
A class of Bivariate SURE estimators in heteroscedastic hierarchical normal models
- DOI
- 10.2991/jsta.2018.17.2.11How to use a DOI?
- Keywords
- Asymptotic univariate shrinkage estimators; Heteroscedasticity; Hierarchical models; Multivariate shrinkage estimator; Stein’s unbiased risk estimators
- Abstract
In this paper, we first propose a class of bivariate shrinkage estimators based on Steins unbiased estimate of risk (SURE). Then, we study the effect of correlation coefficients on their performance. Moreover, under some mild assumptions on the model correlations, we set up the optimal asymptotic properties of our estimates when the number of vector means to be estimated grows. Furthermore, we carry out a simulation study to compare how various bivariate competing shrinkage estimators perform and analyze a real data set.
- Copyright
- Copyright © 2018, the Authors. Published by Atlantis Press.
- Open Access
- This is an open access article under the CC BY-NC license (http://creativecommons.org/licences/by-nc/4.0/).
1. Introduction
One of the most applicable class of models is the class of hierarchical models. It is well-known that the shrinkage estimates play an important role in hierarchical models. In this line, the James-Stein estimators, which combine the partial information of various sources, dominates some other estimators like the ordinary least squares estimators, Stein (1956) and James and Stein (1961). However, the good risk properties of shrinkage estimators make them appealing in many applicable disciplines. Undoubtedly, the basic works of James and Stein on shrinkage estimators became a foundation for the other progressing studies on hierarchical normal models. Stein (1962) described a hierarchical, empirical Bayes interpretation for the shrinkage estimators. Further studies have been done by Efron and Morris (1973), who tried to interpret these kinds of empirical Bayes estimators by several other competing parametric empirical Bayes estimators. Moreover, the homoscedastic (equal subpopulation variances) empirical Bayes interpretation of estimators as well as heteroscedastic (unequal subpopulation variances) ones has motivated various treatments of this problem in hierarchical normal models. For homoscedastic case, we can refer to Baranchik (1970), Strawderman (1971), Brown (1971, 1975) and Berger (1976) among the others, while the heteroscedastic situation have been addressed by a few authors. For more details see Hudson (1974), Xie et al. (2012), Ghoreishi and Meshkani (2014, 2015).
Following considerable work on univariate shrinkage estimators, the multivariate type of James-Stein shrinkage estimators have also been considered for random vectors of dimension r ≥ 3, which either shrink towards the origin vector or another given fixed vector, Lehmann and Casella (1998). James and Stein (1961) showed that the multiple homoscedastic shrinkage estimator of the population mean dominates the corresponding maximum likelihood estimator when r ≥ 3. It means that the multiple James and Stein shrinkage estimator always achieves lower MSE than the corresponding maximum likelihood estimator. Equivalently, the James and Stein multiple estimator makes the maximum likelihood estimator inadmissible when r ≥ 3.
From interpretation point of view, the James and Stein estimator, as an empirical Bayes, is based on the assumption that the population mean is a random vector with an unknown diagonal covariance matrix σ2I and this matrix is estimated from the data itself, Brown (2008), Brown and Greenshtein (2009) and Berger and Strawderman (2009). The main point on this approach is that it is achievable when the random vector of means has a dimension greater than or equal 3 and unfortunately it is not applicable for 2-dimensional random vectors.
The study of James and Stein (1961) on empirical Bayes shrinkage estimators have extended to the case of a general covariance matrix, i.e., where measurements are statistically dependent and may have different variances, see Strawderman (1971) and Bock (1975). They illustrated that the theoretical results on multivariate shrinkage estimator hold when r ≥ 3 and in addition the covariance matrix has the general form σ2D, which is known up to constant σ2.
To our knowledge, all results on multivariate homoscedastic James-Stein shrinkage estimators hold for large dimensions r ≥ 3.
The outlines of the paper are:
- 1)
We first introduce an alternative class of bivariate shrinkage estimators.
- 2)
We study the correlation effect on their performance.
- 3)
Since the correlation structure is the biggest challenge in bivariate setting, and this phenomenon can seriously threaten the truth of theoretical results, under some mild assumptions on the model correlations, we show that our proposed estimators have optimal asymptotic properties.
The paper is organized as follows. In Section 2, we review some basic concepts and define necessary notations. The main results of this work, including the risk properties of our bivariate conditional heteroscedastic SURE estimators, are presented in Section 3. We carry out a simple simulation study to evaluate the performance of our proposed bivariate empirical Bayes shrinkage estimators in Section 4 and illustrate the theoretical results for a real data set in Section 5. Necessary technical proofs are given in the appendix.
2. Preliminaries
Let
Moreover, The classical conjugate hierarchical model puts a prior of bivariate normal distribution on θi
Combination of two assumed model leads us to the following heteroscedastic hierarchical bivariate normal model
Application of Bayes theorem for model (2.2) gives us the bivariate posterior density
According to this distribution, we consider the posterior means as an alternative class of bivariate shrinkage estimators of θi. That is,
As one can see these estimators tend to shrink the sample vectors to the mean vector μ via some coefficients, having important roles to balance observations effect in estimation.
It is straightforward to check that the following relationship holds between the coefficients of estimators (2.3),
It is worth pointing out the following remark concerning our shrinkage estimators.
Remark 2.1.
Condition |ρi| → 0 is equivalent to assume separate shrinkage estimates for marginal variables. If λ1, λ2 → ∞, then our shrinkage estimates severely shrank to the observations. Moreover, if
Since the heteroscedastic model, though more appropriate for practical applications, is less well studied in higher dimensions, and it is unclear what types of bivariate shrinkage estimators are superior in terms of the risk, in this work, we propose SURE approach under some mild conditions on correlation coefficients. For our purpose, we adopt the quadratic loss function
Let us denote the corresponding risk function and its unbiased estimator by
For Bivariate shrinkage estimators (2.3), we have
Therefore, the corresponding risk function is obtained as follows
It is Straightforward to see that the Stein’s unbiased risk estimator of the
To estimate μ1, μ2, λ1, and λ2, one can minimize SURE(Λ, μ) with respect to these quantities. Setting
In order to elicit the solutions, we assume (λ1, λ2) ∈ [0,b]2, for relatively large real value b > 0. Then, we partition this cell into several tiny cells and apply (2.5) and (2.6) for (λ1, λ2) at each grid of these tiny cells and simultaneously compute μ1, μ2 and their corresponding SURE. The values of μ1, μ2, λ1, and λ2 that minimize the SURE function are considered the SURE estimates. So, the SURE approach leads us to the Stein’ unbiased risk estimators of Λ and μ which can obtain by minimizing SURE(Λ, μ) with respect to the Λ and μ, when the solutions exist. That is,
In this case, the corresponding SURE estimators are of the form
In the next section, we discus how our SURE estimators
3. Asymptotic properties of the bivariate SURE estimators
In this section, we show that the proposed bivariate SURE estimators (2.7) have optimal asymptotic properties in comparison with their competitor bivariate estimators. In order to check how well SURE(Λ, μ) function approximates the loss function
By rearranging the terms of the above equation, one has
To investigate the risk properties of our bivariate SURE estimators, we need to use Lemma (2.1) in Li(1986). In our setting, it is applicable when the absolute values of
Lemma 3.1.
For each t, the elements of
- i)
- ii)
- iii)
If
In Lemma (3.1)[iii], the upper bound for the absolute value of the correlation coefficients can be removed when a1i = a2i. Under this condition, both variables have the same variances and so the quantities
To proceed, we assume a homogeneous property for the correlation coefficients. It means either ρi ≥ 0, for all i = 1,2,⋯,N; or ρi ≤ 0, for all i = 1,2,⋯,N; which is a natural assumption for any relation between two assumed variables over sub-populations. For example, in a multinomial distribution, which can be approximated by a multivariate normal distribution, every two cell frequencies always has a negative correlation. With this assumption, the asymptotic property of our bivariate SURE function, SURE(Λ, μ), is given by the following theorem. The necessary conditions (C1-C3) are stated in the appendix.
Theorem 3.1.
For model (2.2), under the conditions C1-C3 and homogeneous property of the correlation coefficients, If
Another class of bivariate shrinkage estimators, which have appealing asymptotic properties, is the shrinkage estimators that are shrunk toward the data grand mean. That is,
Using quadratic loss function for these bivariate estimators, it is straightforward to see that
Therefore, the following theorem holds for (3.3).
Theorem 3.2.
For model (2.2), under the conditions C1-C3 and homogenous property for the correlation coefficients, If
Remark 3.1.
Here, it is important to note that if |ρi| → 0, the upper bound of (A.1), in the appendix, tends to become sharper. This means that under uncorrelated situation the asymptotic convergence rate increases in Theorems (3.1) and (3.2).
4. Simulation study
In this section, we carry out a simple simulation to study how our bivariate shrinkage estimates perform in comparison with EBMME (Empirical Bayes Method of Moments Estimator) and EBMLE(Empirical Bayes Maximum Likelihood Estimator) bivariate estimators defined below.
- •
Empirical Bayes method of moment estimators:
whereand the elements of - •
Empirical Bayes maximum likelihood estimators:
where the elements of
For our simulation study, we first derive samples for
- •
Scenario I: we assume a large correlation coefficient for each i = 1,2,…,N. That is
- •
Scenario II: we assume a moderate correlation coefficient,
- •
Scenario III: A weak correlation coefficient is considered in this scenario,
We also assume that θi are independently distributed according to
To measure the predictive power of different bivariate shrinkage estimators, we compute the limiting risk
| Sample Size | Method | Scenario I | Scenario II | Scenario III |
|---|---|---|---|---|
N = 50 |
Oracle | 0.3342 | 0.1021 | 0.0971 |
| SURE | 0.3343 | 0.1044 | 0.0978 | |
| EBMME | 0.4558 | 0.3322 | 0.2320 | |
| EBMLE | 0.4865 | 0.3413 | 0.2403 | |
N = 200 |
Oracle | 0.1947 | 0.0540 | 0.0097 |
| SURE | 0.1989 | 0.0553 | 0.0098 | |
| EBMME | 0.2271 | 0.0653 | 0.0187 | |
| EBMLE | 0.2430 | 0.0670 | 0.0188 | |
The risk of various bivariate shrinkage estimates
Table 1 clearly confirms that although all bivariate shrinkage estimates (SURE, EBMLE and EBMME) have good performance in comparison with the corresponding Oracle risk estimates, our bivariate SURE estimates do better in terms of the risk value under Scenarios (I)-(III). That is, as our theoretical result indicates, the performance of the SURE estimators approaches that of the oracle risk estimators.
5. Application to a real dataset
Educational performance is one of the principle measures for evaluation of an educational center, like a university. It is usually considered through two extreme groups of the students who have either excellent performance (with grade point averages between [17,20]) or poor performance (with grade point averages less than 12) in comparison with the third (moderate) group (with grade point averages between [12,17)). In the following, we use E, M, and P notations which stand for groups of students with Excellent, Moderate, and Poor performances. For a given department indexed by i, let Ei, Mi, and Pi denote the number of students at each group and let ni denote the number of total students in the corresponding department during the given semester. Whenever it is necessary to consider multiple semesters of educations, such as the two semesters in a given educational year, we will insert other subscripts, and use symbols such as Eji, Mji, and Pji, to denote the number of students with excellent, moderate, and poor performances and total number nij for department i (= 1,⋯,N) within semester j (= 1,2).
For data involving N departments over two semesters, we focus on two extreme groups E and P, which are known as educational outcome of each department, Tinto (2010), and assume that
For our purpose, we are interested in dealing with nearly bivariate normal variables such that a) having variances that depend only on the observed value of n and b) asymptotic performance of bivariate shrinkage estimators are robust with respect to plug-in estimates for the correlation coefficient. From Bartlett (1936, 1947), the standard variance-stabilizing transformations,
For more details on these transformations, see Brown (2008). It is well-known that these transformations have marginal variance-stabilizing properties. That is:
By applying Delta-method for the function arcsin
We would like to note that Lemma (3.1) holds for this correlation and the class of correlations given by (5.1). Furthermore, it is not difficult to numerically verify that the asymptotic performance of our proposed bivariate shrinkage estimators are robust with respect to a general class of the correlation between Y1 and Y2
Let’s look at Educational data, Table 2, for 24 departments at University of Qom over the educational year 2014. Our primary focus in this research is to evaluate the students’ performance in the second semester, at each department, when the parameters are estimated based on the first-semester data. Since we use the information of an already-completed educational year, we can then validate our bivariate estimation performance by comparing the estimated values with the real values for the second semester. To evaluate an estimator
| Department | Semester 1 | Semester 2 | ||||||
|---|---|---|---|---|---|---|---|---|
| E | M | P | Total | E | M | P | Total | |
| Statistics | 5 | 16 | 1 | 22 | 4 | 13 | 4 | 21 |
| Law | 28 | 21 | 2 | 51 | 25 | 22 | 4 | 51 |
| Mathematics | 5 | 18 | 8 | 31 | 4 | 13 | 12 | 29 |
| English literature | 5 | 29 | 9 | 43 | 9 | 18 | 14 | 41 |
| Arabic literature | 23 | 15 | 3 | 41 | 14 | 16 | 9 | 41 |
| Persian literature | 24 | 29 | 3 | 56 | 11 | 30 | 10 | 51 |
| Biology | 4 | 7 | 2 | 13 | 2 | 9 | 1 | 12 |
| Chemistry | 14 | 28 | 7 | 49 | 8 | 31 | 9 | 48 |
| Information | 16 | 16 | 1 | 33 | 23 | 8 | 1 | 32 |
| Economics | 9 | 21 | 6 | 36 | 3 | 22 | 11 | 36 |
| Education | 20 | 21 | 3 | 44 | 13 | 25 | 6 | 44 |
| Quranic Sciences | 23 | 3 | 1 | 27 | 17 | 8 | 2 | 27 |
| Computer Sciences | 6 | 23 | 6 | 35 | 3 | 16 | 14 | 32 |
| Jurisprudence | 32 | 15 | 0 | 47 | 38 | 7 | 2 | 47 |
| Philosophy | 23 | 8 | 4 | 35 | 23 | 5 | 3 | 31 |
| Physics | 6 | 27 | 6 | 39 | 3 | 20 | 15 | 38 |
| Business Management | 20 | 18 | 6 | 44 | 20 | 16 | 8 | 44 |
| Industrial Management | 27 | 4 | 0 | 31 | 19 | 12 | 1 | 32 |
| Architectural Engineering | 13 | 5 | 1 | 19 | 1 | 16 | 2 | 19 |
| Electrical Engineering | 23 | 26 | 1 | 50 | 12 | 33 | 5 | 50 |
| Industrial Engineering | 4 | 13 | 2 | 19 | 6 | 12 | 1 | 19 |
| Civil Engineering | 25 | 28 | 8 | 61 | 13 | 40 | 8 | 61 |
| Computer Engineering | 18 | 24 | 2 | 44 | 15 | 27 | 1 | 43 |
| Mechanical Engineering | 16 | 11 | 3 | 30 | 8 | 17 | 5 | 30 |
Number of students according to their educational performance and department of study at each semester over educational year 2014 in University of Qom
Table 3 summarizes the numerical results of our bivariate shrinkage estimators in comparison with the other competing bivariate shrinkage estimators. The corresponding TSE values are reported. Acceptable performance of our bivariate SURE estimators, among the other estimators, are shown by Table 3. To numerically investigate the robust performance of our bivariate shrinkage estimators, with respect to little changes in correlation coefficient, we present a plot of TSE versus c in (5.1). As Figure 1 illustrates, TSE values of two approaches EBMME and EBMLE always dominate the corresponding values of SURE even for fairly large value of c.
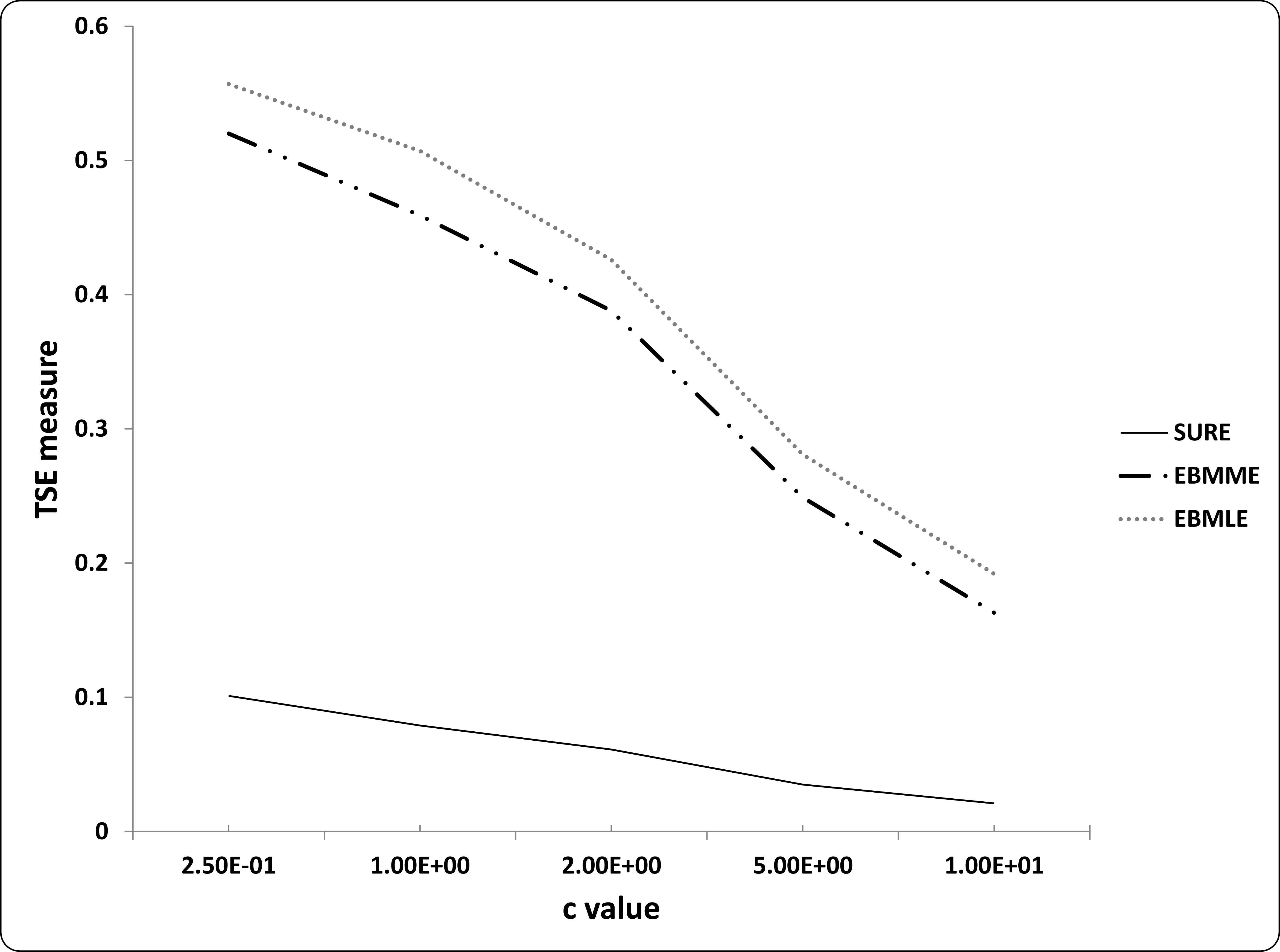
TSE against c values
| c | 0.25 | 1 | 2 | 5 | 10 |
|---|---|---|---|---|---|
| SURE | 0.101 | 0.079 | 0.064 | 0.035 | 0.021 |
| EBMME | 0.520 | 0.459 | 0.388 | 0.249 | 0.163 |
| EBMLE | 0.557 | 0.507 | 0.426 | 0.281 | 0.192 |
TSE for various c
Acknowledgements
I am grateful to Editor, Associate Editor and three referees for their constructive and insightful comments that helped greatly improve the quality of the paper.
Appendix
We first prove
For establishing the asymptotic results, the following conditions are required,
- C1)
For j = 1,2 and some δ > 0:
- C2)
- C3)
Let |μ1| ≤ maxt |Y1i|, and |μ2| ≤ maxt |Y2i|. Since the sensible shrinkage estimators would attempt to shrink toward locations that lie inside the range of the data, these assumptions are included for technical reasons to facilitate the proof. These conditions imply that
Proof of Theorem (3.1)
From (3.1), we have
The L2 convergence of the supΛ,μ |I1| and supΛ,μ |I2|, and L1 convergence of supΛ,μ |I2|, supΛ,μ |I3|, supΛ,μ |II2|, and supΛ,μ |II3| immediately obtain from Theorems (3.1) and (5.1) in Xie et al. (2012) for univariate case. The proof of two last expressions, which consider interaction between two random variables, is given below. Without loss of generality, we assume wherever it is needed, the summands are rearranged according to decreasing order of their coefficients
Under necessary conditions for correlation coefficients in Lemma (3.1)[iii], and using Lemma (2.1) in Li (1986), the last term is equal to
Let
Therefore, conditions (C1) and (C2) imply that
The same argument shows
Proof of Theorem (3.2)
Form (3.3) it is obvious that
For univariate L2 convergence of the supΛ |I1| and supΛ |II2|, L1 convergence of
Following the technique in the proof of Theorem (3.1), it is obvious to see that
Moreover,
Therefore, we have
The same results hold for
References
Cite this article
TY - JOUR AU - S.K. Ghoreishi PY - 2018 DA - 2018/06/30 TI - A class of Bivariate SURE estimators in heteroscedastic hierarchical normal models JO - Journal of Statistical Theory and Applications SP - 324 EP - 339 VL - 17 IS - 2 SN - 2214-1766 UR - https://doi.org/10.2991/jsta.2018.17.2.11 DO - 10.2991/jsta.2018.17.2.11 ID - Ghoreishi2018 ER -