive |
No shift |
| 5 | Your loving attitude toward her in this condition will be perfect, and it will be the very very best treatment for her disease | 0.8836 Following review is very positive |
0.8836 Following review is in extremely positive |
Polarity shift |
Computation of polarity class shift w.r.t rule-set of the baseline and proposed work.
Algorithm 1 An extended set of fuzzy linguistic hedges for the efficient classification and measurement of customer satisfaction.
Step I: Input Tweet (t) dataset (D) as csv file.
Step II: Break tweets in words as tokens using tokenizer.
Step III: Build and import the SentiWordNet Lexicon to assign sentiment score to each opinion word.
Step IV: Build fuzzy linguistic hedges
Step IV: Applying Preprocessing on each tweet
Step V: Procedure Customer_statisfaction using Fuzzy-Linguistic-Hedges (t)
Build Fuzzy linguistic Hedges Function
While (t in D) do
Sentiment Scoring of opinion words
Retrieve sentiment score from SentiWordNet for each opinion word using Eqs. (4–6)
Fuzzy Linguistic Hedges
if (hedges in t) then
Extract fuzzy linguistic hedges (Table 4)
Assign hedge score (Eq. 8)
end if
Sentiment Scoring of Fuzzy Linguistic Hedges
Compute final sentiment scoring (lexicon +hedge) using fuzzy function (sentence-level) using Eq. (9).
Assign sentiment as extremely +ive, very +ive, +ive, neutral, −ive, very −ive, or extremely −ive using
Apply fuzzy logic system on the sentiment classes
Perform input fuzzification using Eq. (11).
Applying if/then rules as listed in Table 8
Perform Defuzzification using Eq. (13).
Computing customer satisfaction
Applying membership function for computing customer satisfaction as ‘extremely low’, ‘very low’, ‘low’, ‘moderate’, ‘extremely high’, ‘very high’, ‘high’ (Figure 5 and 6)
Output: return Customer satisfaction
End while
End Procedure
3.3. Answer to RQ3: What Is the Efficiency of the Proposed Fine-Grained SA System in Respect to State-of-the-Art Methods?
To answer RQ3, we conducted an experiment to compare the performance of the proposed system with the baseline studies and the results are reported in Table 15. The results presented in Table 15 show that the performance of the proposed system in different evaluation metrics, namely precision, recall, F-measure, and accuracy, is better than that in the baseline studies, outperforming the compared methods with improved results. Therefore, it can be concluded that the extension of the number of classes (rule-set) and the use of the fuzzy linguistic hedges have made the proposed system more efficient in terms of fine-grained SA of customer feedback and satisfaction. Furthermore, the results presented in Table 15 show that the addition/extension of 12 new linguistic hedges along with the existing 12 hedges reported in the literature review, producing 24 linguistic hedges (12 + 12) and their associated fuzzy functions, has produced promising and improved results. Therefore, it can be concluded that the proposed system has outperformed the baseline studies with respect to more accurate sentiment classification.
3.4. Measuring Customer Satisfaction Level
To evaluate the efficiency of the proposed fuzzy-based model, we plotted a chart of the customer satisfaction levels with their respective sentiment score (Figure 7). The x-axis denotes customer satisfaction level, and the y-axis denotes sentiment score. If we have a sentiment score of 0.5, then it can be seen that the customer satisfaction level is also 0.5. We can also say that, if the sentiment score is 0.5, it is considered as neutral and customer satisfaction is 0.5, and thus, the level of customer satisfaction is moderate. We have analyzed that the customer satisfaction level is directly proportional to the sentiment score, and with an increase in sentiment score, there is a gradual increase in the customer satisfaction score. However, there is a limitation for one of the sentiment classes, negative (0.40), in that the customer satisfaction score decreases and is 0.25.

Evaluation of customer satisfaction level with sentiment score.
3.5. Statistical Analysis
Two experiments were conducted to investigate whether the proposed fuzzy-based fine-grained SA model for the analysis of customer feedback and satisfaction based on extended linguistic hedges is statistically more significant than that of a fuzzy-based SA system for customer feedback analysis based on opinion words only and that this does not occur by chance. We randomly chose 273 reviews from the dataset, and each review was classified by both the fuzzy-based SA system with extended linguistic hedges (proposed) and the fuzzy-based SA system without linguistic hedges. We formulated the following null and alternate hypothesis: H0: The error rate of the two models is the same, and HA: The error rate of both models is significantly different.
We computed the McNemar's test statistic (chi-squared) with one degree of freedom as follows [30]:
Table 16 shows the significant results.
| Baseline Model [2] without Linguistic Hedges (Opinion Words Only) Correctly Classified | Incorrectly Classified | |
|---|---|---|
| Correctly classified | 200 | 40 |
| Proposed model (with linguistic hedges) | 18 | 15 |
| Incorrectly classified |
Computation of performance differences between baseline (without linguistic hedges) and the proposed model (with linguistic hedges) using a significance test.
The results presented in Table 16 were obtained by conducting an experiment to evaluate the performance of one of the baseline SA methods that does not use linguistic hedges. The results show that the baseline method without using fuzzy linguistic hedges gave a poor performance (accuracy, precision, recall, and f-measure) for customer feedback SA. However, the experiment conducted on the analysis of customer feedback and satisfaction using linguistic hedges performed significantly better than the baseline method [2], achieving accuracy of 85%.
The statistical test has demonstrated that the difference between the performance of the proposed method (with linguistic hedges) and the baseline method [2] (without linguistic hedges) is statistically different. Disagreement between the two models (Table 16) can be observed in 60 reviews, and the two models behaved differently with the two treatments: with linguistic hedges and without linguistic hedges. After applying the McNemar's test, we received a chi-squared value of 3.46 and a two-tailed p-value of 0.015 for a degree of freedom = 1. Hence, the null hypothesis is rejected (p-value < 0.5) and alternate hypothesis is supported, and thus, the proposed fuzzy-based SA system with linguistic hedges has demonstrated greater statistical significance than the fuzzy-based SA without linguistic hedges.
It is evident from the above discussion that the inclusion of an extended set of fuzzy linguistic hedges has improved the performance of the proposed system significantly for the fine-grained SA of customer feedback and satisfaction.
4. CONCLUSION AND FUTURE WORK
The proposed system aimed at the development of a fine-grained SA system for analyzing customer feedback and satisfaction using an extended set of fuzzy linguistic hedges. It is comprised of the following modules: (i) customer feedback data-set collections in three different domains, namely mobile phones, electronics, and drugs, (ii) data-set cleaning using preprocessing, (iii) the sentiment classification of opinion words and linguistic hedges, (iv) output in the form of fine-grained SA, and (v) the application of a fuzzy-logic system for measuring customer satisfaction.
Using fuzzy-based linguistic hedges and an extended rule-set, the proposed method can be used to classify the input text (customer reviews) into seven SA classes, namely extremely positive, very positive, positive, neutral, negative, very negative, or extremely negative. Then, the fuzzy logic system is applied to analyze customer feedback and satisfaction.
The experimental results show the efficiency of the proposed system through the improved performance over the compared methods. The system can easily classify customer reviews into the aforementioned fuzzy-based sentiment classes for customer satisfaction through the extension of the linguistic hedges and rule-set.
4.1. Limitations
The proposed system cannot correctly classify ambiguous/context-dependent words, such as big, high, hard, and black. For example, in the input sentence “The prices of the drugs are very high, so they are not approachable for poor patients” the word high is giving positive polarity, and therefore, the entire sentence is classified as positive, which is incorrect.
The system cannot classify an input review with a grammatical mistake. For example, the input sentence “My pen is really the best thing in my pocket” is grammatically correct, but the sentence “Really best thing in my pocket is my pen” is wrong because it is grammatically incorrect.
A limitation of the proposed system while handling negations is that it can only handle explicit negations, whereas the negations in an abbreviated form cannot be classified. For example, the system can recognize the words cannot, but it cannot recognize the words cannot or can't.
The sentiment scoring technique used in this study is based on the SWN lexicon. If the sentiment score of an opinion word is not present in the SWN lexicon, then the system cannot correctly assign a sentiment score to the word, and an incorrect classification is made.
The proposed rule-set is based on seven polarity classes. An increase in the number of polarity classes can sometimes affect classification accuracy [31].
4.2. Future Work
The proposed system can be enhanced to correctly classify context-dependent words. For this purpose, some context/domain-dependent classification schemes can be incorporated for the efficient classification of these words (big, high, hard, and black). Additionally, incorporating a word sense disambiguation strategy can also assist in the classification of these kinds of ambiguous words.
The inclusion of a grammar or spell correction module in the preprocessing phase can improve the classification performance of the proposed system.
The negation handling module can be enriched by expanding the dictionary to cope with all kinds of explicit as well as abbreviated negations.
In addition to the SWN, other state-of-the-art sentiment lexicons, such as SenticNet, need to be investigated for assigning sentiment scores to the opinion words that are not available in the SWN.
Further experimentations are required with a varied number of polarity classes in the rule-set to evaluate the efficiency of the proposed system.
CONFLICT OF INTEREST
All authors declare that they have no conflict of interest.
AUTHORS' CONTRIBUTIONS
Conceptualization: AK, MZA. Data curation: WP, MZA. Formal analysis: UY, FKS. Investigation: WP, NJ. Methodology: WP, MZA. Project administration: AK. Resources: IAH, AK, NJ. Software: MZA, WP. Supervision: MZA. Validation: MZA, WP. Visualization: WP, UY, FKS, Writing—original draft: MZA. Writing—review and editing: IAH, AK. All authors read and approved the final manuscript.
Funding Statement
This Research work was supported by Zayed University Research Incentives Fund#R18052, co-funded by Norwegian university of science and technology, Ålesund, Norway.
ETHICAL APPROVAL
This article does not contain any studies with human participants performed by any of the authors and does not contain any studies with animals performed by any of the authors.
DATA AVAILABILITY
The supplementary data used to support the findings of this study are available from the corresponding author upon request.
ACKNOWLEDGMENTS
This Research work was supported by Zayed University Research Incentives Fund#R18052, co-funded by Norwegian university of science and technology, Ålesund, Norway.
SUPPLEMENTARY MATERIALS
Supplementary data related to this article can be found at
REFERENCES
Cite this article
TY - JOUR AU - Asad Khattak AU - Waqas Tariq Paracha AU - Muhammad Zubair Asghar AU - Nosheen Jillani AU - Umair Younis AU - Furqan Khan Saddozai AU - Ibrahim A. Hameed PY - 2020 DA - 2020/06/11 TI - Fine-Grained Sentiment Analysis for Measuring Customer Satisfaction Using an Extended Set of Fuzzy Linguistic Hedges JO - International Journal of Computational Intelligence Systems SP - 744 EP - 756 VL - 13 IS - 1 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.200513.001 DO - 10.2991/ijcis.d.200513.001 ID - Khattak2020 ER -