
Parameter Estimation Using the EM Algorithm for Symmetric Stable Random Variables and Sub-Gaussian Random Vectors
- DOI
- 10.2991/jsta.2018.17.3.4How to use a DOI?
- Keywords
- EM algorithm; Markov Chain Monte Carlo; Symmetric α-stable distribution (SαS); Sub-Gaussian α-stable distribution
- Abstract
Applying some well-known properties of the class of symmetric α-stable (SαS) distribution, the EM algorithm is extended to estimate the parameters of SαS distributions. Furthermore, we extend this algorithm to the multivariate sub-Gaussian α-stable distributions. Some comparative studies are performed through simulation and for some real data sets to show the performance of the proposed EM algorithm compared with some well-known methods including empirical characteristic function, maximum likelihood, and sample quantile in the univariate and multivariate cases.
- Copyright
- © 2018, the Authors. Published by Atlantis Press.
- Open Access
- This is an open access article under the CC BY-NC license (http://creativecommons.org/licences/by-nc/4.0/).
1. Introduction
The theory of stable (or α-stable) distributions has received much interest in different fields as physics, economics, finance, and telecommunications since this class of distributions can account for tails thickness, peak value, and skewness. The empirical density function of many real life data sets found in aforementioned fields has heavy tails so that normal models are clearly inappropriate. For comprehensive accounts of applications of stable distributions, we refer the readers to [13], [19], [20], [26], [28], and [31]. There are several parameterizations for characteristic function of a stable random variable. In the following, Definition 1.1 gives the S1 parameterization which is more popular.
Definition 1.1.
The characteristic function of a stable random variable, say X, has the form
A stable distribution is described by four parameters: index of stability α ∈ (0, 2] (also called tail parameter), skewness parameter β ∈ [−1, 1], scale parameter σ ∈ IR+, and location parameter μ ∈ IR. We write S(α, β, σ, μ) to denote a stable distribution in this parameterization. If β = 0, it would be the class of symmetric α-stable (SαS) distributions. We assume throughout that β = 0, in which case φX(t) = exp{−|σt|α}.
In the following, we mention three well-known methods for estimating parameters of this family. The maximum likelihood (ML) estimation for stable distributions approximated theoretically by [9] and evaluated numerically by [21]. Although such approaches lead to some efficient estimates, both involve numerical complexities. The software proposed by [21] called STABLE uses a spline interpolation of stable densities for his numerical method. This package estimates all four parameters of a stable distribution efficiently when α ≥ 0.4. The empirical characteristic function (CF) method is suggested in [12]. As another approach, sample quantile (SQ) technique proposed in [15] presents consistent estimators for all parameters based on five specific sample quantiles.
Definition 1.2.
Let Y be a d-dimensional sub-Gaussian α-stable (sub-Gaussian SαS) random vector. Then, the characteristic function of Y can be written as
Computing the maximum likelihood (ML) estimation of a sub-Gaussian SαS distribution directly by maximizing the log-likelihood of sub-Gaussian SαS density, known as full MLE in the literature, has been performed in [24]. Finding the full MLEs is computationally expensive. So, a projecting method is suggested in which a sub-Gaussian SαS random vector is projected into different directions. Then since each component follows a univariate SαS distribution, parameters of each component are estimated using methods such as ML, CF, and SQ which developed for the univariate case, [24]. The obtained estimates in such a way are known as projected estimations and these methods are called the projected ML, CF, and SQ, respectively. In the projection approach, the dispersion matrix of a sub-Gaussian SαS distribution is estimated term-by-term, and so there is no guarantee that the reconstructed matrix to be positive definite. The issue with Σ possibly not being positive definite is addressed in [24]. Also, the projected ML approach still is applicable only for α ≥ 0 4.
Although the proposed EM algorithm in this work is more computationally expensive than the ML, CF, and SQ methods, the following reasons motivate us to propose it. Contrary to the ML approach, it works satisfactorily for all ranges of in the univariate and multivariate cases. Also, it gives better performance than the ML, CF, and SQ approaches when α is near one. In the multivariate case, it estimates all entries of dispersion matrix simultaneously so that the estimated dispersion matrix is always positive definite. The proposed EM algorithm can be developed for modelling the mixture of SαS distributions. This advantage of the proposed EM algorithm received much interest in robust mixture modelling since SαS is a heavy tailed distribution. Modelling the mixture of sub-Gaussian SαS distributions suggested in [29] using Gibbs sampling. We can develop the introduced EM algorithm in this work for modelling the mixture of sub-Gaussian SαS distributions that is faster than the Gibbs sampling approach.
This paper is organized as follows. Some preliminaries are given in Section 2. In Section 3, we propose the EM algorithm for estimating the parameters of a univariate SαS distribution. The methodology given in Section 3 is developed for the sub-Gaussian SαS distribution in Section 4. In Section 5, some simulation studies are considered to compare the performance of the presented EM algorithms in the univariate and multivariate cases versus the ML, CF, and SQ approaches. Our method will be applied to some sets of real data in this section. We conclude the paper in Section 6 with a summary of the contributions of this work.
2. Preliminaries
2.1. EM algorithm and extension
Missing or incomplete observations frequently occurs in the statistical literature. The EM algorithm, introduced in [7], is a popular inferential tool for such a situation. The application of the EM algorithm also includes cases with latent variables or models with random parameter provided that they are formulated as a missing value problem. For a brief description of EM methodology, let x = (x1,…, xn) denote the complete observations follow the density function f(x|θ). We denote x = (y, z), where z denotes missing samples and y accounts for the available observations, [16]. The computation and maximization of
- 1.
Expectation (E) step: Compute Q(θ|θ(t)) at t-th iteration.
- 2.
Maximization (M) step: Maximize Q(θ|θ(t)) with respect to θ to get θ(t+1).
The E and M steps, in above, are repeated until convergence occurs. When the M step of the EM algorithm becomes analytically intractable, we follow the idea of implying this step using a sequence of conditional maximization, known as the CM step. The resulting procedure is known as the ECM algorithm, [18]. A faster extension of the EM algorithm is the so-called ECME algorithm introduced in [14]. It should be noted that all the EM, ECM and ECME have the same E step. The ECME algorithm works by maximizing the constrained Q(θ|θ(t)) via some CM steps and maximizing the constrained marginal likelihood function, [1]. Sometimes implementation of the EM algorithm is difficult. In this situation, another extension of this algorithm, called the stochastic EM (SEM) is useful, [2], [3], and [4]. Each SEM works by simulating missing data from conditional density f(zi|θ(t), yi); for i = 1,…, n and replacing it into the complete likelihood function. Then, we apply the EM algorithm for the pseudo-complete sample where
- 1.
Stochastic imputation (S) step: Impute the simulated missing values and constituting the pseudo-complete log-likelihood function at t-th iteration.
- 2.
Maximization (M) step: Find a θ, say θ(t+1), which maximizes the pseudo-complete log-likelihood function at t-th iteration.
The S and M steps, in above, are repeated until convergence occurs.
2.2. Properties of symmetric and positive stable laws
Suppose that Y1 and Y2 > 0 are independent stable random variables, Y1 ~ S(α1, 0, σ, 0) and Y2 ~ S(α2, 1, (cos(πα2/2))1/α2, 0) for 0 < α2 < 1. Then,
3. EM Algorithm for SαS
In this section, we introduce two approaches to extend the EM algorithm for SαS distribution. Presenting the first algorithm in Subsection 3.1, we consider a computational method for the first approach in Subsection 3.2. The second approach is presented in Subsection 3.3.
3.1. The first approach
Let y = (y1,…, yn) be a random sample from a SαS distribution. Refer to (2.3) and consider p = (p1,…, pn) as the vector of missing observations. The complete data likelihood Lc(Θ) is factored into the product of the marginal densities of Pi and the conditional densities of Yi given Pi. So, the complete data log-likelihood can be written as
- •
E step: Given current estimation of Θ, Θ(t), compute
- •
CM step: Update θ(t) as θ(t+1) by maximizing Q(Θ|Θ(t)) with respect to θ to obtain
- •
CML step: Update value of α(t) by maximizing the marginal log-likelihood function as
where fY(.) is the SαS density function. Under the methodology that we follow here, the CML step itself contains an SEM algorithm (This is because the density function of SαS random variable has no closed-form expression). In the following, two steps of the SEM are described. - •
The first step of CML: Let E1, E2,…, En be independent exponentially distributed random variables with mean one. At (t + 1)-th iteration, assume that μ(t+1) and σ(t+1) are known. Let Y′i = (Yi − μ(t+1))/σ(t+1) and
Considering w1,…, wn as missing observations, the complete data likelihood Lc(Θ) is factored into the product of the marginal densities of Wi and the conditional densities of Y″i given Wi. So, the complete data log-likelihood can be written as - •
The second step of CML: Simulate the vector w = (w1,…, wn) from conditional distribution of Wi given y″i; for i = 1,…,n, and Θ(t) using the Monte Carlo method at the m-th cycle of the S step of the SEM.
- •
The third step of CML: Substitute w in (3.3) and maximize it with respect to α to find α(t+1). Then, repeat the algorithm from E step for M times to obtain Θ(t) as
where M0 is burn-in size. Maximizing (3.3) with respect to α in each cycle is equal to computing the ML estimation of a Weibull distribution with shape parameter α.
3.2. Computational considerations of the first approach
In the E step of the algorithm, we need to calculate the conditional mean
As the CML step itself contains a SEM algorithm, simulation from conditional distribution of Wi given
- 1.
Simulate a sample from a Weibull distribution, say wi, with shape parameter α(t+1)and scale unity.
- 2.
Generate a sample from a uniform distribution
- 3.
If
While we expect that the rejection sampling works satisfactorily, it faces with the problem when |y″i| is so large. In this case that the machine sets the quantity
3.3. The second approach
The first approach works efficiently, but it can be improved to reduce computational complexity by relaxing some CM steps for computing μ(t+1) and σ(t+1). This approach significantly reduces the processing times for implementing the EM algorithm. In the CM step of the second approach, we only update μ while both σ and α are updated through the SEM in the CML step. Like the previous approach, the location parameter is updated through (3.1). Let E1, E2,…, En be independent exponentially distributed random variables with mean one. At (t + 1)-th iteration of the first step of the CML, assume that μ(t+1) is known. Let Y′i = (Yi − μ(t+1)) and
4. EM Algorithm for the Multivariate case
Let Y denotes a sub-Gaussian SαS random vector as defined in (1.2). The representation
Corollary 4.1.
The updated dispersion matrix Σ(t+1) in (4.4) is positive definite.
4.1. Computational considerations
At (t + 1)-th iteration, updating μ(t) in (4.2) needs computing
- 1.
Simulate a sample from a Weibull distribution, say wi, with shape parameter α(t+1) and scale unity.
- 2.
Define
- 3.
If
5. Simulation study and Real Data Analysis
This section has five parts. In the first part, we analyze the performance of the proposed EM algorithm compared with other estimators in the univariate case through a simulation study. In the second part, we follow the analyses for the performance of the proposed EM algorithm using real data. Simulation studies in the bivariate case are performed in the third subsection. The fourth subsection is devoted to real data analysis for a bivariate case. Simulation studies in three-variate and higher dimensions are given in the fifth subsection. The set of real data used in the univariate and multivariate cases is 9 years of daily returns of 22 major worldwide market indices, which consists of 2535 observations from 1/4/2000 to 9/22/2009. These indices are from four different areas including America (S&P500, NASDAQ, TSX, Merval, Bovespa and IPC), Europe and Middle East (AEX, ATX, FTSE, DAX, CAC40, SMI, MIB and TA100), and East Asia and Oceania (HgSg, Nikkei, StrTim, SSEC, BSE, KLSE, KOSPI and AllOrd). This data set is available at the website of Yahoo finance, [8]. For simplicity, hereafter, we call this data set WMI (Worldwide Market Indices).
5.1. Simulation study in univariate case
We compare the performance of the ML, SQ, CF, and the EM methods for estimating the parameters of SαS distribution through simulation. Comparisons are based on square root of the mean-squared error (RMSE) criterion. In the simulation, the RMSE was computed for sample sizes of n = 200, 500, and 1000. The number of replications is N = 1000. The parameters were selected as: μ = 0, σ = 0 5, 1, 2, and α = 0.4, 0.6, 0.8, 0.9, 1.1, 1.2, 1.4, 1.6, 1.8, 1.9. The plots of the computed RMSE for all estimators are shown in Figures 1–3 . It should be noted that the estimation results for the evaluated ML approach (Nolan’s Method [21]) are not reliable for α < 0.4 and so are not shown in the Figures 1–3. The smoothed version of the actual values plotted in these figures is obtained using the lowess package (see [6]) with the following settings: the smoothing span is considered to be 2/3, the number of iterations is 3, and the speed of computations is determined by 0.01th of the range of the α values.
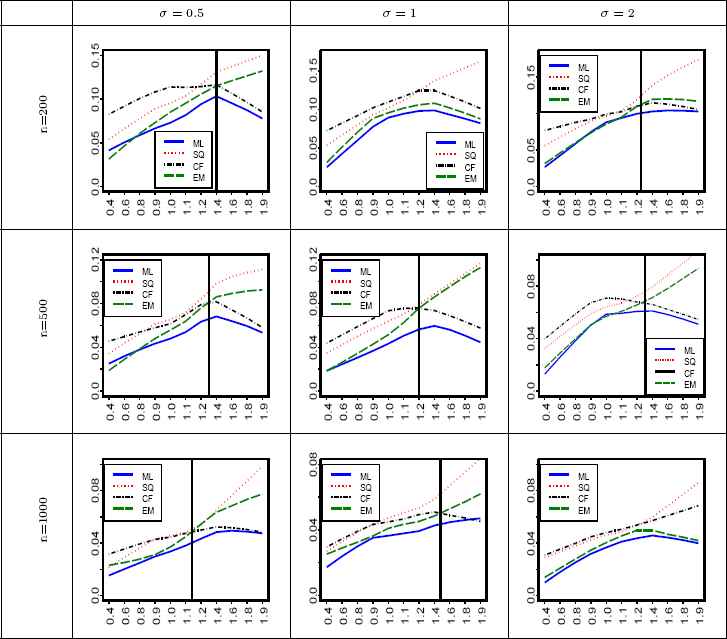
RMSE of
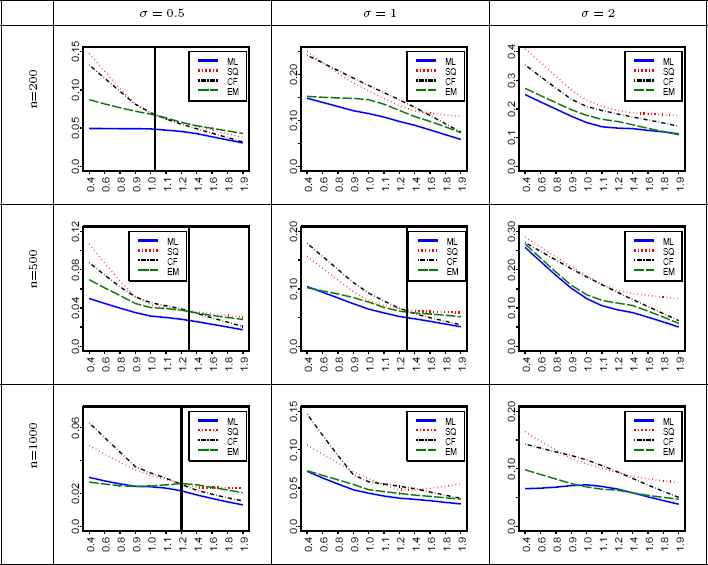
RMSE of
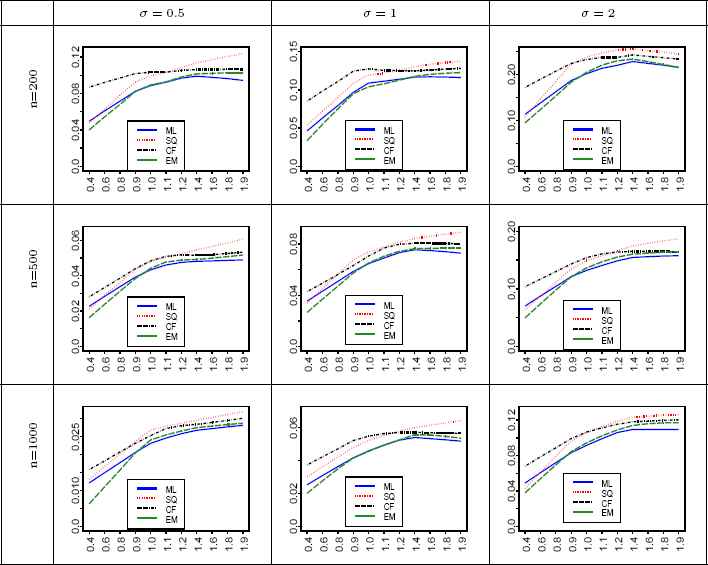
RMSE of
In each sub-figure of Figures 1 - 3, the vertical line indicates that the proposed EM algorithm works better than the CF and SQ methods for those α lie in the left side of the line. When the EM algorithm always works better, such a line is not shown. By considering the location parameter as zero, the following results are obtained from simulation and show how RMSE of the estimators varies in terms of σ, α and n:
- 1.
- 2.
EM-based
- 3.
RMSE of the EM-based
- 4.
We know that the ML method gives the efficient estimation particularly when sample size gets large. But, sometimes the EM-based
- 5.
RMSE of all estimators decreases by increasing the sample size n.
Along with the simulation, we investigate the execution time for different sample sizes and scale parameters in the univariate case. The results are given in Table 1. For this, all runs are performed on a machine with 3.5 GHz Core(TM) i7-2700K Intel(R) processor and 8 GB of RAM. It should be noted that implementing of the ML, CF, and SQ approaches, with settings given in Table 1, takes less than 0.5 second.
| Scale parameter | |||
|---|---|---|---|
| Sample size | σ=0.5 | σ=1 | σ=2 |
| 500 | 30(62) | 26(64) | 22(62) |
| 1000 | 70(127) | 55(122) | 43(124) |
| 5000 | 334(627) | 283(639) | 223(621) |
Average of the execution time in seconds for 50 runs of the EM algorithm when it is applied to SαS distribution. The written program run on a 3.5 GHz Intel processor Core(TM) i7 using a 8 GB RAM. Note that values outside (inside) of parentheses are obtained for α = 0.5 (α = 1.5). We set M = 120, M0 = 70 for implementing the EM algorithm.
5.2. Real data analysis in the univariate case
For real data application, we select the Bovespa (São Paulo Stock Exchange), CAC40 (Bourse de Paris) and DAX (German Stock Index) indices from WMI data set. The empirical distributions of these three sets of data show symmetric pattern around the origin whose tails are heavier than the normal model. We apply the ML, CF, SQ, and EM methods to estimate the parameters of the fitted stable distributions. It should be noted that the sample median is used as an initial value for the location parameter to implement the EM algorithm. Initial values for the tail and scale parameters are obtained by applying the method of the logarithmic moment. This approach, for a symmetric stable distribution, estimates the parameters using the first and the second order moments of the logarithm of a zero-location symmetric stable random variable Y, i.e. L1 = E(log |Y|) and L2 = E(log |Y| − L1)2, respectively. Assuming that data, after subtracting from the sample median, follow a zero-location symmetric stable distribution, the parameters α and σ are estimated by equating the sample logarithmic moments to the quantities L1 and L2, [20] and [32]. Figure 4 displays cycles of the EM algorithm for M = 120 and M0 = 70.
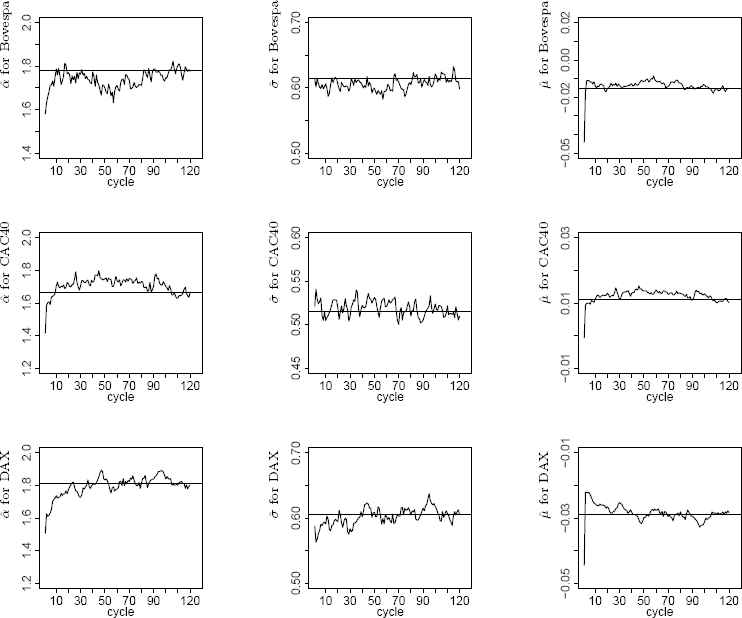
Estimated values of α, σ, and μ with M = 120 cycles each with n = 2535 samples for Bovespa, CAC40 and DAX indices selected from WMI data set.
Estimated parameters, along with the Kolmogorov-Smirnov (K-S) and Anderson-Darling (A-D) test statistics are given in Table 2. More analyses reveal that stable model captures the general shape of the empirical histogram well and the main difference between fitnesses occurs at the origin for the height of peaks. As it is seen, EM algorithm gives satisfactory results.
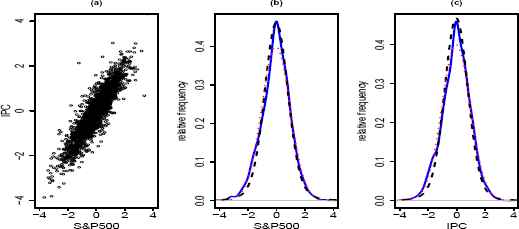
Scatterplot of the IPC index versus S&P500 index (a) shows that distribution of points on a plane is roughly elliptical. Points in scatterplot are a number of n = 2535 daily returns from April 1, 2000 through September 22, 2009. Marginal density plots of the S&P500 (b) and IPC (c) show that the stable distribution (black dashed line) provides a better fit than the normal (red dotted line) distribution. Blue solid line is the fitted empirical density.
| Bovespa | CAC40 | |||||||
| Parameters | ML | CF | EM | SQ | ML | CF | EM | SQ |
| α | 1.8616 | 1.8976 | 1.78017 | 1.7544 | 1.7074 | 1.7898 | 1.6629 | 1.6076 |
| β | −0.5908 | −0.828 | — | −0.3021 | 0.0578 | 0.3089 | — | 0.0974 |
| σ | 0.6407 | 0.6431 | 0.6151 | 0.6171 | 0.5461 | 0.5561 | 0.5148 | 0.5287 |
| μ | −0.0572 | −0.0541 | −0.0155 | −0.0805 | 0.0222 | 0.0487 | 0.0111 | 0.0193 |
| K-S | 0.0314 | 0.0302 | 0.0305 | 0.0388 | 0.0237 | 0.0251 | 0.0192 | 0.0191 |
| A-D | 1.7552 | 1.9720 | 2.4888 | 2.5601 | 1.2075 | 2.1783 | 1.6430 | 1.0461 |
| DAX | ||||||||
| Parameters | ML | CF | EM | SQ | ||||
| α | 1.8541 | 1.8856 | 1.8140 | 1.6642 | ||||
| β | −0.2978 | −0.508 | — | −0.1368 | ||||
| σ | 0.6401 | 0.6378 | 0.6048 | 0.6029 | ||||
| μ | −0.0507 | −0.0550 | −0.0289 | −0.0493 | ||||
| K-S | 0.0268 | 0.0251 | 0.0220 | 0.0171 | ||||
| A-D | 1.9657 | 2.1389 | 2.1374 | 1.1655 | ||||
Estimation results for the return of Bovespa, CAC40, and DAX data through the ML, SQ, CF, and EM approaches applied to the data.
5.3. Simulation study in bivariate case
Estimating the parameters of a sub-Gaussian SαS distribution is computationally expensive, [24]. Usually, the parameters of this distribution are estimated using projection method. Hereafter, we write ML, CF, and SQ for the projected ML, CF, and SQ methods, respectively. In the following, we perform a simulation based on a sample of size n = 500 to measure the performance of the ML, CF, EM, and SQ approaches in modelling a bivariate sub-Gaussian S S distribution. For this, we set α = 1.5, 1.7, 1.9, μ = (μ1, μ2)T = (0,0)T, and dispersion matrix
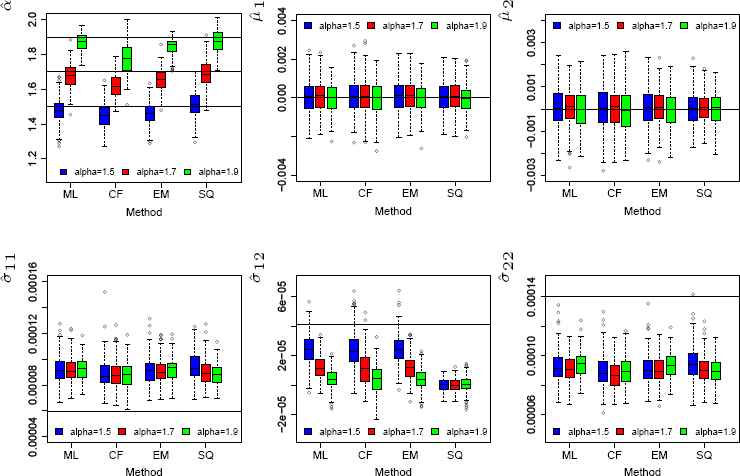
Boxplot of the ML, CF, EM, and SQ estimations for α, μ = (μ1, μ2)T, and entries of Σ when n = 500 vectors generated from a bivariate sub-Gaussian SαS with α = 1.5, 1.7, 1.9, μ = (μ1,μ2)T = (0,0)T, σ11 = 0.000059552, σ12 = 0.000040783, and σ22 = 0.000139861. In each sub-figure, horizontal line denotes the real value of parameter. Each boxplot is constructed based on N = 250 runs. The used color scheme under each method for boxplots is: blue, red, and green for α = 1.5, 1.7, and 1.9, respectively.
5.4. Real data analysis in bivariate case
Here, we apply ML, SQ, CF, and EM methods to S&P500 and IPC indices selected from WMI data set. The empirical distribution of both S&P500 and IPC indices show a symmetric pattern around the origin. The scatterplot shown in Figure 5 is roughly elliptical contoured. Furthermore, estimated tail parameters after fitting a stable distribution to S&P500 and IPC indices through the ML approach are 1.9003 and 1.9143, respectively, which are assumed to be equal. Thus, the assumption that X = (S&P500, IPC)T follows a sub-Gaussian SαS distribution is acceptable, [23]. The results of estimating parameters through ML, CF, EM, and SQ methods are shown in Table 3. The log-likelihood values indicate that the EM algorithm gives better performance than the CF and SQ approaches.
| Parameters | ||||
|---|---|---|---|---|
| Method | α | ∑ | μ | Log-likelihood |
| ML | 1.9073 |
|
|
−4967.706 |
| CF | 1.9530 |
|
|
−4978.067 |
| EM | 1.7116 |
|
|
−4975.581 |
| SQ | 1.8179 |
|
|
−5176.572 |
Estimation results or the return of (S&P500, IPC) when the ML, CF, EM, and SQ approaches are applied to the data.
5.5. Analysis in higher dimensions
In this subsection, firstly we perform a simulation to compare the performance of the ML, CF, EM, and SQ methods where a sample of size n = 1500 is generated from three-variate sub-Gaussian SαS distribution. For this purpose, the considered settings are: α = 1.86, μ = (μ1, μ2, μ3)T = (0, 0, 0)T , and
For three-variate case, results of the simulation are displayed in Figure 7 where each boxplot is based on 250 runs. If we define the length of each box as a performance criterion, it follows that the EM algorithm works better than the SQ method in all cases. The performance of the EM and CF approaches is almost the same except in the case of estimating α where the EM algorithm performs much better than the CF method. In the case of case of thirty-dimensional, implementing the EM algorithm takes 303 seconds when M = 200 and M0 = 150. To avoid unnecessary details, we only focus on estimating the location parameter and diagonal entries of the dispersion matrix using the EM and ML methods. The result for estimating these parameters are given in Figures 8-9, respectively. As it is seen, the EM algorithm gives results close to the ML approach for estimating diagonal entries of the dispersion matrix. The results of simulation show that the computational cost increases as dimensions increase but differences are not significant. For example, the execution time for implementing the EM and ML methods are given in Table 4. For this, we generated n = 1000 random vectors of a sub-Gaussian SαS distribution.
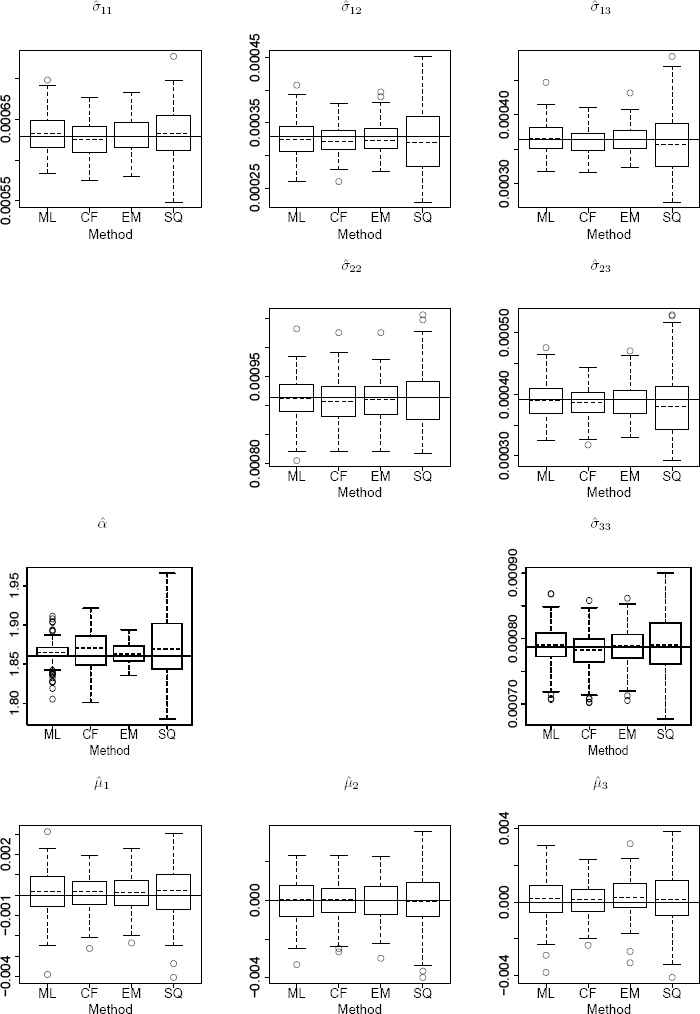
Boxplot of the ML, CF, EM, and SQ estimations for α, μ = (μ1, μ2, μ3)T, and entries of Σ when n = 1500 vectors generated from a three-variate sub-Gaussian SαS with α = 1.86, μ = (μ1, μ2, μ3)T = (0, 0, 0)T, σ11 = 0.0006293, σ12 = 0.0003289, σ13 = 0.0003643, σ22 = 0.0009133, σ23 = 0.0003921, and σ33 = 0.0007871. In each sub-figure, horizontal line denotes the real value of parameter. Each boxplot is constructed based on N = 250 runs.
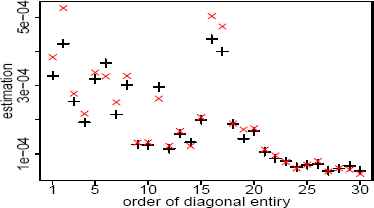
Estimated values for diagonal entries of dispersion matrix when the EM and ML methods are applied to 30 indices of Dow Jones data. The signs × and + correspond to the EM and ML methods.
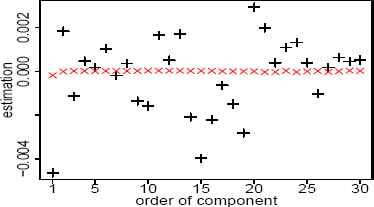
Estimated values for location parameter when the EM and ML methods are applied to 30 indices of Dow Jones data. The signs × and + correspond to the EM and ML methods.
| d | α =1.5 | α =1 |
|---|---|---|
| 5 | 201(1.2) | 185(0.6) |
| 10 | 222(3.3) | 200(3.5) |
| 20 | 230(7.6) | 223(7.8) |
| 50 | 275(42) | 258(40) |
| 100 | 456(193) | 389(173) |
Average of the execution time in seconds for 50 runs of the EM and ML methods where they are applied to a d-dimensional sub-Gaussian SαS distribution. The written program run on a 3.5 GHz Intel processor Core(TM) i7 using a 8 GB RAM. During simulation, we set M = 200, M0 = 150, and Σ is a positive definite matrix whose eigenvalues are randomly generated from a uniform distribution on (0, 2). The value inside of the parentheses corresponds to the ML method.
6. Concluding remarks
We propose an EM algorithm for estimating the parameters of SαS and sub-Gaussian SαS distributions. For SαS case, the performance of the proposed EM algorithm is compared with known approaches such as ML, CF, and SQ through a comprehensive simulation study. The comparisons are based on square root of the mean-squared error (RMSE). It follows that the proposed EM algorithm is a good competitor for the ML, CF, and SQ methods. Furthermore, in the univariate case, its performance is proved using three sets of real data. For the sub-Gaussian SαS case, the performance of the proposed EM algorithm is investigated via simulation and real data modelling. To avoid unnecessary details, we consider only two-, three-, and thirty-dimensional cases. The simulation reveals that the proposed EM algorithm provides satisfactory performance. Particularly, in two-dimensional case, it gives better performance than the CF and SQ methods in modelling a set of real data. The proposed EM algorithm has some advantages over other methods studied in this work. Among them we mention: 1- it works for all ranges of parameters. 2- In the multivariate case, it can estimate all entries of dispersion matrix simultaneously so that the estimated dispersion matrix is always positive definite. 3- it motivates further researches for many other distributions where dividing by an auxiliary random variable in the CML step, simplifies the M step of the EM algorithm. This idea can be applied for exponential power distribution. 4- it outperforms the CF and SQ methods in estimating the location parameter when is near to one. 5- it can be developed for modelling the mixture of SαS distributions. This advantage of the proposed EM is a privilege as the evaluated ML, SQ and CF are not applicable to the mixture models. As possible future works, we are developing the proposed EM algorithm to estimate parameters of a stable, mixture of SαS, and mixture of sub-Gaussian SαS distributions.
Acknowledgments
The authors would like to thank the anonymous reviewers for their constructive comments that greatly improved the paper. The authors would also like to especially thank Prof. John P. Nolan for his suggestions and encouragements throughout this work. The source code written in ℜ package for implementing EM algorithm is freely available from corresponding author on request.
References
Cite this article
TY - JOUR AU - Mahdi Teimouri AU - Saeid Rezakhah AU - Adel Mohammadpour PY - 2018 DA - 2018/09/30 TI - Parameter Estimation Using the EM Algorithm for Symmetric Stable Random Variables and Sub-Gaussian Random Vectors JO - Journal of Statistical Theory and Applications SP - 439 EP - 461 VL - 17 IS - 3 SN - 2214-1766 UR - https://doi.org/10.2991/jsta.2018.17.3.4 DO - 10.2991/jsta.2018.17.3.4 ID - Teimouri2018 ER -